
こんにちは。メルカリで SRE として働いている shmizumo です。
本記事では、 MicroservicesSREチームが実際にEmbedded先でどのような改善を行っているかをいくつか紹介したいと思います。
メルカリの MicroservicesSRE チームについて詳しくはEmbedded SRE at Mercariをご参照ください。
Embedded先について
私は2021/05にメルカリに入社しました。最初(2021/07〜2021/12)はItemチームに、現在(2022/01〜)は Mercari APIチームに参加しています。Embedded先ではon-call担当にも参加しています。
ItemとMercari APIは以下のようなサービスです。
Item
メルカリにある商品を管理しているマイクロサービス。Goで書かれており、多い時間帯には80k 程度の rpsがあります。多くのアクセスはシンプルなGetリクエストですが、多くのサービスから依存されるとても重要なサービスです。
Itemチームとしては商品画像をs3にアップロードするPhotoというマイクロサービスも担当しています。
Mercari API
メルカリがマイクロサービス化を進める前からあるモノリスなAPIサービスで、PHPで書かれています。多くの機能はマイクロサービスに移りましたが、現在でも重要な機能が残っており、複数のチームが開発を行っています。
Embedded先での取り組みについて
以下では上述したEmmbeded先にて自分が取り組んできたことについていくつか紹介します。
1. ItemサービスのSLI/SLOの可視化
メルカリでは各マイクロサービスのSLOは決まっていますが、SLOをどの程度活用できているかについては各マイクロサービス毎に異なっています。ItemチームではSLOのグラフなどは用意されておらず、あまり利用できていない状況でした。そのためEmbeddedされて最初に可視化を行いました。
SLOやErrorBudgetについて詳しくはThe Site Reliability WorkbookのImplementing SLOsを御覧ください。
可視化には、メルペイのSREチームが開発を行っているSLO Dashboardの導入をしました。以下はこの仕組みによって生成されたError Budgetを可視化してるグラフです。

SLO Dashboardを導入したことにより大きく2つの方法でSLOを活用することができるようになりました。
まず、Error Budgetをリリースの判断材料として利用し始めました。リリース前にError Budgetsを確認することでError Budgetが枯渇している場合に大きな変更を含むリリースをしないといったことが可能になりました。
またこのSLO Dashboardでは3ヶ月前までのError Budgetが確認できるため、クォータ毎にそのクォータではどういう大きな障害(Error Budgetの消費)があったかということを振り返る事もできるようになりました。
他にもSLOの利用方法の改善のみではなく、SLIの追加なども行いました。Itemサービスは商品情報が追加・更新された際に、検索用Indexを更新するという非同期の処理を持っています。元々の監視としては非同期処理のqueue数の監視がありました。この監視は非同期処理全体が失敗している状況を検知するためには有効ですが、1つ1つの処理の速度の悪化などには気づきにくいという問題があります。
そのため、よりユーザ体験に近い指標を見るために、”商品が更新されてから検索Indexが更新さるまでの時間”をメトリクスで取得できるようにし、SLOとして監視するようにしました。
2. ItemサービスへのIstioの導入
メルカリではIstioをサービスメッシュとして利用しています。ただ導入作業はマイクロサービスチームに任せられています。Istioを導入することでサービス間通信の信頼度を高めることができるので、MicroservicesSREチームとして、Istioの導入を進めました。
導入を進める上での懸念点は、Itemサービスはリクエスト数がとても多いマイクロサービスでありistio-proxyコンテナにどれくらいのリーソスが必要かわからないということでした。そのため、最初は1つのPod(Canary Pod)だけで、CPU・メモリを多めに設定したistio-proxyコンテナを起動するようし、そのPodを1日起動させ実際に本番環境でどの程度のリソースが利用されるかを確認しました。
また、istio-proxyのコンテナを起動することでPodがマルチコンテナになりますが、HPAのCPU利用率にはPod単位のものが用いられます。この場合、1つのPodのCPU利用率だけが上昇している場合などは適切にスケールアウトされません。そのため、Datadog External Metricsを利用してコンテナ毎のCPU利用率を基にHPAを行い、適切にスケールアウト・スケールインが起きるようにしました。一方でもし障害などでDatadogからメトリクスが取得できなくなった状況でも、なるべく問題なくスケールされるようにするために、各コンテナのCPU利用率が同じ程度になるようにリソースの調整を行いました。
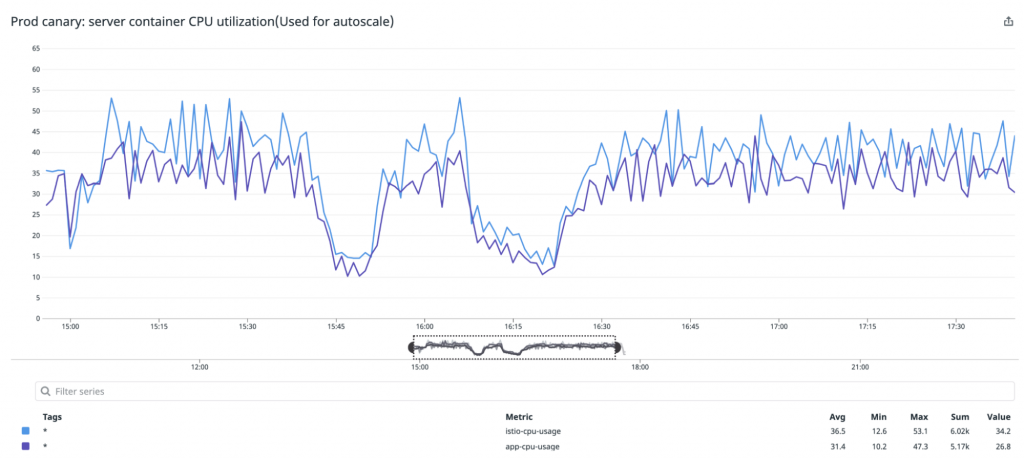
ItemサービスにおいてIstioを問題なく利用開始することはできましたが、 Istioを使うことによるメリットがある状態まで持っていくことはできませんでした。
