こんにちは、メルカリMicroservices SREチームの mtokioka です。Embedded SREとしてマイクロサービスのチームに参加し、サービスの信頼性向上や自動化などの業務に従事しています。
メルカリでは Kubernetes Horizontal Pod Autoscaler(以下、HPA)を用いて pod のオートスケールを実現しています。しかし、標準でサポートされる CPU 使用率を用いたオートスケールでは不十分なケースがあり、そのような場合に External Metrics として Datadog のメトリクスを用いることでより柔軟なオートスケールを実現することができます。
これまでいくつかの External Metrics を実際に HPA で利用してきたので、導入事例を実際に適用した順番に紹介したいと思います。
事例 1:Container 別の CPU 使用率
HPA で用いられる CPU 使用率は pod 単位の値が用いられます。メルカリでは istio を導入していますが、この時点でアプリケーション用、istio 用の 2 つの container が同一 pod 上に存在することになります。各 container へのリソース割り当てが偏っていると想定通りにスケールアウトが行われなくなるため、container 別の CPU 使用率に基づいて HPA を構成しました。
※Kubernetes v1.20 から alpha 機能として container 別の CPU 使用率を指定できるようになりました。この機能を利用すれば External Metrics を使う必要はなくなります。実際の設定は次のようになっています。
DatadogMetric の定義(アプリケーション用 container)
apiVersion: datadoghq.com/v1alpha1
kind: DatadogMetric
metadata:
name: app-cpu
namespace: sample-app
spec:
query: >-
((avg:kubernetes.cpu.usage.total{kube_deployment:sample-app,kube_namespace:sample-app,kube_container_name:app}/1000000000)/avg:kubernetes.cpu.requests{kube_deployment:sample-app,kube_namespace:sample-app,kube_container_name:app})*100DatadogMetric の定義(istio 用 container)
apiVersion: datadoghq.com/v1alpha1
kind: DatadogMetric
metadata:
name: istio-cpu
namespace: sample-app
spec:
query: >-
((avg:kubernetes.cpu.usage.total{kube_deployment:sample-app,kube_namespace:sample-app,kube_container_name:app}/1000000000)/avg:kubernetes.cpu.requests{kube_deployment:sample-app,kube_namespace:sample-app,kube_container_name:istio})*100HPA の設定
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
…
spec:
…
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: External
external:
metric:
name: datadogmetric@sample-app:app-cpu
target:
type: Value
value: 80
- type: External
external:
metric:
name: datadogmetric@sample-app:istio-cpu
target:
type: Value
value: 80各 container 用に CPU 使用率を取得するための DatadogMetric リソースを定義し、HPA の設定から該当リソースを参照するようにします。
既存の CPU 使用率による設定に追加して、External Metrics を追加する形にしています。これは External Metrics のみで HPA を構成してしまうと、Datadog に障害が発生した場合に HPA が動作しなくなってしまうためです。このように設定することで Datadog からメトリクスを取得できなくなっても、既存の CPU 使用率によるスケールアウトを行うことができるため、耐障害性が向上します。
External Metrics の判定値の方が高めになっていることに気づかれたかもしれません。標準の CPU 使用率の値は pod 起動直後の値を取らないといった細工が仕掛けてありますが、External Metrics の場合は Datadog から取得した値をそのまま利用するため pod 起動直後の不安定な値までも取得してしまいます。そのようなノイズによる影響を軽減するために高めの値にしました。
事例 2:以前の pod 数との比較
非常に稀ですが、サイト全体を緊急メンテンナンス等で停止することがあります。リクエストが止まることになるのでスケールインが発生し、pod 数が最低限にまで減ったりします。そのような状態でメンテナンスが終了すると、急回復したリクエストを処理できずに pod が固まるような状況に陥りやすくなります。
そこで 1 週間前の pod 数と比較することで、一定以上のスケールインを発生させずに pod 数を保てるように HPA を構成しました。
DatadogMetric の定義
apiVersion: datadoghq.com/v1alpha1
kind: DatadogMetric
metadata:
name: num-pods
namespace: sample-app
spec:
query: >-
(50-
