
※この記事は、"Blog Series of Introduction of Developer Productivity Engineering at Mercari" の一環で書かれています。
著者: Microservices SREチーム @k-oguma(ktykogm)
本記事の内容は、前日の記事である "Embedded SRE at Mercari "の具体的な事例等の紹介となります。私自身が実際にEmbedded SREsとしてプロダクトチームに参加し、その中で発見したプロダクトチームの課題とそれに対して行った取り組みをいくつか紹介したいと思います。最後に具体的な活動を通して見えてきたEmbedded SREsのメリットなどについてまとめます。
本記事内の用語
- SRE
- Site Reliability Engineering の略
- 信頼性における方法論、概念、ベストプラクティス集
- SREs
- SREを専門に実践するエンジニアのことを指し、人間が対象
- 例え一人が対象でも区別のためにsを付ける
- Microservices SRE
- メルカリのマイクロサービス開発チーム(プロダクトチーム)にEmbedded SREsとして参加し、SREを実践および普及するチーム名、職名
想定読者層
本記事は以下の読者を想定しています。
- SREs
- SREの実践経験があるエンジニア
- SRE学習者
Microservices SRE についておさらい
Microservices SREチームのミッションとして以下の3つが挙げられます。
- マイクロサービスチーム特有の事情に合わせた信頼性向上のサポートを行うEmbedded SREs
- 組織全体にSREプラクティスを広めていく
- Platformチームが開発するマイクロサービス基盤の新しい機能の導入を支援する
Embedded SREsとしての取り組み
ここからEmbedded SREsとして取り組んだ事例の紹介をしていきます。
まず、Embedded SREsとは何かですが、 サービス開発チームに組み込まれる形でSREを実践し、SREベストプラクティスをサービス開発者を含めてチーム全体に伝えていく役割、いわばSRE伝道師(エバンジェリスト、evangelist)のような存在となります。
Enabling SREという言葉もありますが、我々の場合はすでにSRE is Enabledな組織にもSREの強化や改善策を伝え回っているので、Evangelistもしくは巡回説教者(circuit preacher)のほうがニュアンス的に近いです。
メルカリの場合はこのEmbedded SREsを非固定型とし、可動性を持たせる形(Movable Embedded SREs)を基本とすることで、様々なチームに参加し、より広い範囲をカバー出来るようにしています。
Embedding したチームの紹介
私はこれまで大きく2つのプロダクトチームにEmbedded SREsとして参加してきました。最初は、マイページ とお客様のソーシャル面のサービスを持つuser-social チームに参加しました。
そして今は、商品詳細サービス、いいね!サービス、UX周りを受け持つサービスなどを担当している複数のチームに参加しています。
複数のチームに参加する中で、以下のような共通する課題がありました。
- オンコール体制の不備
- SLO監視の不足
- DBパフォーマンス問題
- 新機能の導入遅れ
- etc
以下で、これらの課題にどのように取り組んだかを一部紹介していきます。
オンコール体制の不備
マイクロサービスの運用においてはオンコールが大きな問題になることが多いです。なぜなら開発しているチームの数に対してより多くのサービスを開発運用することになり、愚直にサービスごとにメンバーを割り当てるとメンバーが不足してしまうためです。例えば現在担当してるチームではオンコール担当が全部で2名しかおらず、隔週交代ということが起こっていました。そのため適切なオンコール体制を整備するのは非常に大切です。
しかし、その課題に対してどのような運用体制を構築するべきかハッキリしないことも多いです。例えば、どのくらいの人数でオンコールを回すべきかが分からなかったり、オンコール時に何をして何をするべきではないかが曖昧なチームも多くいました。
そしてこれらはオンコールへのオンボーディングにも強く関係します。オンコール体制に不備が多ければ不安や負担が影響し、オンコールメンバーを増やしにくくなる懸念があります。
メンバーを適切な数に増やすことが難しければ、オンコール体制の強化が難しくなるため、不安や負担が解消されず、オンボーディングしづらくなるという悪循環に陥らないようにオンコール運用の強化を図ることを優先的に実施することにしました。
オンコール体制の改善
オンコール運用の強化を図る上で、指針やチーム内での約束、安心、認識を明文化することは非常に重要です。
なぜなら迷いや不安や負担を減らすことが運用強化につながるからです。加えて心理的安全性も向上します。
これはバジェットポリシーの明文化と同じくSREベストプラクティスです。
https://sre.google/workbook/on-call/
具体的には次のことなどを書いたリファレンス / ガイドラインを作りました。ガイドラインには以下のようなことが書かれています。
- 最低何人いると "単独のオンコール当番" および "長期スパンのローテーション" が避けられるようになるのか
- 何人以上いるとどういった トイル の撲滅活動が出来るようになるのか
- 何人体制だと各SEV レベル に対し、MTTA/MTTRの目標値はそれぞれどのくらいに出来るのか
- どのように人数が少ない開発チームでオンコールを上手く回すか
SEV レベルとは:
- インシデントのインパクトでレベルが分別され、数値が小さいほどクリティカルインシデントとして扱われます
- SEV レベルごとにインシデント対応の手順が明文化された指標になります
- 参考
- https://response.pagerduty.com/before/severity_levels/
- https://dzone.com/articles/practical-guide-to-sre-incident-severity-levels
- MTTA: Mean Time to Acknowledge. Alertが発報されてから応答(行動を開始)するまでの平均時間
