This article is a part of Developer Productivity Engineering Camp blog series, brought to you by @m from the Platform DX Team
Preface
The Platform Developer Experience (DX) team provides a ton of internal products for internal developers, most of whom develop microservices, to allow them to focus their business. The overview is explained in the previous article Developer Experience at Mercari.
This article introduces a CUE-based abstraction of Kubernetes manifests we’ve been developing.
It was created to solve many issues with configuring Kubernetes manifests. It reduces the amount of code, ensures resources are valid, defaults recommended configurations. Projects have up to 90% less code after migration.
Abstraction of Kubernetes manifests
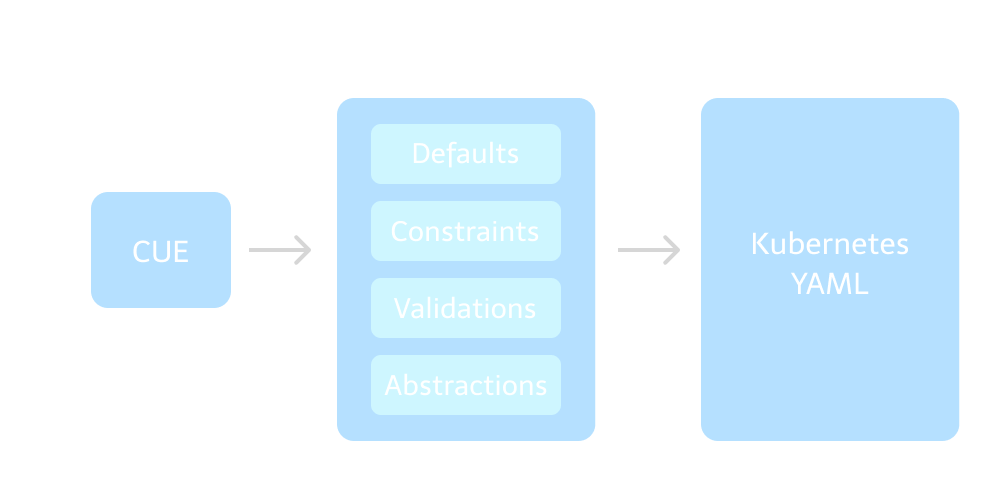
The project’s name is Kubernetes Kit (k8s-kit). It aims at simplifying Kubernetes manifests, reducing the amount of code, and easing cognitive load and required knowledge of Kubernetes and associated technologies like Istio for up and running services on Kubernetes clusters. The kit is implemented by CUE with the alternative to YAML.
A relevant project, Observability Kit, is also implemented by CUE to describe observability things like dashboards and monitors. Check out the article for more details.
Why use k8s-kit?
We have been using Kustomize and raw YAML to configure Kubernetes resources
In a nutshell, we had the following big challenges as more and more applications, typically microservices, have been developed and deployed:
- Lots of YAML: Need to properly configure lots of Kubernetes manifests with YAML to deploy applications
- Steep Learning Curve: Need to learn Kubernetes a lot
- Less Platform Control: Hard to apply required/recommended configurations by the platform team
- No Multi-Cluster Support: Any methods are designed for a single cluster
Since we’re running 200+ microservices in a production cluster and all devs aren’t Kubernetes experts necessarily, it was difficult to make sure all configurations are valid. It even can lead to lots of copy-pasting with some invalid configurations. Also, we, as a platform team, want to control Kubernetes resource configurations and sometimes need to update all of them with our requirements/recommendations. A typical example is a case where a platform team wants to ask devs to enable a new feature in the existing services. An example is Workload Identity. This secures applications running on a Kubernetes cluster and connecting to Google Cloud and we need to make sure that it’s enabled in all applications. This needs a bunch of updates for lots of manifests but it was difficult to do it without asking each developer or doing it by ourselves one by one. The kit also abstracts Workload Identity, which helps devs to migrate to it and even can default it. The kit solves such issues without increasing the burden of devs and allows advanced users are able to compose configurations in more clever and expressive ways than before.
What is k8s-kit?
