The 24th day’s post of Mercari Advent Calendar 2020 is brought to you by Shinji Tanaka (@stanaka), VP of Backend, from the Mercari Engineering division.
Abstract
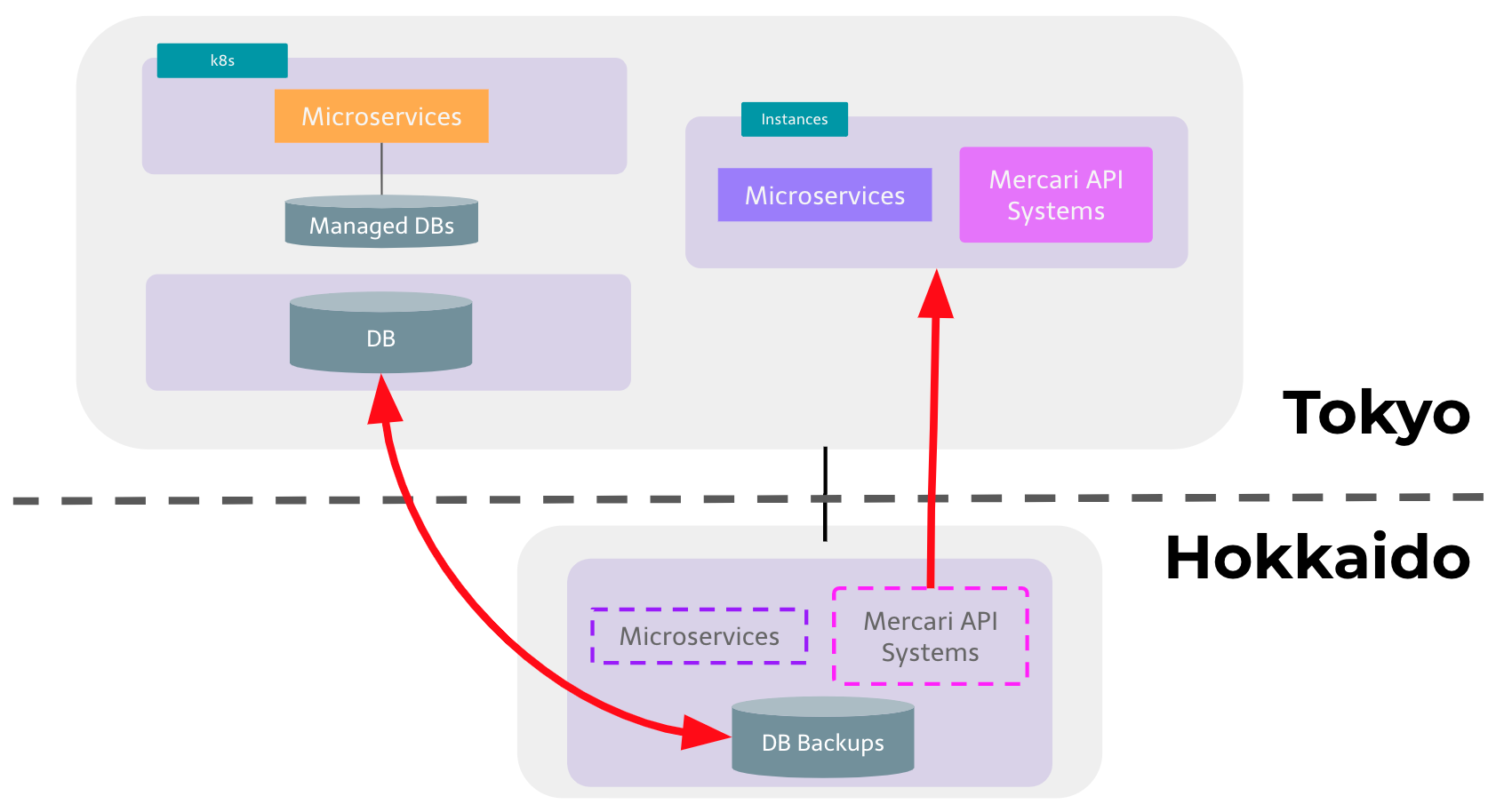
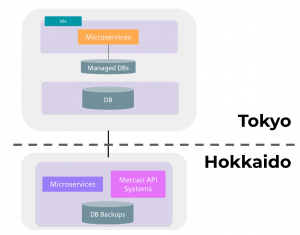
We’ve been working on the microservices migration project for a couple of years and we have recently reached one of the most important milestones in the project, which is moving our original core system from Hokkaido (the northern region of Japan) to Tokyo, where our new microservices are located.