- MTTR: Mean time to recovery, repair, respond, or resolve. 平均復旧時間、平均修復時間、平均対応時間、平均解決時間のどれかで通常は修復か復旧を指します。 例えば、オンコールを初めてやるメンバーは、よく「オンコールを受けたときに自分が全ての問題を解決しないといけないのか」という不安を持ちがちです。そのような不安を解消するために、ガイドラインには、以下のような心構えを書いています。
「エスカレーションをしても誰もあなたの能力を疑うことはありません。プライマリのオンコール当番を恐れないでください。クリティカルなインシデントが発生した際は、詳しい人は誰かを確認してエスカレーションするようにしてください。」
### Escalation policy
- Requires escalation path
- Escalation is a normal functional process
- Even if you escalate, we will NOT suspect your ability
- If anyone suspected that, they need to learn about psychological safety
#### You don't feel afraid to become a `primary` on-call engineer
- **If a critical or significant incident occurs**
- We expect our primary on-call engineer to **escalate to a team member who knows more about the services involved in the incident**
- We need to do the following:
- `first investigation -> overview of the incident -> identify appropriate contact -> escalation`
- **On-call duties do not mean that you alone are expected to solve everything!**次は何人体制だとどのようなオンコールシフトと業務内容が組めるかの説明です。
共通項目として、インシデントに対する心構えや、オンコール業務期間の働き方を説明しています。
そして、オンコール担当の人数によって体制が変わるので、人数別に出来ることと目標を定めています。
例えば、オンコール参加が可能なメンバーがチーム全体で3〜5人の場合は、オンコール当番がプライマリ、セカンダリの2名体制は難しいので、1名体制となります。その場合に出来ることは インシデント対応の他にdependabot の更新対応含めてセキュリティアップデートや社内ツールの更新、積極的なコードレビューへの参加などを行うようにしています。
(一部加工しています)
### Common
- Formation
- If you have no responsibility on-call, you can still be flexible in case of emergencies.
- If your expertise is needed to resolve an incident, it is escalated to you.
- Otherwise, you will basically leave it to the on-call duty
- Where do I need to contact first?
- [#slack_channel](https://......../)
- What to do while on-call?
- During the on-call period, please stop or pend your normal development work and focus on the following to help everyone!
- Of course, if it does not interfere with your regular on-call work, you can do your everyday (normal) development work
- Or you can do DevOps development to eliminate/reduce toil, indeed DX improvement
### 3 to 5 people
- Formation
- Only primary. (Only one)
- What to do while on-call? (Tasks while on-call)
- Update with dependabot
- Update in-house tools
- Incident response
- Dealing with security issues
- Code Reviews
- Rotation Period
- 1 week (Rotate every 3 to 5 weeks)
- MTTA (Mean Time To Acknowledge) objective (SLA of Response time)
- MTTA <= 30min
- MTTR (Mean Time To Repair/Recovery) objective
- [SEV-1](https://response.pagerduty.com/before/severity_levels/)
- 1h
- SEV-2
- 2h
- SEV-3
- 12h
- SEV-4
- 24h
- SEV-5
- 48h
### 6 people
- Formation
- Two people (Primary 1 + Secondary 1)
- What to do while on-call? (Tasks while on-call)
- Update with dependabot
- Update in-house tools
- Incident response
- Dealing with security issues
- Code Reviews
- Response to inquiries
- If you need to take over, do so.
