※この記事は、"Blog Series of Introduction of Developer Productivity Engineering at Mercari" の一環で書かれています。
はじめに
こんにちは、メルカリMicroservices SREチームの藤本(@jimo1001)です。
私は Embedded SRE としてメルカリJPの検索に関連するマイクロサービスを提供している サーチインフラチームに入り、サービスの信頼性向上やインフラ周りの自動化に従事しています。今回は、メルカリの商品検索の応答性能を維持するための Benchmarking Automation の取り組みについて紹介したいと思います。
検索基盤のアーキテクチャ
まず、検索基盤のアーキテクチャについて簡単に説明します。主要なコンポーネントに絞ってシンプルに表現したものが以下の図になります。
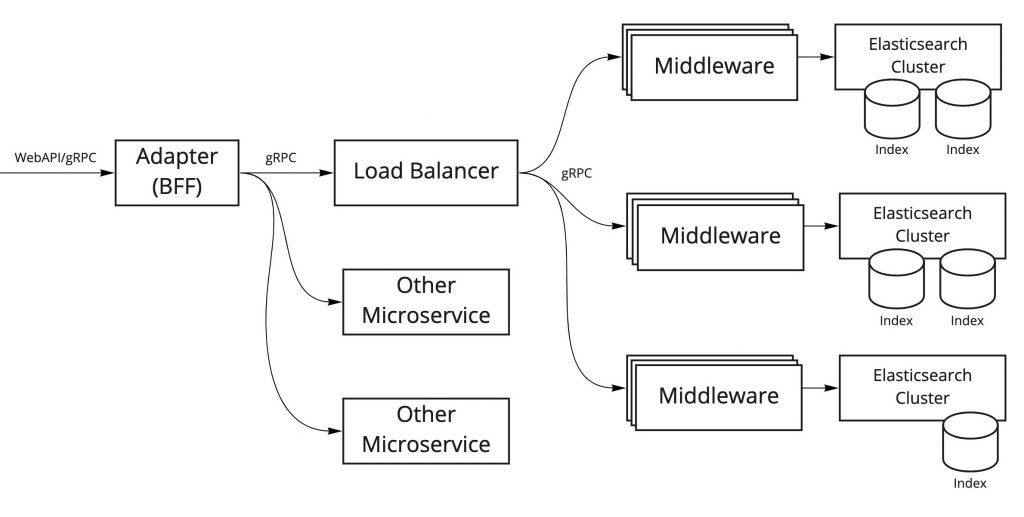
各コンポーネントの役割は以下の通りです。
Elasticsearch Cluster
メルカリでは商品の検索等を実現するために Elasticsearch を使用しています。お客さまの検索体験をより良いものにするために検索内容や検索条件に応じて最適化された Elasticsearch のクラスタおよびインデックスを作成しています。
(Search) Middleware
Elasticsearch と連携する gRPC エンドポイントを提供するコンポーネントで Elasticsearch Cluster 毎に用意しています。このコンポーネント は Elasticsearch の結果を単に返すだけではなく、Re-Ranking など検索に関する様々な汎用的な処理を行うため Search Middleware と表現しています。
Load Balancer