The kit provides varying levels of abstraction on top of Kubernetes resources. All of which have reasonable defaults to meet requirements for up and running an application on a Kubernetes cluster. A notable example, the Application abstraction generates a set of Deployment, Service, (Horizontal|Vertical)PodAutoscaler, and PodDiruptionBudget resources; as well as a DestinationRule and VirtualService if Istio has chosen to be adopted.
The common issue with such an abstraction approach is that it can’t provide flexibility. However, the kit still has big flexibility so users can adjust their configurations based on their needs. It provides a patching mechanism to enable us to add, update, and delete arbitrary fields.
It also validates many fields by the feature of CUE, which prevents users from misconfiguring their Kubernetes resources. We offer constrained definitions of Kubernetes resource definitions for those who need to. For example, it disallows HorizontalPodAutoscaler (HPA) to have a value of minReplicas larger than its maxReplicas. This is a very simple example so you might not think it’d be really necessary. However, it provides more straightforward validations than some other methods like OPA and still realizes flexible validations like using regular expression and referencing configurations for multiple kinds of resources. This lets devs avoid lots of pitfalls in the Kubernetes configuration. The details of them are described in the below section.
What is CUE?
CUE is an open-source language used to define, generate, and validate all kinds of data. It’s a superset of JSON and provides integrations with many other language standards like Go, JSON, OpenAPI, Protocol Buffers, and YAML.
CUE also provides scripting features with just CUE and Go API, which we make use of to implement commands to see outputs as YAML, deliver resources, and so on.
Before going to the detail of the k8s-kit, you need to understand the following key concepts of CUE:
- Basis of configuration
- Data validation
- Schema definition
CUE defines configuration like the following example. This is a slightly modified version of an example the official documentation provides.
// example.cue
package example
#Spec: { // schema definition
kind: string
name: {
first: !="" // must be specified and non-empty
middle?: !="" // optional, but must be non-empty when specified
last: !=""
}
// The minimum must be strictly smaller than the maximum and vice versa.
minimum: int & <maximum | *1
maximum?: int & >minimum
}
// A spec is of type #Spec
spec: #Spec & {
kind: "Homo Sapiens"
// Kind: "Homo Sapiens" // error, misspelled field
name: first: "Jane"
name: last: "Doe"
}What does CUE do here? First, #Spec, which is called a definition in CUE, defines a scheme of data. This requires the kind and name to be configured, defines constraints for some values, and sets the default value for minimum.
spec is configured as conjunction with #Spec. Notice the shorthands in spec.name. A field whose value is a struct with a single field may be written as a colon-separated sequence of the field names.
CUE identifies a definition if it’s prefixed with # and identifies a value if not. Definitions don’t export, unlike values. Fields suffixed with ? are regarded as optional and CUE throws an error if non-optional fields aren’t given. If spec.kind isn’t given, CUE tells you it’s required but missing:
$ cue export example.cue
spec.kind: incomplete value string // errorWe can look at the output of the data by the following command:
$ cue export example.cue –out yaml // –out has defaulted “json”
spec:
kind: Homo Sapiens
name:
first: Jane
last: Doe
minimum: 1You can see that the #Spec definition doesn’t appear and the value of minimum has defaulted.
The package identifier defines a package of the file, which allows a single configuration to be split across multiple files. The following two files are interpreted as the equivalent to the first example in this section:
// def.cue
package example
#Spec: {
/* snipped */
}// val.cue
package example
spec: #Spec & {
/* snipped */
}CUE also has an import feature to import other packages, either standard packages like the “strings” package or user-created packages.
Why use CUE?
Generally, Kubernetes manifests require many boilerplate-like configurations in any kind of services, and some configuration to run services securely and efficiently like a security context and Horizontal Pod Autoscaler (HPA).
CUE provides mechanisms for intelligently setting defaults and validating values. It works well to simplify Kubernetes manifests. For example, CUE can generate an HPA manifest with reasonable values of minReplicas and maxReplicas while keeping flexibility. It can also append the label required for injecting an Istio sidecar based on a provided configuration.
CUE also has an integration with the Go language. This helps us support many kinds of Kubernetes resources since all Kubernetes resources are provided as Go packages. And its Go API helps us to create advanced workflows for CUE files.