- Follow up actions for incident resolution.
- Write postmortem in the Blameless
- Development for toil elimination
- Purpose to reduce toil
- e.g. Ops automation, etc
- Update documents
- Target to outdated contents
- Rotation Period
- 1 week (Rotate every 3 to 5 weeks)
- MTTA objective (SLA of Response time)
- MTTA <= 15min
- MTTR objective
- SEV-1
- 0.5h
- SEV-2
- 1h
- SEV-3
- 6h
- SEV-4
- 12h
- SEV-5
- 24hなお、補足ですがオンコール当番中はスプリントへの影響を和らげるのと、周りへの共有とオンコール当番の引き継ぎ情報のためにも、毎回チケットを発行するようにしています。
オンコールを改善した結果どうだったか
上記の施策を行った結果、オンボーディングの改善にも繋がりましたし、これに関係するPlaybook/Runbook(後述)の用意、そしてインシデント対応の強化にも繋がっていきました。
また、オンコール担当者の負担や不安を減らすことにもつながっていき、自分自身オンコールに入りやすくなりました。
SLO監視の不足
続いてSLOについての事例紹介に移ります。
SLOとはサービスレベル目標の意味で、サービスの提供/可用性のレベルを維持するために必要な数値目標とし、ユーザーエクスペリエンスで求められること以上のことはしない合理的かつ信頼性の高い数値目標です。
Google Cloudブログの言葉を借りると、「システムの可用性を正確な数値目標として設定するもの」となります。
監視運用にデータドリブンを持ってきたような目標値であり、開発組織全体とのコミュニケーションツールとしても利用されます。
アラートの追加、調整、抑止などの作業を行っていたところ、SLOの閾値が標準値のままで実状に適していないケースがあることに気が付きました。
伝わりにくい「パーセンタイル」と「SLO」を伝えていく