Search Middleware に対するリクエストの負荷分散と各Elasticsearch Cluster に紐づく Middleware のルーティングを行います。Elasticsearch Clusterの再構築や新規リリースの際の Canary リリースにおけるトラフィックコントロールにも使用します。
Adapter (BFF)
Backend For Frontend の役割を担うシステムで、複数の Elasticsearch の結果や他のマイクロサービスのリクエスト結果を処理します。
今回の Benchmarking Automation のターゲットとしているのは、Search Middleware および Elasticsearch Cluster になります。これらのコンポーネントは密接に連携しており、検索の応答性能に直結する部分なので、入念に性能を評価する必要があります。
Benchmarking Automation について
Benchmarking Automation の目的は『検索の応答性能を維持するため』に以下を起因とする性能低下を事前に、または早い段階で検出することにあります。
- Elasticsearch の構成変更(Index のスキーマ変更やElasticsearchバージョンのアップグレードなど)
- Search Middleware の機能変更・追加
- お客さまの商品検索の傾向の変化
また、リリース毎に行う負荷テストの一部の自動化にもつながるため、その工数削減も目的の一つです。
これらを実現するために、
- ベンチマーク(Benchmark Testing)の定期的な自動実行
- 機能開発の場面などでのベンチマークの自動実行
を継続的に行い、ベンチマークの結果の変化に注目します。
ベンチマークの結果は、他の結果と比較して性能の良し悪しを判断するため、以下のように実行時の条件を揃える必要があります。
