
こんにちは。メルカリのNotification teamでソフトウェアエンジニアをしている@naruseです。
この記事は、Mercari Advent Calendar 2021 の19日目の記事です。
はじめに
私が所属しているBusiness Platform Notification teamでは、2つの役割で通知周りの基盤を担当しています。
1つ目はアプリケーションとしての役割の通知です。メルカリでは、アプリ内でのお知らせや個別メッセージ、やることリストなどを提供しています。私たちはそれらの膨大なデータを管理し、作成や取得のリクエストに応えています。これらの膨大なデータに対する私たちのチームの過去の記事として、昨年のAdvent calenderの一部である本番稼働中の Spanner にダウンタイム無しに57時間かけてインデックスを追加して得た知見をぜひご覧ください。
2つ目は、より基盤的な役割での通知です。メルカリでは、日々のお客様への通知方法として、EmailやPush通知・SMSなどを用いています。それらを送信したいリクエストを他のMicroservicesから受け取り、内部のAPIまたはチームで管理しているインフラを経て通知を送信しています。
今回の記事では、この2つ目の役割の送信に関して、非同期送信を行うためにスケーラブルなworkerを作成した際の知見を共有しようと思います。
1. workerの概要
まずはworkerの概要と特徴について説明をします。このブログの読者の中にも、APIでの非同期処理を行っている方は多くいるかと思います。私たちの背景や特徴と照らし合わせながら、ぜひ概要を理解してください。
1.1 背景
私たちがこの非同期処理を作った背景は2つあります。
1つ目が、通知基盤の移行のためです。皆さんご存じかと思いますが、メルカリではレガシーなコードからマイクロサービスへの移行を行っています。その一環として、通知基盤についても今までのレガシーな仕組みからの移行を進めているところです。今回はそのステップの一部として、移行先のサービスでキューイングの仕組みを先に取り入れる必要がありました。その課題の解決のため、今回はworkerを作成しています。
2つ目が、既存のAPIのピーク時間帯のレイテンシ悪化を改善するためです。これは副次的な効果も大きいものです。既存の内部APIでは、リクエストが多い時間帯にどうしてもレイテンシが悪化してしまうといった課題がありました。そのAPIに同期的にリクエストを送信してしまうと、他の多くのマイクロサービスが利用する私たちのサービスのレイテンシも悪化してしまいます。これを非同期的に送信することにより、レイテンシの改善を行うことも目的としました。
これら2つの課題を解決するために、今回はworkerを用いての非同期処理を構築しました。
1.2 通知マイクロサービスの特徴
既にCloud Pub/Sub(以下PubSub)とworkerを用いての非同期処理は他のいくつかのチームで運用されていましたが、私たちのチームではそれとは異なる大きな特徴がありました。それは、私たちのサービス特性によるものです。
私たちのサービスでは、コメント通知や購入通知など、随時配信される通知もあれば、キャンペーン通知や検索した保存条件の通知など、特定の時間帯に集中してバッチ送信される通知もあります。通知の種類によっては、バッチ送信される時間帯とリクエストが少ない時間帯でRPSが1000倍近く異なります。こうした状況もあり、リソースを有効活用するために適切にスケーリングするworkerを私たちは構築しようと考えました。
1.3 アーキテクチャ
以下がアーキテクチャ図になります
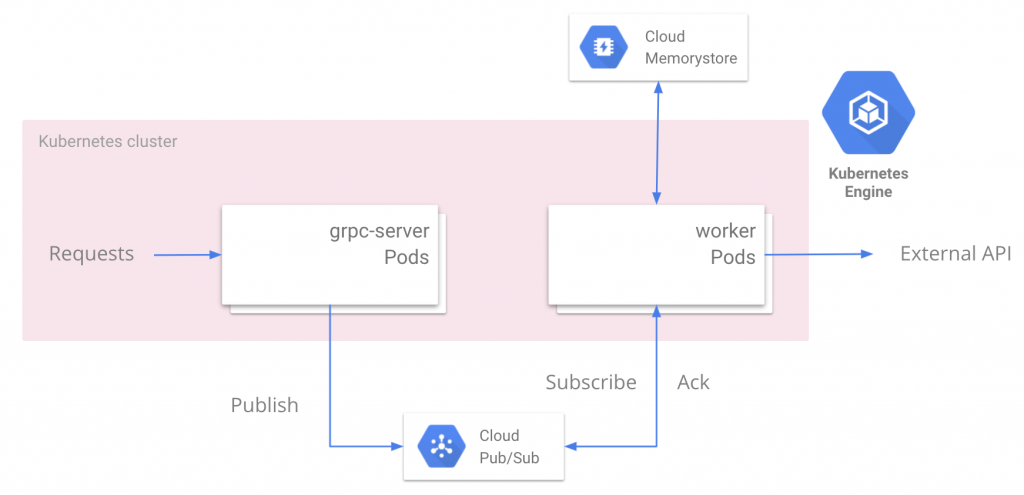
私たちが運用するマイクロサービスが受け取った通知送信リクエストは、まずPubSubのtopicへとpublishされます。その後kubernetesのpodで動いているworkerのプロセスがSubscribeを行い、後述のようにMemorystore Redisとの通信を行いながら、内部APIや外部の通知基盤へとリクエストの送信を行います。PubSubを用いているため、通知送信の通信がエラーとなった場合には指数バックオフを行い適切にリトライされます。また、podはHorizontal Pod Autoscaler(以下HPA)を用いて水平スケーリングしますが、それには後述の通りexternal metricsとしてPubSubのnum_unacked_messageを用いています。
1.4 (optional)Redisによる冪等性担保について
(本節はoptionalな内容となります。興味のない方は読み飛ばしていただいても構いません。)