我々はSREを広めていくという使命も持っているため、開発チームのメンバーに様々なSREの勘所を伝えていくことも常に行っています。
例えばパーセンタイル や(クリティカル) ユーザージャーニーという概念を用いて説明し、指針を示すこともします。
パーセンタイルとは、最小値から数えた場合の位置を指します。我々は基本的に95パーセンタイル、つまり最小値から数えて95%の位置を標準としています。
レイテンシーSLOを例にしますと正常なリクエストの全体数から95%の位置が95パーセンタイルのレイテンシーになります。
そして、パーセンタイルを採用している理由は、平均ではロングテールまで含めてしまうので、それを避けるためです。
別の言葉でより具体的に説明すると、ごく一部で非常に大きな値になった場合、それまでの全てを計算に含めてしまうと平均値が一気に上がってしまいます。
しかし、SREのベストプラクティスとして100%を目指さないという方針もあります。そのため、ごく一部でたまたま大きな値になったものは無視してもOKとし、それを外れ値として監視対象から外すことで、監視にノイズが混じらないようにしています。95パーセンタイルのレイテンシーでしたら、上位5%のレイテンシーを無視します。
ここまではわかりやすく、伝えるのもそれほど難しくはありません。
しかし、50パーセンタイル(中央値)、75パーセンタイルなどと比べて、どのような傾向があるかは分かりにくいところもあり、全員に伝えるのも容易ではありません。
95パーセンタイル以外が必要になりそうな監視対象があるなど考えるきっかけ作りを兼ねて、ディスカッションを行うことにしました。
例えばDatadogのAPMでも各パーセンタイルを並べて見ることが出来ます。

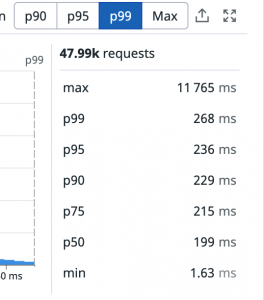
しかし、これだけだとアクセスの全体的な傾向がどういうときにそれぞれのパーセンタイルがどのような形で現れてくるのかがわかりづらく、伝えるのも難しくなります。
そこでSpreadsheetを利用して擬似的に監視計測パターンを複数用意し、それぞれのパーセンタイルを出してチーム内でレビューやディスカッションを行いました。
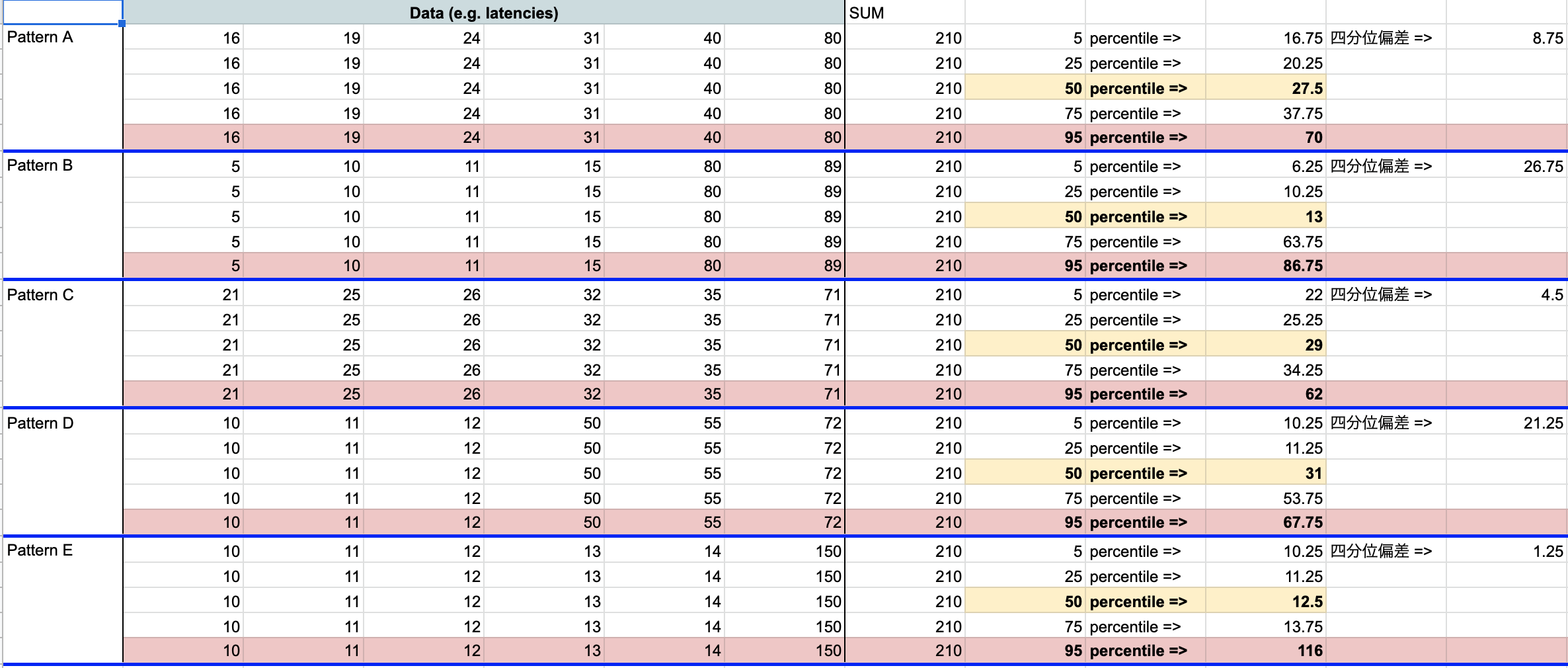
※上記は、正確な値ではありません。