The main purpose of this project is to reduce latency and to accelerate the succeeding architectural improvements, including better developer experience, environmental parity, and resiliency.
We are now working towards the next milestone to achieve these improvements.
Background
As we posted in several blog entries about microservices architecture here, our microservices architecture has a fundamental issue, which is high latency between the original environment and the new microservices environment.
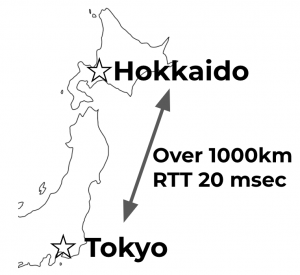
The latency between Tokyo and Hokkaido is not negligible. It is around 20 milliseconds for a roundtrip communication. We experienced incidents caused by this distance, which requires several network elements for communication.
When microservices in Tokyo need to call APIs in the original system in Hokkaido multiple times per request, the latency is multiplied and this impacts the end-to-end response latency experienced by our users.
This also makes microservice migration difficult because engineers need to take into account the large latency caused by the Tokyo-Hokkaido round trips. For example, in some cases our engineers had to reimplement or move logic between data centers as a result of performance issues rooted in the geographical distance or network topology between our data centers. By moving all systems to Tokyo and by simplifying the network topology, our engineers now have a much easier time when implementing services and features.
On top of that, tech stacks of both systems are also quite different, and this difference makes it difficult for engineers to work on both. Especially engineers who joined recently and worked on the new microservices are not familiar with the legacy monolithic systems and tend to stumble on common pitfalls of the core systems which experienced engineers can easily avoid.
Direction
The data center migration project has two main objectives, which are to reduce this latency and to improve developer experience by consolidating the legacyoriginal technology stack with the new one.
We set the main success criteria of this project as avoiding incidents during the migration, so we tried to focus on only one big thing at a time. For this reason we decided not to re-architect or reimplement the legacy systems during this first phase
- Move the main part of system from Hokkaido to Tokyo
- Do not change many things at once but have multiple steps to limit risk
After this big first milestone, we can set the next milestone to simplify the system architecture, at which point the systems will be more reliable and developers can be more effective thanks to the use of a unified technology stack.
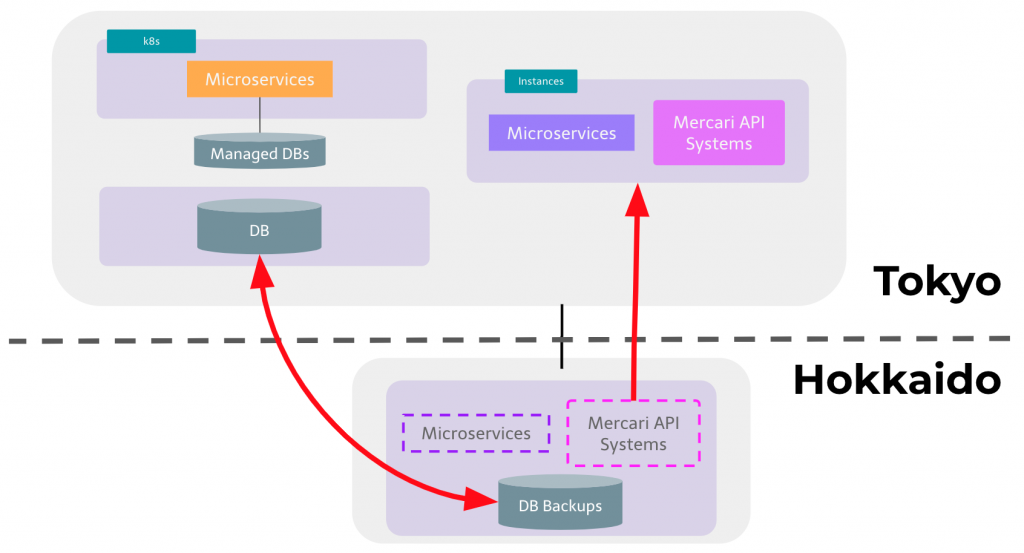
Solution
To follow this direction of the first milestone, we prepared instances and hardware which can handle the same amount of traffic and data handled by the original systems in Hokkaido. Then we can lift and shift the original systems in Hokkaido to environments in Tokyo.
