Author: @deeeeeet, Engineering head of Developer Productivity Engineering
Developer Productivity Engineering Camp (“Camp” is a unit and a term we use internally at Mercari to logically group the related teams) is a division which is mainly responsible for the entire Mercari group’s base infrastructure and DevOps toolings and services. It consists of multiple teams and works on multiple initiatives to keep the Mercari group’s product reliable, secure, and scalable.
We’re working on many interesting projects but we didn’t have much chance to show them outside recently. So we decided to write a series of blog articles by all teams in the Camp and output what we are doing. In this blog series, we will introduce the teams in the Camp and recent projects teams are working on. I hope some articles catch your eyes and are beneficial to your work.
Before going to the series, in this blog post, I would like to introduce the Developer Productivity Engineering Camp itself: its responsibilities and mission, long-term directions. In addition to that, and, at the end of the post, there is a idex of all posts. You should be able to use it to find articles you want to read.
Developer Productivity Engineering Camp
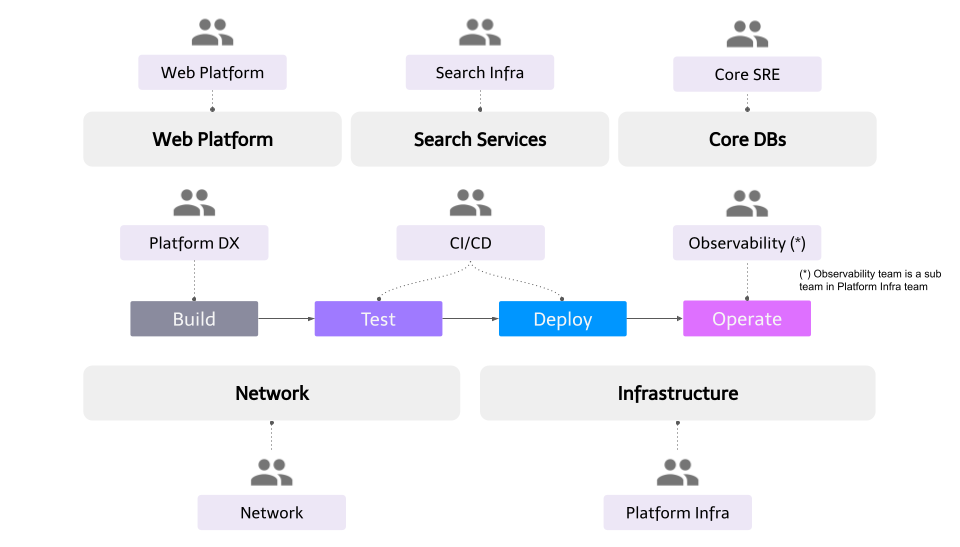
Developer Productivity Engineering (DPE) Camp consists of the following 8 teams:
- Platform Developer Experience (DX) team: Working on improving the developers experience by providing better abstraction and automated workflows
- Platform Infra team: Working on the base infrastructure operations as the cloud (GCP & AWS) and Kubernetes admin, as well as building the observability platform
- CI/CD team: Providing testing infrastructure, toolings, and the delivery system to make service delivery faster and more reliable
- Network team: Responsible for end-to-end network infrastructure from the edge (CDN) to the cloud & service mesh (Istio) and physical data centers
- Microservices SRE team: Providing embedded SRE support to the product team to improve service reliability. And spreading SRE practices to the entire organization so that they can work reliability work without SREs
- Search Infra team: Providing search as a service to Mercari group
- Web Platform team: Providing web microservice platform as a service for web products in mercari group
- Core SRE team: Managing core large scale database for the monolith API and related infrastructures
(See more details on How We Reorganize Microservices Platform Team)
These teams have their own mission and responsibilities (the details of each team’s mission and responsibilities will be described in the upcoming blog posts) and work on their goals but, at the high level, as a Camp, we have the following 2 main responsibilities and missions:
- Provide the reliable, secure, and scalable infrastructure
- Provide the best developer experience to deliver products faster and easier
Each team has different interaction modes (see Team Topologies) (e.g., while platform DX is working with X-as-a-Service, Microservices SRE works by Collaboration), but all teams share the same main customer: the product team. By supporting the product team to develop great features, we indirectly deliver our value to the Mercari customers. We are not only providing the base infrastructure and tooling but also ensuring the developer experience and accessibility of them which is potentially very complex for the product team. As said in multiple teams’ missions, we are working not only for Mercari but also for other companies in the Mercari group like Merpay as well.
Same as mission, each team has its own roadmap and projects but, at the high level, we have the following 4 main directions to working on:
- Harden platform security
- Improve developer activity visibility
- Developer Experience Enhancement
- Scale and modernize infrastructure
Last year, we had a large security incident caused by Codecov vulnerability. From its retrospective, we found out many fundamental improvements on our platform. Even before that, security was one of the most important priorities for us but, after that, we kicked many initiatives as the highest priority and started working on many improvements: moving forward to zero-touch production and keyless authentication everywhere, rebuilding CI/CD systems from scratch, or strengthening cloud governance.
For platform engineering, its product decision i.e., deciding what problem to be solved next, is one of the most important things. To do it better, collecting developer activity metrics e.g., Deploy per Developer per Day (See Accelerate), is very important (It’s also true for the upper-level leadership to do good decision-making of the engineering direction or the product team understand its potential improvements area). We’ve been working on this for a while but now we’re enhancing it and trying to get better visibility with the ability to drill down the details.
I will explain details in the Platform DX team’s introduction post later but the importance of enhancing developer experience is increasing. By reducing the frictions to the toolings or hiding the complexity of underlining complex infrastructure, product teams can focus on the product development itself and deliver value faster to our customers. We provide the fundamental components and tooling to develop the service but they expose too many complex low-level details or some are not well integrated with each other (workflow issue). To solve these issues, we are working on introducing more abstractions and a unified workflow process and experience across the toolings.
We’ve been working on Cloud migration and infrastructure modernization for a long time. As described in this blog post, most of the core systems were migrated to Tokyo from Hokkaido (previous DC we used) to integrate well with systems on Google Cloud in Tokyo. But still, many small systems are remaining and not all systems are in the Cloud. We are continuously working on cloud-native migration. Not only that, “scalability” is very critical. To consider future business expansion, we are investigating multi-cluster and multi-regional architecture.
The details of these projects will be described in further posts! Please check the index.
Index
The following is title, and author. It starts today and ends on 2022-02-24. We will release new articles every day (excep weekend)! They will be replaced with the link to the article and this will be the index of this blog series.