パターンA〜E 5種類の5、25、50、75、95 パーセンタイルを作り、どういった傾向がそれぞれあるのかを明確にしながらチーム内で重要メトリクスに95パーセンタイル以外でどこまで監視が必要か & どこまでSLOに含めるかを議論をしたときの例
(四分位範囲および四分位偏差は、データのばらつきをみています)
こうすることで、全体的に遅い場合に95パーセンタイルだけでは検知しにくいということが伝わると思います。(注: 95、99パーセンタイルだけで良いケースも多いと思います)
全体的に遅くなった場合において、その影響が大きく問題になる監視対象であれば、例えば50パーセンタイル、75パーセンタイルの監視も追加することが望ましいです。なお、SRE本だと「50パーセンタイルを使うと典型的なケースに重点を置くことになる」というような表現で紹介されています。
以上のようにして、SLO監視の強化を行っています。
DBパフォーマンス問題
弊社のマイクロサービスのDBとしては、Google Cloud Spanner (以下Spanner)をメインで利用しています。
そして我々SREはマイクロサービス開発のコードレビューにも積極的に参加しているので、リリース前でも遅いクエリを見つけることがあります。
DBパフォーマンス改善
例えばセカンダリインデックス周りだとSTORING句を検証して、使用の勘所をドキュメントにまとめ、所属するマイクロサービスチームへ導入を促しています。
また、複合インデックスやクエリー設計でパフォーマンスを改善させるなどの作業も行っています。
新機能の導入遅れ
弊社はGKEを使っていますが、全てクラウドマネージドで完結するわけではありません。Istioやクラウドのネットワークポリシーなどの導入など様々な機能、システムを導入していかなければなりません。
また、社内のPlatformチームが開発したツールを導入していく必要もあります。
しかし、サービス開発に多くの時間を取られる形でその導入が遅れることがありました。
新機能の導入を促進する
この辺りもMicroservices SRE チームの重要なタスクの一つとしています。
自ら導入を行うこともありますし、PlatformのNetworkチームなど他のチームと連携して導入していくこともあります。
そして各マイクロサービスで遅れが生じないように対応を行っています。
他のチーム との連携