これらの送信は冪等性を担保して行う必要がありますが、PubSubの配信はAt-least-onceであり、1つのmessageを複数のworkerがsubscribeしてしまう可能性があります。冪等性を担保する方法としてはRedisなどを用いる方法やGCPのDataflowを用いる方法などがありますが、今回私たちはMemorystore Redisを用いる方針を選択しました。冪等性を担保するための方針は以下の通りです。
- Pub/SubからメッセージをSubscribeする
- MessageIdがRedisに入っているか探しにいく
- もし入っているなら何もしない (nack)
a. 正常系で他のプロセスが先にmessageを掴んでいる場合には先にそのプロセスがackしているはず - もし入ってないならキーをセットして処理を開始
a. キーのセットに失敗した場合はnackしてリトライ - Messageの内容を内部APIに送信する
- 成功したらmessageをackする
- 失敗したらRedisからkeyをdelete
a. このkeyのdeleteに失敗した場合は3が繰り返されdead letterへ行く
2~4の一連の処理は、RedisのSET NXコマンドで実現しています。
また、7-aのパターンについて、内部APIのSLOとMemorystoreのSLOを掛け合わせるとこのケースは僅かであり、dead letter messageに関しては手動で回復オペレーションのjobを回すことで対応することとしています。
2. workerのスケーリング
さて、先述のような背景から、このworkerはスケールするように設計する必要があります。この章では、まずスケーリングの概要と、それに用いるメトリクスについて説明します。その後、メトリクスを用いる際に生じた課題や、スケールを行う際のGoのアプリケーション上の課題とその解決方法について説明していきます。
2.1 スケーリングの概要
このwokerはkubernetesのdeploymentとして定義され、HPAによりそのpod数を増減させています。HPAには2つの指標を使っており、1つ目はpodのCPU使用率、そして2つ目がPubSubの残りmessage数です。
PubSubに対してPublishされる数が時間帯によって大きく異なる以上、それをSubscribeして処理するworkerの性能は適切に変化させなければなりません。1つのpodはさらにその内部で複数のgoroutineを動かしmessageを処理していますが、そのスループットには限界があります。スループットが限界に達した時に正しくスケールしてあげる必要があります。CPUのリソースを調整すればそのメトリクスのみで上手くスケールできるかもしれませんが、実際には1podのスループットが限界に達した時のCPU使用率はmessageの内容やリクエスト先APIのレイテンシなどによって変化します。そのため、今回はPubSubのunacked messages数をexternal metricsとして使用し、CPU負荷が高くない場合でも処理していないメッセージが増えている場合にはpod数を増やすよう設定しています。次節ではその設定の詳細について書いていきます。
2.2 CPUによるHPA
CPU使用率は、HPAにおける標準的に使われる指標です。CPU使用率を指標としてレプリカ数を変化させ、ターゲットの値に収束させます。正確には、以下の式で表されます。( algorithm-details )
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )] 例えば、ターゲットのCPU使用率が50%の時、podレプリカ数が1でCPU使用率が120%の場合、レプリカ数はceil(1*(120/50)) = 3に変更されます。
このCPU使用率によるスケーリングは、httpサーバやgrpcサーバのdeploymentに対しては非常に強力です。CPU使用率はリクエスト数に比例する傾向があるため、CPUでスケールすることで正しくリクエストを分散できるからです。一方で、先述のようにworkerに対してCPU使用率のみを使うと問題が生じる場合があります。workerの処理限界とCPU境界は必ずしも一致するとは限らないためです。
2.3 PubSubの残りmessage数を利用したexternal metrics
そうした課題を解決するために今回はexternal metricsを導入しました。kubernetesでは、autoscaling/v2beta2以降のAPIバージョンを用いることで、CPU使用率以外の外部メトリクスを導入することができます。今回は、GCPからPubSubのnum_of_unacked_messagesを取得し、それをpod数で割った数値であるnum_of_unacked_messages_per_podを外部メトリクスとして用いました。
