This article is part of the Developer Productivity Engineering Camp blog series, brought to you by Nathan Essex from the CI/CD team.
Introduction
In Mercari’s Microservices Platform CI/CD Team, we have many components to support. Some of these are production-critical and others are very central to the development process. We have many internal customers using these components, and therefore frequently need to respond to support requests.
As our responsibilities have increased and the company has grown, we need to respond to more requests, in a more timely manner, and with greater care.
This blog post outlines a support workflow that we have recently begun using in the CI/CD team.
Goals
These are some of the goals for this workflow:
- Improve our ability to measure the support process (volume, time to acknowledge etc.)
- Improve internal customer satisfaction with our support
- Document our process so we can iterate, measure and improve over time
- Provide clarity to CI/CD team members about how to respond to support requests
- Facilitate automating parts of the process to reduce support workload
- Leave the workflow design open for usage by other teams
Non-goals
Define a major / large scale incident response workflow
While there is a lot of overlap with these topics, there are many additional details to a major incident response such as assigning incident commanders, communication leads, communication timelines, scheduling people for shifts etc. I’ve chosen to omit most of those details from this workflow to keep things simple enough that they can become routine. We have separate documents explaining how to behave and communicate during a major incident.
There are many high-quality guides on how to handle incident response for major incidents around the internet from the likes of Google, PagerDuty etc. and teams at Mercari use various workflows at least partially derived from those.
Everyday Support Workflow
Principles
We should try to adhere to the following principles when providing any sort of support to our customers.
Honesty
- Be honest about our priorities
- Be candid about our knowledge / experience, especially if we might not be the right people to ultimately resolve the issue
- Give truthful updates when investigating or working on a solution, even if we aren’t succeeding
Empathy
- Keep in mind the impact an issue might be having on our customers, which might include organizational pressure, deadlines, responsibilities etc.
Clarity
- Try to ensure that our customers always have a clear understanding of the situation
- Avoid setting false expectations
Issue Lifecycle
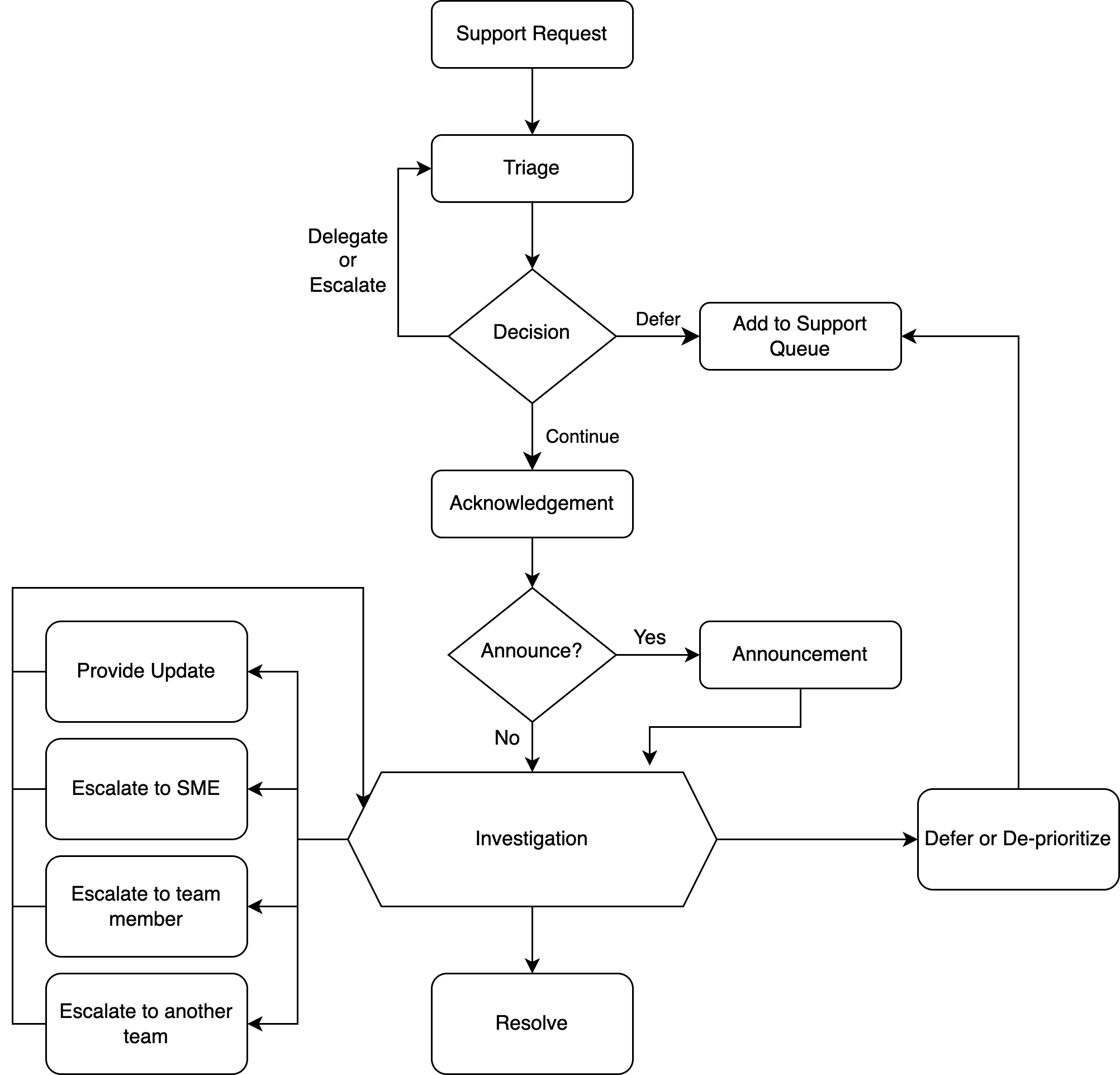
Triage
The goal of triage is to decide which issues should be worked on first. This should happen BEFORE acknowledging the issue, to avoid setting false expectations. But with that in mind, please try to keep triage brief, even if you throw away a bit of accuracy in your assessment to do so. There are four main components of triage:
- Severity: How much of an impact the issue will cause for the business
- Likelihood: How likely is it that people will encounter the issue
- Time to Fix: How long will it take to resolve the issue
- Priority: An estimate based upon the above three components of the priority that should be given to fixing the issue
Note that Time to Fix has an inverse relationship with priority, to prioritize keeping the support queue short.