メルカリグループには、各社それぞれでSREチームが存在します。
そしてメルカリでは、各レイヤー/スコープでSREが存在しています。
我々Microservices SRE 以外にもいくつかのSRE/インフラ関連のチームが存在します。
例えば、PlatformチームもSRE関連の業務も積極的に行っています。
インシデント発生時も迅速に連携を組んでお互いをサポートしながら早期解決に挑んでいます。
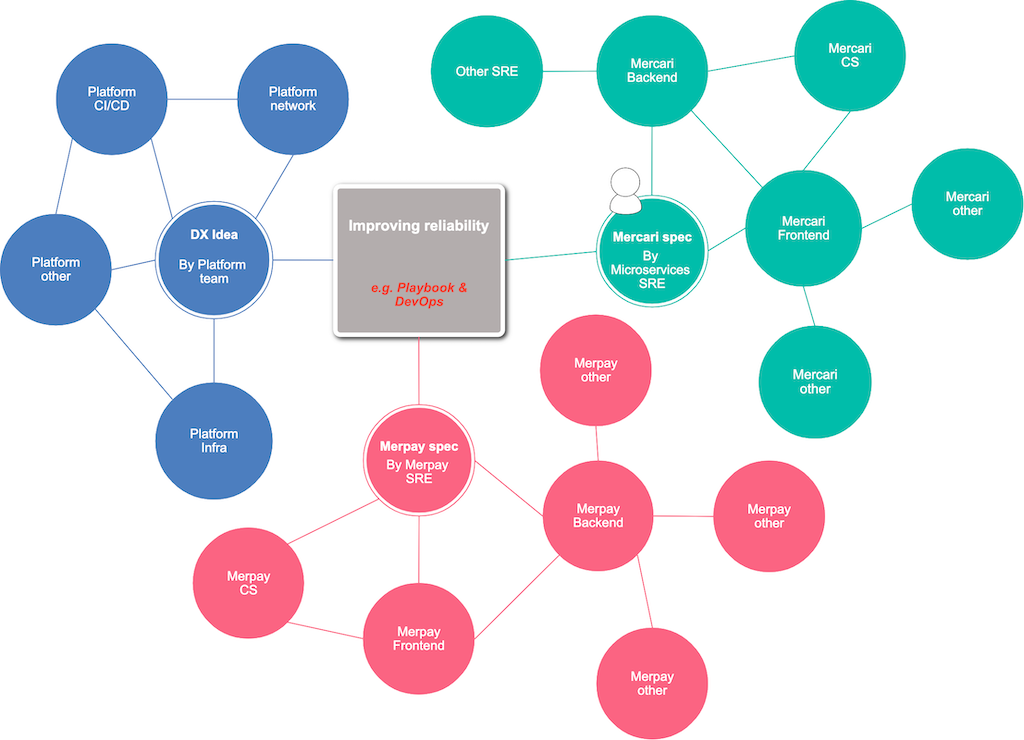
(※この関係図は組織全体で信頼性向上に関する連携作業に対する概念図であり、正確な関係を示しているわけではありません。)
インシデント対応後はポストモーテムも関係者にて共同で行っています。
ポストモーテムは常にひとつのチームだけでは行っておらず、SRE以外の技術者も何人も参加してマイクロサービス開発者からの意見なども入って非常に有益な情報が飛び交っています。
他にも、ここしばらくメルペイSREチームおよびPlatformチームと共同で行っていることとして、PlaybookとRunbookの導入に取り組んでいます。
- Playbook
- オンコールや通常運用でも使う主に "対インシデント" の運用手順書のことを指しています
- Alertごとのガイドブックのような位置づけで、エスカレーション情報やその他連絡先などの情報も記載しておきます
- Runbook
- 単一目的・単一責務の手順書や(半)自動化ツール、コマンドを指します
- マイクロサービスや担当者などの情報は一切持ちません
- Playbookがガイドブックとすると、その中に入るリンク先です
- Playbookのコンポーネントとして扱われ、再利用性を高めています
- 単一目的・単一責務の手順書や(半)自動化ツール、コマンドを指します
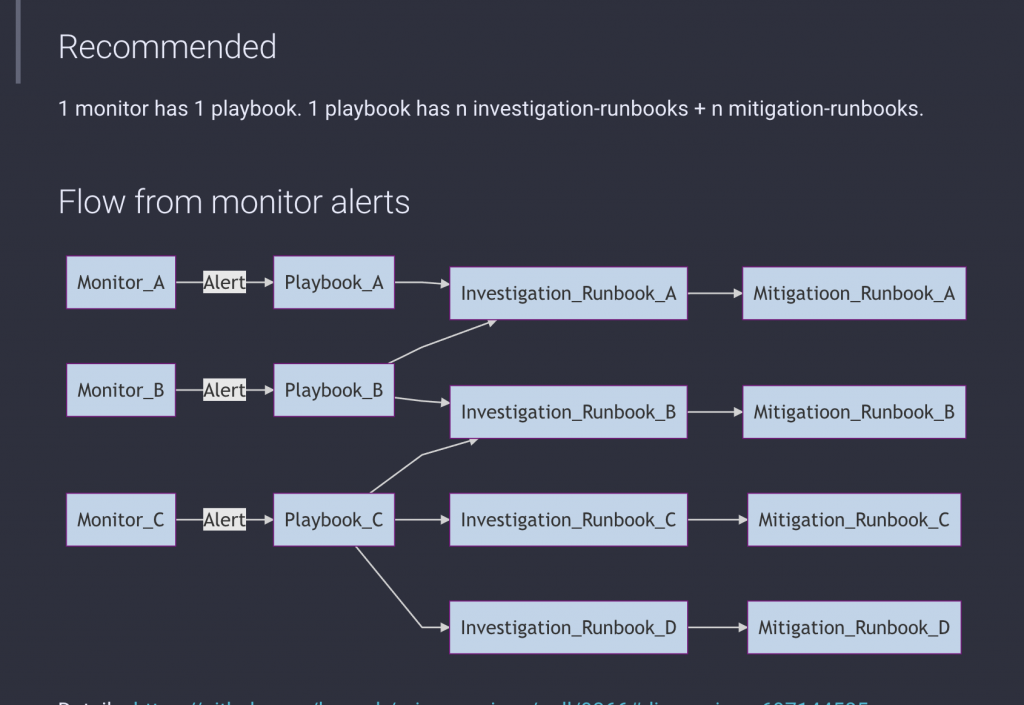
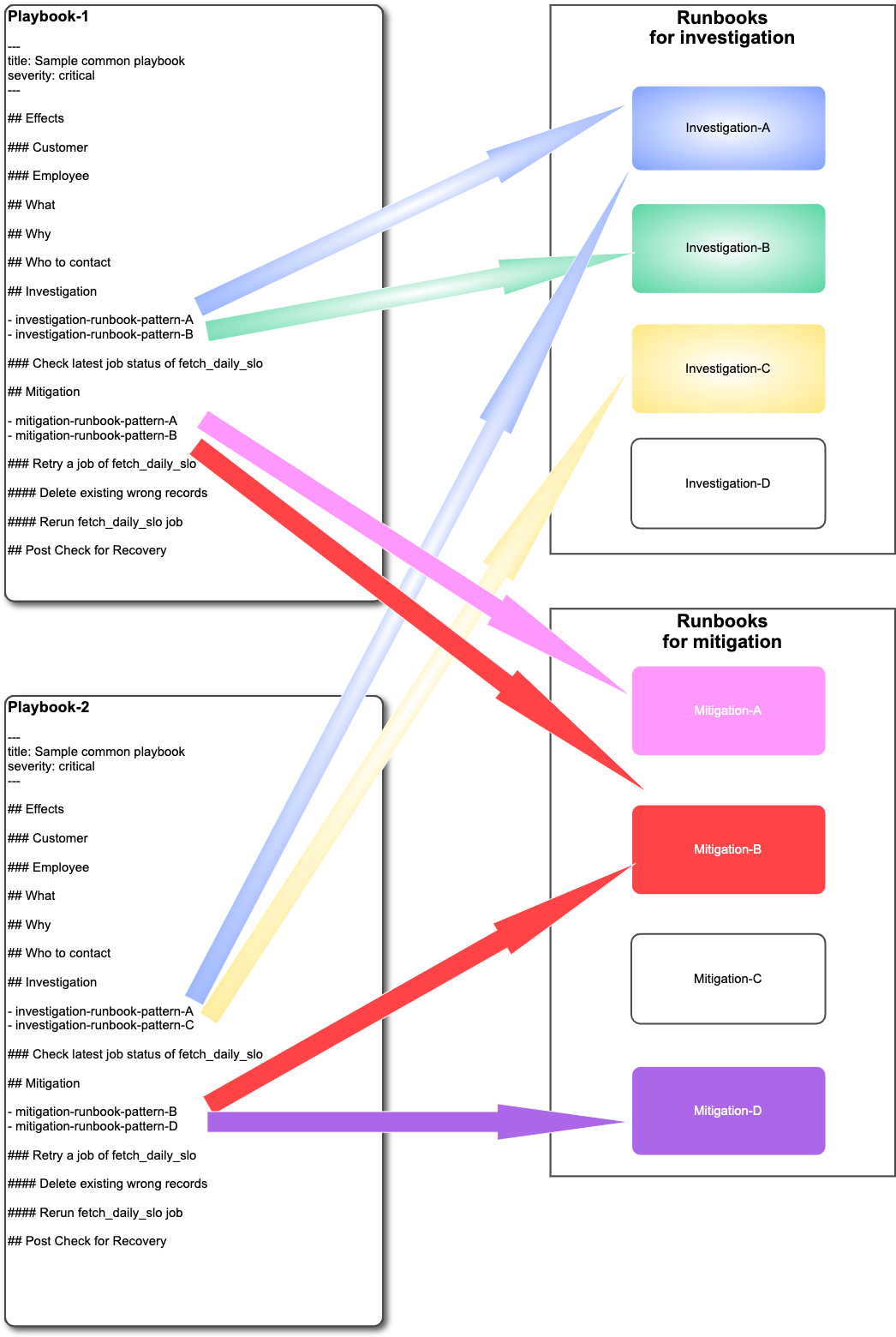
※上記のPlaybookとRunbookのヒントはPager Dutyの ”What is a Runbook?" という記事を参考にしました。
作っているもの
ここまでは組織やマネジメント系の業務事例をあげてきましたが、マイクロサービスにおけるSREサポート作業以外も含めて様々なものを作ったりもします。