num_of_unacked_messages_per_pod = num_of_unacked_messages / num_of_pod当初、そのnum_of_unacked_messages_per_podをそのままメトリクスとして用いていましたが、それでは問題が生じてしまいました。その理由を見ていきましょう。
2.3.1 external metrics使用時の課題点
PubSubの特性上、num_of_unacked_messages_per_podはある程度の数は存在した上で推移していきます。その数が100件とします。そして、その値をキープして欲しいのでHPAのdesired valueも100としました。
ある時、Publish数が増えてnum_of_unacked_messages_per_podが300件まで増えたとしましょう。300件まで値は増えましたが、workerの負荷は少し高まりつつも捌けてはいます。現状のpod数が3の時、podの要求数を先ほどの式に当てはめると、ceil(3*(300/100)) = 9となります。
しかしながら、実際にはpod数を9に増やすのはあまり良くありません。それには2つの理由があります。
1つ目が、external metricsはCPU使用率に比べて取得するのが遅いため、HPAの挙動が発散しやすいからという理由です。external metricsはその名の通り外部APIからメトリクスを取得しスケーリングに用います。そのためCPU使用率よりも取得が遅れ、CPUでスケールした後に少し古いexternal metricsを用いてさらにスケールさせてしまうといったことが起こります。そのため、external metricsによるスケールはCPUよりも緩やかにしてあげる必要があります。
2つ目が、CPU使用率とexternal metricsの意味するものが必ずしも一致しないからという理由です。今回の場合は、メトリクスが3倍になることが必ずしも3倍のリソースを必要とすることを表しません。HPAは元はCPU使用率をターゲットに作られたもので、そのスケールアルゴリズムは2.2節の通りです。CPU使用率の場合はターゲットの2倍の使用率になっているということは2倍のリソースが必要であるということに近似できますが、今回のケースはそうではありません。external metricsを導入する際には必ずしも外部から得られるメトリクスが、そのままHPAのメトリクスとして用いることが難しいケースもあるということを意識する必要があります。
2.3.2 external metrics使用時の課題点の解決
そうしたケースを解決するために私たちのチームは次のような関数を導入しました。メルカリでは、embeded SREという役割として、各microservicesチームにSREの方が所属してくださっています。このメトリクスの調整については弊チームのSREの方にご協力いただきました。
metric = 300 - 100 * 100 * num_of_pod / (1 + num_of_unacked_messages)このメトリクスに対して閾値が200に設定されています。
式は一見複雑に見えますが、num_of_unacked_messages_per_podに以下のように少し手を加えているだけです。
- num_of_unacked_messages_per_podを逆数にする
- num_of_unacked_messagesは0になる可能性があるので0除算を避けるために分母に1を加える。
- 逆数にしたために負荷に応じて単純減少の関数になるが、HPAがgrater thanのみで発動するためにマイナスを掛ける
- 適当な定数を足す (この定数は後述の敏感度に影響します)
- 元の閾値に応じて新たに閾値を設定する
実際に例を見てみましょう。
num_of_podが3でnum_of_unacked_messagesが299の時、metric = 300 - 100 * 100 * 3 / (1+299) = 200となります。よって、このメトリクスは元のnum_of_unacked_messages_per_podが100をターゲットとしているのとほぼ同義になります。
では先述と同じようにnum_of_unacked_messages_per_podが300程度になった場合はどうでしょう。簡単の場合にnum_of_podが3でnum_of_unacked_messagesが899とすると、metric = 300 - 100 * 100 * 3 / (1+899) = 266.66...となります。これを2.2節のHPAのアルゴリズムに当てはめると、desiredReplicas = ceil[3 * ( 266.66.. / 200 )] = 4となり、新しいpod数は4となります。メトリクスをそのまま用いた場合の9と比較すると緩やかな変化になっていますね。
(敏感度に関する考察)