| Priority (min) | Severity | Likelihood | Time to Fix |
|---|---|---|---|
| 4 | Very low / no impact | 0-25% | >=6 hours |
| 3 | Moderate impact | 25-50% | <6 hours |
| 2 | High impact | 50-75% | <2 hours |
| 1 | Very high impact | 75-100% | <30 mins |
While these are all open to interpretation, and will all be estimates based on limited information, we should get better over time at ensuring tasks have the appropriate values relative to other issues. The relative priority is most important. Severity in particular will vary based on many factors and the ultimate judgment will be based at least partially on intuition / feeling, but consider factors such as the monetary, time or reputation impact for the company, impact on development and day-to-day operations etc. Take a look at other issues if necessary, and estimate relative to those.
Sometimes there may also be multiple issues at a given priority level, and you will have to use your own judgment of the situation to decide which one is more important to work on first.
Decision: Continue or not?
Post-triage, you need to decide whether you commit to working on this issue or not. As a general rule, we should try to avoid actively working on multiple issues at the same time.
Here are some of the options you can choose from:
- Continue: This may involve putting lower priority tasks on-hold so that you can focus entirely on the issue at-hand
- Delegate / Escalate: Actively hand this task over to someone else to be worked on immediately
- Defer: Place this task in the support queue, where you or someone else can pick it up in the future according to priority
In all cases, you (or the person you are delegating / escalating to) should communicate the decision to the customer as soon as possible. See the Acknowledgement guide below.
Acknowledgement
This initial acknowledgement of the issue is particularly important. It should take the form of a Slack message and/or GitHub comment, not just an emoji. Based upon the decision you’ve just made, communicate clearly what will happen next.
- Be honest about any other tasks going on that take priority over this task
- Don’t say you are investigating the issue if you are working on other tasks first, or if you know of other tasks that will take priority
- Try to provide a GitHub tracking issue link in the first acknowledgement
By being candid and honest in this initial acknowledgement we enable a few things:
- We don’t give the customer false expectations
- The customer can seek out help from elsewhere if necessary
- The customer can give us more information about priority if they think it is urgent
- The customer is incentivized to investigate the issue themselves if it is a low priority task and they have the ability to investigate it on their own
Announcement
If an issue you are going to investigate has a high / very high impact or high / very high likelihood of someone encountering the issue, it should be announced broadly.
The communication channels for each company are different, the authors of this guide have a quick reference here mapping topics to Slack channels which is our primary communication medium. It’s highly recommended that you have a table or similar explaining which channels to announce issues in based on the situation. This helps ensure less frequently used communication channels are not forgotten.
Investigation
The details of the investigation will depend upon the situation. This document will not cover the process, as that will depend greatly upon the issue at-hand. However, based upon how the investigation is progressing, you may want to consider some of these options:
- Provide an Update
- Defer or De-prioritize
- Escalation: Hand-over to a Subject Matter Expert
- Escalation: Involve another team member (pair/group work)
- Escalation: Involve another team
- Escalation: Incident Response
- Resolution
- Follow-up Actions
Provide an Update
Updates are critical not just for our customers, but for us as well. We should provide updates in any of the following situations:
- We have identified the root cause of the issue
- We need more information to investigate
- We have resolved / partially resolved / mitigated the issue
- We are de-prioritizing the issue to work on something else
- We will look at the issue another day (e.g. it’s after working hours and not urgent)
- We will hand the issue over to someone else (if they will become the primary point of contact for the issue)
- We are waiting for another team to reply / investigate
Consider your communication channels, particularly if the issue is broadly affecting other teams or has a high severity.