例えば、VirtualServiceのweightを利用してトラフィックシフトをするためには、すべての呼び出し元のマイクロサービスでIstioが有効化されている必要があります。しかしItemサービスを利用してるサービス全てでIstioは有効にできていないため、Canary Deploymentの用途でIstioは利用できていません。ただ、今後Istioの機能を活用していくためにも、メルカリ全体でIstioの利用率を高めていくということは重要であるため、MicroserviceSREがEmbeddedされているチームでIstioを有効化していくということは意味があることだと思っています。
3. Mercari API GKE migration
メルカリのマイクロサービスはプラットフォームチームが提供するGKE上で動いています。Mercari APIはこれまでGCEで動いていましたが、マイクロサービスが動くGKEに移行することで、マイクロサービス開発と同じツールを使い、同じDeveloper Experienceを実現するプロジェクトが進行しています。私はそのプロジェクトに途中から参加しました。Mercari API には server/worker/cronのといった様々なコンポーネントがあり、順次移行を行っています。
私が参加した段階で、serverとworkerの基本的なKubernetesのリソースの作成は完了していたので、本番環境で運用・監視するための設定の追加・改善を行いました。具体的には、本番環境でのリクエストに対応できるためのserverやworkerのリソース調整やHPAの設定をや、各種Datadogインテグレーションの設定を追加し、nginxやapacheなどの各種メトリクスやリリースバージョン毎の差を見れるようにしました。
またserverの本番環境での切り替えの作業にも参加し、昨年12月から 1%、5%、10%と少しずつGKE側に構築した環境へのトラフィックを増やしていきました。そしてその中で起きた問題の対応・調査も行いました。
一番大きかった問題について簡単に説明してみます。
起きていた問題は Nginx(GCE) -> GCLB -> MercariAPI(GKE) 間の通信で、毎時5分~15分の間に “connection reset by peer” が大量に発生するというものでした。しかし該当時間でMercari APIとしては特定のエンドポイントや全体のリクエストは増えているわけではなく、Batch処理としてなにか動いている訳でもなかったので全く原因がわからないという状態が続いていました。
ネットワークチームやGCPサポートと調査をした結果、原因は該当時間にGCLBの「内部バックエンド サービスあたりの VM インスタンスの最大数」の上限に達していたというものでした。毎時同じタイミングで起きている理由は、同じGKEクラスタを利用している別サービスでメモリリーク対策として毎時Podの再起動するCronjobが設定されており、そのタイミングで一時的に非常に大量のリソースが要求され、Kubernetes Nodeのスケールアウトが発生し、上限にまで達していました。この問題への対応としてはGKEクラスタのサブセット化を有効にしてもらい、LBを作り直すことで解決しました。
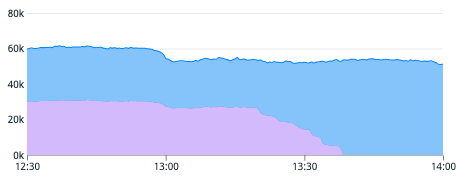
最終的には2月にGKEへの移行を完了することができました。
グラフはGKEとGCEの割合が50:50だったものが100:0に切り替わっているものです。
現在は cron の Kubernetes Cronjobへの移行を行っています。こちらの移行ではKubernetes Kit(k8s-kit)を利用しています。上記の記事でも書かれていますが、例えば、Workload Identityのような導入が複雑な機能であっても、以下のような設定を一行追加するだけで設定が完了するようになっています。
workloadIdentity: truek8s-kitはKubernetesのマニフェストを抽象化することによって本来手書きで記述する必要のある様々な設定を省略することができます。例えば、Workload Identityを有効にするとPodの起動時にタイムアウト エラーが発生する場合があることが分かっており対処が必要です。k8s-kitはServiceAccount周りの設定だけではなくGKEメタデータサーバーの準備が完了するまで待機するinitContainerの設定も生成します。そのため、k8s-kitを利用してサービスの設定を書き始めたチームは、意識しなくても上記問題に直面することはありません。
k8s-kitはCUEを設定言語として利用しています。利用者としてはKubernetesのyamlがラップされた独自設定を書くことに正直少し抵抗感はあります。しかし多くのチームがk8s-kitを利用・フィードバックをし、デフォルトの設定が改善されることで、あるチームが既に直面した問題の対応やプラットフォームチームが考えるベストプラクティスがすべてのチームの設定に反映される状況になれば、全体としてのメリットは非常に大きいと感じています。
まとめ
今回はMicroservicesSREとして、Embedded先で実際にどのような作業を行っているかを3つほど紹介してみました。
自分がEmbeddedされた2つのサービスでも状況は大きく異なります。Itemサービスでは基本的にメルカリのマイクロサービスのルールに沿って作成されているため、プラットフォームを活用し改善していくということができます。一方、古くからあるMercari APIサービスではログや監視の方法、そもそも言語が異なっているためメルカリ社内でマイクロサービス共通で提供されてるプラットフォームや利用されているライブラリの利用などはできません。
このようにプラットフォームの活用の推進や、プラットフォームだけでは解決できない課題の解決を、EmbeddedSREとしてサービス開発者と共に行えればと考えています。