適当に設定した300という定数を200に変更して計算をやり直すと、閾値は100、num_of_podが3でnum_of_unacked_messagesが899の場合のmetricは166.66…、pod数は1.66…倍の5となります。このように、この部分の定数を小さくすることでより敏感にスケールを行い、大きくすることでより緩やかにスケールを行うようになります。それぞれのユースケースに合わせて設定することをお勧めします。
こうした値を用いても、スケーリングを繰り返すことで結局はnum_of_unacked_messages_per_podが100になるようにpod数は推移していきます。しかし明らかに異なるのはスケールの速度です。CPUの場合は求めるべきリソースサイズが分かっていたのでそのターゲットに向けてpod数を変更すれば大丈夫でした。しかし、external metricsの場合はターゲットとしたい値があっても、果たしてリソースがどのくらい必要なのかは、メトリクスによって大きく異なります。徐々にスケールを行うことで、求めるターゲットに値が収束し、必要以上にリソースを増やしすぎないようにスケールを実現できるのです。
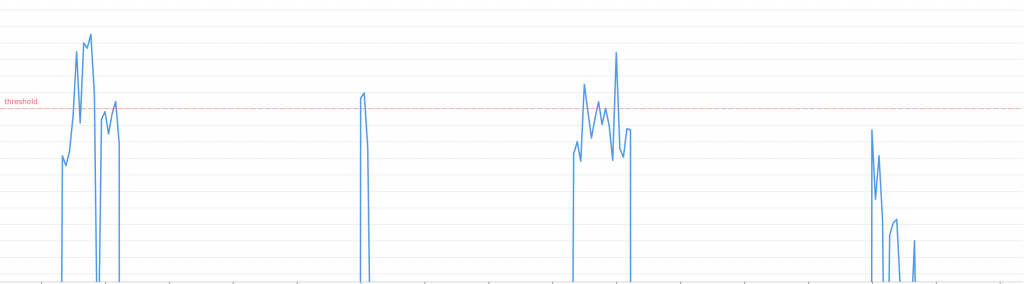
最後に、実際のメトリクスの値を載せておきます(縦軸の単位や横軸の時刻は伏せてあります)。 このthrethholdを上回った際にスケールを行い、適切に閾値以下にmetricsがなっていることがわかります。
2.3.3 その他external metrics使用時の注意点
その他の注意点として、external metricsの有効期限があります。
私たちはDatadogから取得できるものをexternal metricsとして用いていますが、その有効期限がデフォルトで5分となっていました。そのため、Datadog経由で取得しているメトリクスが5分ごとにしか得られない場合、頻繁にexternal metricsの期限切れが起こってしまいます。今回のケースではPubSubのnum_of_unacked_messagesが正にそれで、当初はメトリクスが取得できないことに悩まされました。解決方法は以下のとおりです。
DatadogMetric APIのv1alpha1を用いている場合は、クラスタ全体の環境変数DD_EXTERNAL_METRICS_PROVIDER_MAX_AGEを変更することで有効期限を伸ばすことができます。しかしながら、これはクラスタ全体に影響を及ぼすので、同じクラスタを利用している他のmicro servicesと調整する必要があります。
DatadogMetric APIのv1では、maxAgeフィールドが追加されました( link )。これを指定することで、external metricごとに有効期限を指定することができます。
2.4 Scale時のGoのコードにおける課題点とその解決
また、以上のようなスケールするworkerを作成しようと思うと、アプリケーション上(Golangのコード)にも課題点が出てきます。podは頻繁に終了と起動を繰り返すため、そのことを意識してコードを書く必要があります。
これらの課題についての詳細は、私が過去にmercari.go #17でお話した内容をご参照ください( mercari.go #17 を開催しました )。 概要については、以下のようになります。
- PubSubからmessageをSubscribeして処理するためのgoroutineの構成
- shut down時にSIGTERMを受け取ってからcontextをcancelして残りのmessageを正しく処理するための手順
- context cancel時の課題とその解決方法
- (課題1) 原子性を担保して2つの処理を行いたい時、同じcontextを使い回していると1つ目の処理のcontext cancel時にロールバックの処理も失敗してしまう
- (解決1) ロールバックや残りのキューの処理など、context cancel時にも最後に行いたい処理にはしっかりとタイムアウトを付与したcontextを使いましょう
- (課題2) context cancel時に残りのmessageの処理をしたはずがどうやら一部処理し切れていないmessageがあるとメトリクスから読み取れる
- (解決2) channelやvariablesなど、messageが残る可能性のある場所はしっかりと把握して、context cancel時に全てのmessageに対して適切なアクションをしてあげましょう
3. workerのパフォーマンスに関する考察と運用
ここまでは、スケールするworkerを構築するというトピックで、主にどのようにアーキテクチャ構成を考え、作っていくのかというお話をしてきました。しかし、新たなworkerを作った以上、その運用もしっかりと行っていく必要があります。現在のリクエストに対して適切なパフォーマンスは発揮できているのか、将来リクエストが増えた際に対応できるのか(垂直・水平スケール性)を考察し、理解した上で運用を行っていきます。この章では、このworker構築後に社内で作成したRetrospective(振り返り)から一部を引用し、このworkerのパフォーマンスについての考察をお伝えしようと思います。