例えば以下のようなものを作っていたりもします。
- 各種移行ツール
- Slack bot
- ITGC (Information Technology General Control) / IT統制
- 監査/管理ツールの開発・保守・運用
- サービスの開発に関係するコマンド類
具体的な例で言えば、GoでHeadless browserを使ったサーバーを作成して、それをBuildpacks -> Cloud Runで起動させるものを開発しています。
そこでは以下のような技術スタックが使われています。
- Go
- Buildpacks
- Docker
- Terraform
- Google Cloud Run
- knative
- Google Cloud Scheduler
- Google Secret Manager
個人的には横断的に使えるものを作りたい想いもありますが、我々Microservices SREチームはあくまでEmbedded SREsです。
なので、横断的なものを作る機会よりもEmbedded先のマイクロサービス開発チーム内で何かを作ったりサービスのコードに手を入れるほうが業務としては多い傾向になります。
チームメンバーが増えたらもっと色々チャレンジ出来るようになるかも知れません。
立ち止まらないEmbedded SREsが前提
Microservices SRE は、一箇所に留まらずにサービス開発チームを渡り歩いていくことを前提にしています。
それは、より広い範囲をカバーするという目的もありますが、マイクロサービスやその開発チームに対して、Embedded SREsが足りていないからです。
上記のような理由で、移動した先でSREについて再び知見を広めていくことから、冒頭でも述べたように、伝道師のような性格も持っていることになります。
なお、移動するたびに同じことをしているのかというと、そうでもありません。
近いこともありますが、チームやサービスの特色に合わせる必要があるものは多く存在します。また、退屈な作業は自動化を進めて減らしています。