With CUE, everything can be done in a local environment rather than relying on some external systems. Validation and generation can all be done on the client-side. Many alternatives would do this on the server side which limits the interactivity and stretches feedback loops.
These attributes let us satisfy all of our use cases; simple and advanced configurations, and even how resources are deployed. CUE is much more expressive than Kustomize and Helm with keeping central packages maintainable.
And some projects like Istio and Dagger are already considering, or are already using CUE.
Diving into k8s-kit
Basic Configuration
As previously mentioned, k8s-kit is implemented by CUE and provides devs with the interface of configurations with CUE.
An example of the simplest configurations looks like the following:
package kubernetes
import (
"github.com/mercari/kubernetes-kit/pkg/kit"
)
Metadata: kit.#Metadata & {
serviceID: "reviews"
}
App: kit.#Application & {
metadata: Metadata
}
Pipeline: kit.#Pipeline & {
metadata: Metadata
}
Delivery: app: kit.Delivery & {
pipeline: Pipeline.pipeline
resources: App.resources
}Application generates multiple Kubernetes resources as described above. And this simple configuration generates 200+ lines of YAML at the time of writing.
The following describes what each field and expression means, in order of appearance:
kit.#Metadata: Defines various metadata. Used for setting defaults and validating many kinds of values like labels and annotations. It will be referenced from other definitions.serviceID: Internal ID at Mercari pointing to a service, which is corresponding to a single Kubernetes namespace and GCP project ID per environment. The kit converts a service ID to Kubernetes namespaces internally. In the example, the namespaces arereviews-prodandreviews-dev, supposing we have 2 clusters for production and development environments.
kit.#Application: Defines a configuration for services on Kubernetes clusters. Generates Kubernetes resource configurations like Deployment, Service, (Horizontal)PodAutoscaler, and PodDisruptionBudget, with many reasonable defaults based on configurations provided to it.kit.#Pipeline: Defines a delivery pipeline. At the time of writing, we mainly use Spinnaker to deploy resources so it generates a Spinnaker pipeline configuration.kit.Delivery: Defines what resources are to be deployed and how they are to be deployed. The example specifies a Spinnaker pipeline but it can specify some other methods like Argo CD and the kubectl command.Deliverywill be a final output of Kubernetes resources and will be consumed by our custom CUE commands.
The schema of kit.#Application looks like below:
package kit
#Application: {
#Base // Base configuration including #Metadata.
spec: {
#PodSpec
// Application's Docker image name, excluding the image registry prefix.
image: mercari.#Name | *metadata.name
// Minimum number of replicas, as a percentage, that must be available.
minAvailable: string & =~"^([1-9]%$|^[1-9][0-9]%$|^100%)$" | *"50%"
// Scaling configuration.
scaling: #ScalingType
}
patch: {
// Patching arbitrary fields.
}
}This heavily depends on other definitions that we are omitting here, so you don’t need to completely understand what each field means. #Application and its dependent definitions sets defaults and validate values, allowing users to focus on specifying only the necessary parameters based on their requirements.
Multi-Cluster Support
The kit is originally designed to support multi-cluster configurations, unlike some other tools. The cluster to which an application is to be deployed is defined within the Metadata:
Metadata: region: "tokyo" // or "osaka"Note that the above is expressed by a CUE’s shorthand. In the example, specifying ”tokyo” means Kubernetes resources are deployed to the “tokyo” cluster.
Flexible, Intuitive Directory Structure
Since all files belonging to the same package end up being interpreted as the concatenation of the files, there is no restriction on a directory structure or the need to specify dependent files/directories like Kustomize.
We recommend the following structure to avoid duplications as much as possible but each dev can choose their own structure:
apps/reviews
├── development // dev specific
│ ├── kubernetes.cue
│ ├── osaka // dev’s osaka cluster specific
│ │ └── kubernetes.cue
│ └── tokyo // dev’s tokyo cluster specific
│ └── kubernetes.cue
├── kubernetes.cue // common to all env/cluster
└── production
├── kubernetes.cue // prod specific
├── osaka // prod’s osaka cluster specific
│ └── kubernetes.cue
└── tokyo // prod’s tokyo cluster specific
└── kubernetes.cueYou may see configurations under child directories unify with ones under parent directories.