3.1 外形監視
外形監視とは、外部から見た接続状況を監視することです。実際にユーザーの目線に立ち、この通知送信のリクエストがworker構築前後でどれほど変化があったのかを考察していきます。今回の場合のユーザーは他のマイクロサービス等、メルカリからの通知を送信したい社内のクライアントを指します。これらのメトリクスで、今回のworker構築自体の成果についての考察を行います。
3.1.1 レイテンシ
worker構築前後で、レイテンシは特にリクエストの多い時間帯において顕著に改善しました。
1.1節の通り、既存の内部APIを同期的に叩く方法では、高負荷時の内部APIのレイテンシ悪化により、通知送信のリクエストのレイテンシも悪化していました。
しかし、worker構築後は逆にリクエストの多い時間帯においてレイテンシが小さくなるという結果になりました。トレースを参照すると、リクエストが多い時間帯にPubSubへのPublishのレイテンシが小さくなったことが貢献し、リクエスト全体のレイテンシが小さくなっていました。これはコネクションが関係していると思われますが、結果として高負荷時にもレイテンシを悪化させることなく社内からの通知送信リクエストに応答することができるようになりました。
3.1.2 可用性
可用性についてもworker構築前後で改善しました。
これは非同期処理全般に言えることですが、PubSubを用いてリトライを複数回行うことができるので、内部APIや通知基盤の可用性以上の可用性を得ることができます。また、障害等で一時的に内部APIが不安定な状態になっても、PubSub内でのback off retryで障害が波及するのを防いだり、dead letterの再送で通知送信のリカバーを行ったりすることができます。
3.2 内部監視
内部監視とは、システムの内部状態を監視することです。ここでは、kubernetesやPubSub、Memorystore Redisなどのコンポーネントについて考察を行なっていきます。これらの考察は、この先にworkerを運用していく際に重要になります。
3.2.1 worker
先述の通りworker自体のプロセスはkubernetesのdeploymentsとして動いており、HPAによりそのpodレプリカ数を増減させています。HPAのmax replica数には注意する必要がありますが、理論上は無限に水平スケールすることができます。
3.2.2 PubSub
PubSubについても同様に水平スケールすることが知られています。PubSub自体のPublishレイテンシも高負荷時に顕著に悪化することはなく、安定してPublishを行うことができていました。
3.2.3 Memorystore Redis
一方で、Redisについては単純に水平スケールすることはできません。ある程度まではリソースを増設することで垂直スケールすることはできますが、リクエストが増えて垂直スケールが限界に達するまでに対策を行う必要があります。ここでは対策の例を2つ挙げておきます。
1つ目はRead replicaの利用です。Memorystore Redisでは、現在プレビューとしてRead replicaの機能の提供を始めています( link )。これを利用していくことで負荷分散を図りますが、今回のケースでは読み取りの比率はあまり高くありません。ある程度の効果は得ることができますが、書き込みが多い以上は同様の垂直スケールの限界に当たってしまう未来が考えられます。
2つ目は水平分割の検討です。今回のケースはmessageIdをRedisにSETしています。例えば、このmessageIdのmodに応じて水平分割を行うことで、負荷分散を図ることができます。この方法ではRedisのインスタンスを増やし、modに応じてclientを使い分けることでさらなる負荷に耐えることができます。しかし、水平分割を行う際には書き込みを両方のインスタンスに行うようにしてから読み取り先を変更し書き込みを止めるといった手順での移行が必要になります。
さいごに
この記事では、「PubSub/Redisを用いたGoによるスケーラブルなworkerの構築と運用」というタイトルで、workerの構築からスケールのための課題点、その後の運用や今後の考察など、一気通貫してworkerについての知見を共有しました。読者の皆さんに中にもworkerを用いて非同期処理を行っている方は多いかと思いますが、今回のこの記事で共有した知見が皆さんが今後workerに関わる際の一助になれば幸いです。
明日の記事はkuuさんです。引き続きお楽しみください。