我々の開発組織にはcampと呼ばれるdivisionがいくつもあります。その中には複数の開発チームが所属しており、連携と管理を円滑にする目的で各チームからバックエンドエンジニアが1〜2名づつ集まり、バックエンドギルドと呼ばれるチーム横断的なグループを作る試みを始めています。(その開発組織体制については、こちらをご覧ください: 【書き起こし】プロダクト開発体制を一挙公開 – Cross-functional team in Mercari )
その一つにギルドメンバーとして最近参加して、複数のマイクロサービス開発チームへのEmbedded SREsにチャレンジしています。
バックエンドギルド内の複数のマイクロサービスは、それぞれで関係性を持っており、その中でEmbedding をRotationしていくことで効率を図る狙いがあります。
詳しくはこの記事の前に投稿された "Embedded SRE at Mercari" にある "Rotation" と "Embedded to the division, instead of the team" の項目で詳しく紹介されているので、そちらも合わせて御覧ください。
最近ではバックエンドギルドの他のメンバーと共に先ほど紹介したPlaybook / Runbookの導入を進めています。
Microservice SREとして活動して感じたメリットとデメリット
しばらくEmbedded SREs をやってきて、その活動のメリットやデメリットが見えてきたので、主観ではありますが、一例として紹介します。
メリット
- マイクロサービス開発メンバーと近い位置で働ける
- 非常に勉強になる
- サービス開発とインフラ両方に関わる
- 楽しい
- 課題をすぐに把握出来る
- 直接貢献しやすい
- インフラからアプリケーションまで調査が捗る
- 良いナレッジコミュニティができる
- 多様性がある
デメリット
- OKR や ミーティング などは多重化しやすい
- SRE向け、マイクロサービス開発向け それぞれに参加しているため
- 認知負荷が高い
さいごに
いかがでしたでしょうか? メルカリの Microservices SRE(Embedded SREs)が実際にどのようなことをやっているのか、少しでも伝わったのなら幸いです。
今回紹介した内容以外にも様々な業務を行っています。
もっと話が聞きたい!という人がいましたらメルカリでは現在 Microservices SREの採用やカジュアル面談を積極的に行っていますので、お気軽にお問い合わせください。