Defer or De-prioritize
If you will stop working on a task for any reason, please communicate that clearly to those involved, including customers, teammates, other teams etc. If possible, provide a timeline for when you expect the task to be picked up again, and make sure there is a clear communication channel for the issue.
This communication channel could take the form of:
- A GitHub issue our team / those impacted can update
- A Slack channel where we can hold further discussions
- A meeting where we can discuss the issue further
Escalation: Hand-over to a Subject Matter Expert
You should involve a Subject Matter Expert if you do not have the required knowledge to investigate or resolve the issue in a timely manner. As a team, we should prioritize learning even during the support process, so don’t always escalate to the SME immediately. However, if an issue has a large impact, high urgency etc. then you should involve an SME in the process. The SME may or may not be a part of your own team.
When escalating to a Subject Matter Expert, you should make very clear whether you will:
- A: Hand-over the task and stop working on it yourself
- B: Work with the SME on the issue
In addition, if you will stop working on the issue and someone else will take over, please communicate this clearly to those involved including customers.
Escalation: Involve another team member (pair/group work)
You can consider involving another team member if you are not making sufficient progress on an issue on your own. Depending on the impact, urgency etc. of the issue, consider involving multiple team members. At the point where you have multiple team members, you should also consider a more coordinated incident response with roles and dedicated communication channels.
Escalation: Involve another team
If another team is more equipped to deal with a certain issue, or the situation requires the involvement of another team, you should try and get them involved as early as possible.
When you involve another team, please make it very clear to your teammates, the other team and your customers if you intend to stop working on the issue yourself.
Escalation: Incident Response
If an issue is particularly severe, or has a broad impact you can consider treating this as a major incident. Along with the regular support process here, you should also consider:
- Create a dedicated support channel in Slack e.g. #tmp-service-incident-1234
- Assign someone as Incident Commander, responsible for coordination
- Assign someone as Comms Lead, responsible for communication (this can be the same as the incident commander for smaller / easier to manage incidents)
- Make a broad announcement directing people to the dedicated support channel
For further details, the authors of this workflow have a separate document for major incident handling. Please see the Non-goals section for why this is kept separate, but it’s recommended you have a documented process for this situation in another document.
Resolution
If you consider an issue to be resolved, please communicate that to the customer explicitly. If the situation warrants it, try to provide a communication channel for re-opening the issue or continuing the discussion.
Follow-up Actions
Following the resolution of an issue, the following are some optional steps that can be taken. These are intended to either prevent the issue from occurring again in the future or document the issue sufficiently such that it can be handled efficiently in the future.
- Documenting how issues were resolved
- Post-mortem (with or without team meeting)
- Playbooks
- Root cause analysis
Measurability
To ensure that we always have a clear high-level picture of our support situation we need measurability.
There are many ways to achieve this, however based upon the established communication channels at Mercari and specifically around the Microservices Platform group, we decided to track support requests in GitHub Issues in a central repository. On top of the issues, we have labels and other metadata.
This allows us to track:
- When a request was made
- When a request was acknowledged (in the issue description)
- When a request was resolved
- Who is involved in the request
- What components are involved in the request (via GitHub labels, to track which components we maintain have the largest support workload)
GitHub was also chosen because it has an excellent API upon which we can automate metrics gathering, issue creation etc.
Automation
With a workflow and metrics now defined, we have to address automation. The exact details of this automation will vary from company-to-company, however you can adapt the details below to your own organization.
We have begun automating this process, however some of the items below are still on the roadmap.
Automate centralizing requests
We’ve found it very important to respond to customers where they contact us. So if that’s a GitHub issue we communicate there primarily, or if it’s a Slack message we communicate in Slack instead. However this runs counter to the measurement requirements above which benefit from centralization.
To enable both continuing the conversation at the initial point of contact, and also centralize request tracking and metrics we built a Slackbot to automate the creation of GitHub issues for a given Slack conversation. This removes the need for us to manually create GitHub issues for each Slack support thread that pops up. The Slackbot is also able to add labels, Slack links and assorted metadata to the issue.
Automate gathering and summarizing support metrics
GitHub Issues do not provide many useful metrics out-of-the-box. To gather data on things like Time to Acknowledge or the number of open support requests, we need additional automation.
The GitHub API allows us to gather this information automatically and feed it anywhere we would like, such as a spreadsheet or an explicit monitoring tool like DataDog where we can also create dashboards and alerts based on the metrics.
Partially automate the hand-over process
The CI/CD team has a weekly schedule for support responsibilities. This means however that sometimes tasks will get moved from one team member to another.
Using the metadata described above, we can present a high-level summary of the support queue automatically to the next support team.
Summary
This outlines the workflow that we have begun following in the Microservices Platform CI/CD Team. It is an evolving document and workflow internally, and will certainly change and improve over time, particularly as other teams begin to derive their own workflows from it.
Regardless of if you follow this example or not, having any defined workflow is a mandatory first step to measuring and improving your support processes over time.
Hiring
Mercari is looking for engineers! If you would like to work with us, please apply for a position that interests you!