Customization
Now that we covered the basics of the kit, let’s take more examples to know more how valuable it is.
1. Configure abstraction
Example below shows how to customize a configuration specific to a service:
App: kit.#Application & {
metadata: Metadata
spec: {
expose: grpc: port: 5000
scaling: horizontal: {
minReplicas: 3
maxReplicas: 10
}
}
patch: service: metadata: annotations: foo: "bar"
}The example specifies a port number for Deployment and Service, overrides the default configuration for HPA, and patched an annotation. The kit is designed to allow devs to easily customize their configuration and change most of the values flexibly as above.
2. Add additional resources
This example demonstrates how we can add additional resources:
Ingress: kit.#Ingress & {
metadata: Metadata
spec: {
domain: "mercari.com"
hosts: reviews: "/*": {
service: App.metadata.name
port: App.spec.expose.http.port
}
}
}
Delivery: app: kit.Delivery & {
pipeline: Pipeline.pipeline
resources: App.resources + Ingress.resources
}The kit can populate field values by referencing fields of other objects, which lets us avoid duplications.
3. Enable complex configuration with simple knob
The following example demonstrates how an Istio-related configuration can be done:
App: kit.#Application & {
metadata: Metadata
spec: networking: serviceMesh: {}
}This one line configuration in CUE allows the kit to generate the sidecar.istio.io/inject: "true" label, a bunch of Istio annotations with reasonable defaults, and configurations for some kinds of resource like DestinationRule and VirtualService. An Istio-related configuration is required for organizing a service mesh but is one of the most difficult to understand and configure correctly. The kit allows devs to easily set it up properly without much knowledge of Istio.
Scripting
The scripting feature with CUE enables the kit to work well. Our custom commands retrieve configurations written in CUE and run their jobs with the data.
Basically, the commands that are provided by the kit take the output of Delivery and decide what to do based on the data. For instance, the dump command prints manifests in the form of YAML (and even JSON):
$ cue dump ./apps/reviews/production/tokyo/…
apiVersion: apps/v1
kind: Deployment
metadata:
name: reviews
namespace: reviews-prod
labels:
app: reviews
app.mercari.in/name: reviews
app.mercari.in/part-of: reviews
topology.mercari.in/environment: production
topology.mercari.in/region: tokyo
version: main
clusterName: tokyo
// …A simplified implementation of the command looks like the following:
package kubernetes
import (
"encoding/json"
"encoding/yaml"
"list"
"strings"
"tool/cli"
)
command: dump: cli.Print & {
var: {
format: "json" | *"yaml" @tag(format,type=string)
kind: string | *"" @tag(kind,type=string)
name: string | *"" @tag(name,type=string)
}
_kinds: [ for k in strings.Split(var.kind, ",") {strings.ToLower(k)}]
_resources: {
for k, v in Delivery if var.name == "" || var.name == k {
"\(k)": [ for r in v.resources if var.kind == "" || list.Contains(_kinds, strings.ToLower(r.kind)) {r}]
}
}
if var.format == "json" {
text: json.MarshalStream([ for v in _resources {v}])
}
if var.format == "yaml" {
text: yaml.MarshalStream([ for v in _resources {v}])
}
}This passes Delivery to (json|yaml).MarshalStream and it prints a given values in the form of (JSON|YAML).
While this worked well in most cases, this has performance issues in a few edge cases and is hard to distribute to multiple repositories as a package. Therefore, we’re migrating the CUE scripting to use the Go API for CUE using flow package. Since its details are beyond the scope of this article, we will not describe how it works. Please check out the official document if you’re interested.
Wrap Up
The project allows devs to develop their applications faster and more confidently. The project is still in the early stage but we’re sure the project is going well and we can publish the information on this project more in the future.
Appendix
Here are several resources to learn more about CUE. Please check them out if you got interested in CUE.
Resources
Blog Posts
Videos
- Hands-on Introduction to CUE
- CUE: a data constraint language and shoo-in for Go
- Better APIs with Shareable Validation Logic
We’re Hiring!
The Platform DX team has been constantly enhancing developer experience with platform engineering. If you’re interested in working with us, please don’t hesitate to apply for the jobs!