20*(sum:kubernetes.pods.running{kube_namespace:sample-app,kube_deployment:sample-app})
/ewma_20(week_before(sum:kubernetes.pods.running{kube_namespace:sample-app,kube_deployment:sample-app}))
)HPA の設定
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
…
spec:
…
metrics:
…
- type: External
external:
metric:
name: datadogmetric@sample-app:num-pods
target:
type: Value
value: 40Pod 数を取得するために kubernetes.pods.running というメトリクスをもとに External Metrics を作成しました。このメトリクスはデプロイ時に起動中の pod も数に含めてしまうのでかなり変動が大きくなってしまう問題があります。最初は kubernetes_state.deployment.replicas_desired を使おうとしていたのですが、更新頻度が低いためにメトリクスの有効期限切れが発生してしまい、External Metrics が無効と判定されてしまったためです。
※事例 3 でメトリクスの有効期限を延長する対応をしたので、今後は kubernetes_state.deployment.replicas_desired を使ったほうが良いかもしれません。External Metrics はやや複雑になっていますが次のように組み立てたものです。
- 「現在の pod 数 / 先週の pod 数」が一定数以下にならないようにしたい
- HPA は greater than で発動するためにマイナスを掛ける
- デプロイによる pod 数増加の影響を軽減するために、先週の値を平滑化する
- 適当な定数を足し、オートスケールの発動が穏やかになるようにする
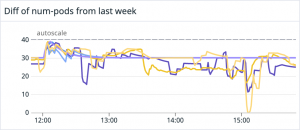
実際に Datadog の widget で表示したものが以下になります。複数 deployment があるため複数のグラフが描画されています。実際に設定を反映させる前にこのような widget を作ってみると動作イメージが湧きやすくなると思います。

オートスケールの発動を穏やかにするという部分ですが、HPA では pod 数は以下のような式で計算されます。
desiredReplicas = ceil[currentReplicas * (currentMetricValue / desiredMetricValue)]今回採用した External Metrics の最大値は 50、発動条件は 40 なので、最大でも 1.25 倍にしかなりません。この値が大きくなりにくいような式を作成することで、オートスケールが発動したときに、極端に pod が増加するようなことがなくなります。
事例 3:PubSub の残り message 数
非同期処理を行うために PubSub を利用することが多いと思います。その際に未処理の message がたまり過ぎることによる処理の遅延をある程度制御するために、残りmessage 数をもとに HPA を構成してみました。
詳しい内容はPubSub/Redisを用いたGoによるスケーラブルなworkerの構築と運用にありますので、ここでは簡単に紹介します。
DatadogMetric の定義
apiVersion: datadoghq.com/v1alpha1
kind: DatadogMetric
metadata:
name: sample-app
namespace: sample-app
spec:
query: >-
300 -
100 * 100 * sum:kubernetes.pods.running{kube_namespace:sample-app,kube_deployment:sample-app}
/
(1 + avg:gcp.pubsub.topic.num_unacked_messages_by_region{project_id:sample-app,topic_id:sample-topic})以下のようにメトリクスを組み立てました。事例 2 のものと何となく似た気配を感じると思います。
- 「message 数 / pod 数」を一定数以下に保ちたい
- message 数が分子にあると式が発散しやすいので逆数に変更
- HPA は greater than で発動するためにマイナスを掛ける
- 適当な定数を足し、オートスケールの発動が穏やかになるようにする
この式の最大値は 300、発動条件を 200 に設定したので、最大でも 1.5 倍の pod 数になるようにスケールします。
Datadog の widget で描画したものが以下になります。バッチ処理によって大量の message が発生し、オートスケールが発動しますが、その後は順調に処理を行っているという状況です。

なお今回 gcp.pubsub.topic.num_unacked_messages_by_region の利用が必須、かつメトリクスの取得に遅延があるため、DD_EXTERNAL_METRICS_PROVIDER_MAX_AGE という環境変数を設定することでメトリクスの有効期限を伸ばす対応が必要でした。
まとめ
今回、実際に External Metrics を利用した事例を紹介しました。ポイントをまとめると以下のようになります。
- External Metrics を利用することで、より柔軟な HPA を構成することができる
- External Metrics を利用する場合、既存の CPU 利用率によるスケールと組み合わせることで耐障害性を保てる
- メトリクスの有効期限に気をつける
- 実際に widget でメトリクスを描画してみると良い
- オートスケールの発動が穏やかになるようなメトリクスを作成すると良い
それではみなさん、良い External Metrics ライフを!