There are several expected difficulties, like handling with slightly increased latency between the Mercari API systems and databases. To ensure that this would not negatively impact the outcome of the migration , our SRE team simulated an increase in latency between our production application and database servers in Hokkaido. The results showed that such an increase in latency would not have a significant impact on user-perceived performance.
To further increase confidence in the new infrastructure in Tokyo we shifted a very small part of production traffic to the new environment and gradually increased while we confirmed the end-to-end performance is under control and there was no alert.
To be able to perform a full QA cycle of the new infrastructure we also implemented a way for QA engineers to flag traffic as “QA for data center migration” traffic. Such traffic, once validated, would be routed to the new production infrastructure regardless of source (native clients, web, other API) and regardless of path through the frontends and microservice forest. This allowed our QA engineers to check that all major features and third-party integrations of our products would continue to work even when handled by the new infrastructure.
When we completed to shift the whole traffic to the new environment in Tokyo, we observed the overall end-to-end median response time was also improved by roughly 20ms, in line with expectations. This was an improvement of roughly 40%.
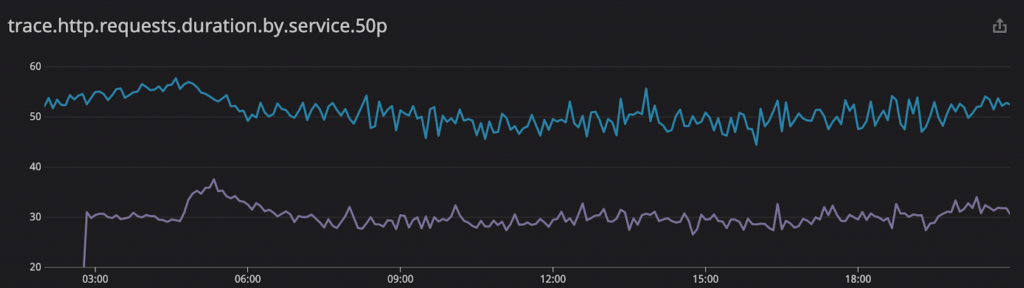
(p50 latencies for API calls: blue is Hokkaido, violet is Tokyo)
Next Milestone
We now set the next milestone to achieve the following.
- To unify the technology stack of these systems with the new one.
- To achieve environmental parity between production and development environments.
Conclusion
We have recently reached an important milestone in our engineering strategy, and this has finally removed major blockers to architectural improvements and new features. As a nice side effect, we also achieved an important reduction in our end-to-end backend latency.
All of this is just the beginning though; the next milestone is now in our sights, as we can now start to make significant improvements to our developer experience and overall architecture, with the ultimate goal of empowering our growing engineering teams to effectively deliver continuous improvements to our user experience.
To this end, we are currently looking for Software Engineers and SREs who are interested in working on the challenges and opportunities inherent in microservice architectures. If you are interested in joining us, head over to our engineering careers page at https://careers.mercari.com/job-categories/engineering/.
Tomorrow’s blog post —the 25th in the Advent Calendar— will be written by Suguru, our CTO. Hope you are looking forward to it!