- ベンチマークのクライアントノードおよびベンチマーク対象ノードの CPU やメモリなどのマシンリソースを固定する
- ベンチマークの条件(秒間リクエスト数、並列実行数、実行時間など)も固定する
また、ベンチマーク実行中にマシンリソースに余裕がある場合は、性能劣化が観測できない可能性が高いため、ベンチマークによる負荷のピーク時に 80 ~ 100% のリソースが使用されるように、マシンリソースとベンチマークの条件を調整する必要がある点に注意しなくてはなりません。
Benchmarking Automation の実行基盤
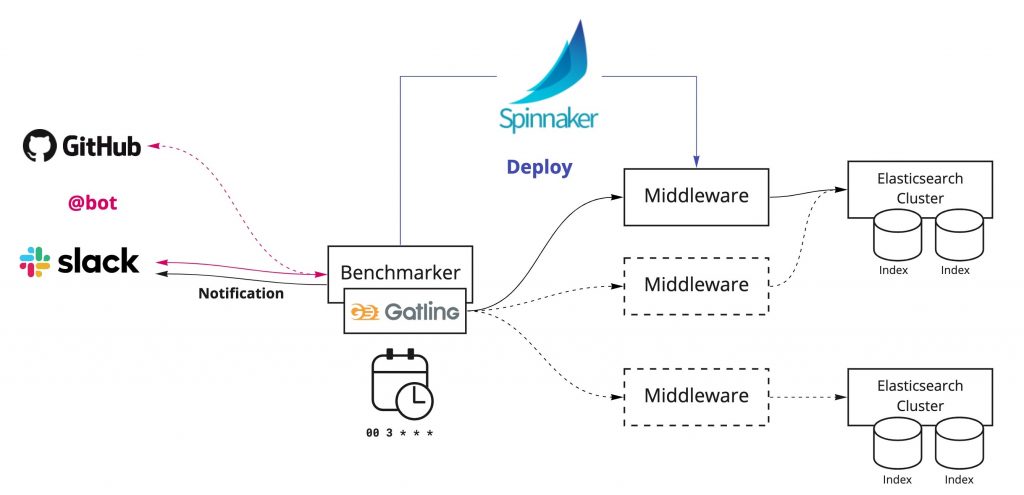
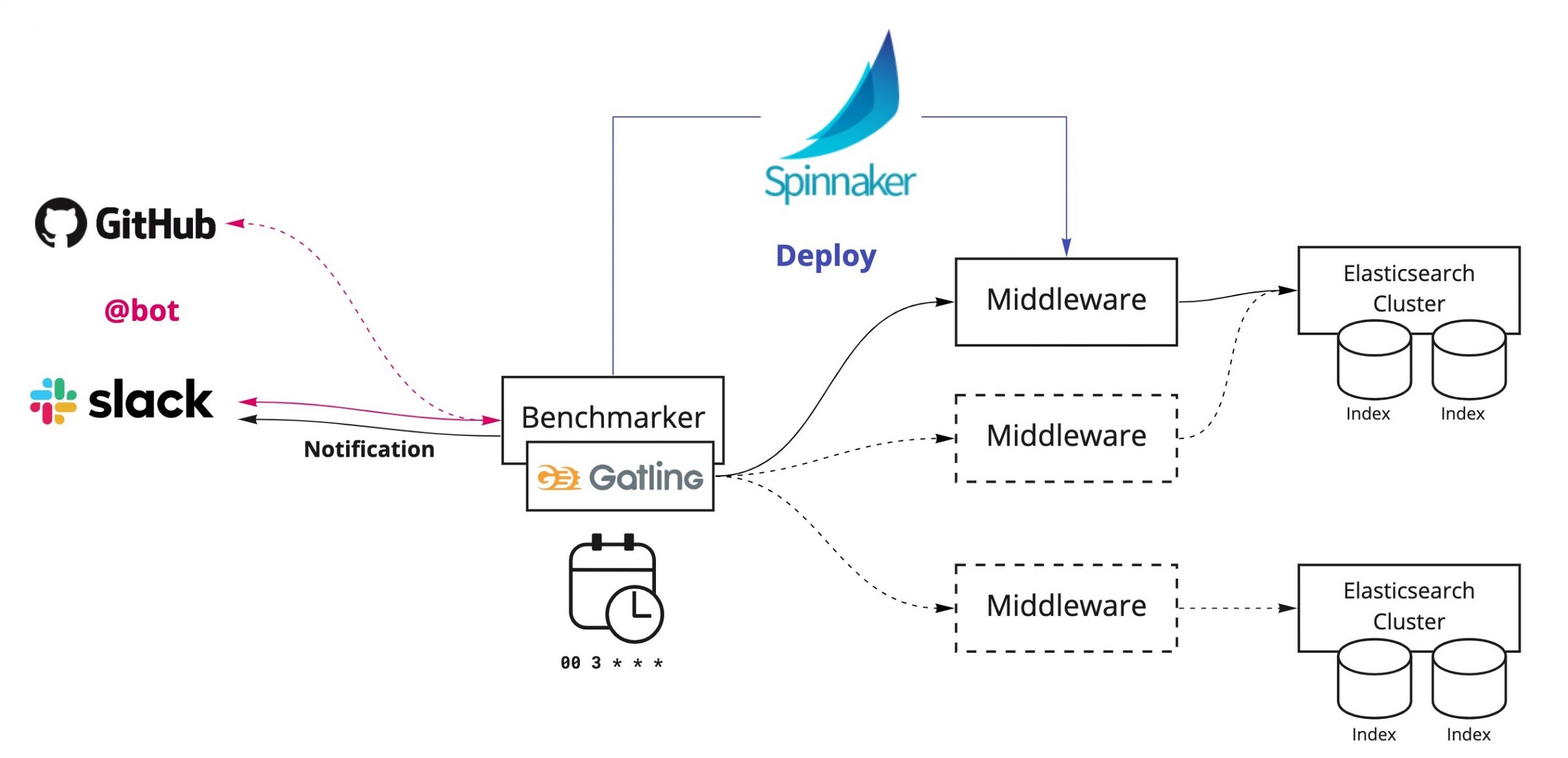
Benchmarking Automation を実現するため、上図のような実行基盤を用意しています。
この基盤の中心となるのは、ベンチマークの実行や結果の通知、外部サービスの連携を行う Benchmarker です。このコンポーネントは、ベンチマークを安定して実行するために、GCP の VM Instance 上に構築し、カーネルパラメータや ulimit のリソース制限の調整をしています。
ベンチマークの実行トリガー
問題の早期発見と原因を特定しやすくするには、細かい粒度で検証する必要があります。なので、ベンチマークの実行手段を充実させることが重要だと考えています。現時点では以下の2つの方法を用意していますが、十分ではないため今後は優先度の高いものから実装していく予定です。
CronJob による定期的な実行
ベンチマークの定期実行には CronJob を使用しています。一日一回決まった時間に実行し、結果を Slack に通知します。
Slack Bot による実行
任意のタイミングでの実行を可能にするため、 Slack からベンチマークを実行できるようにしています。
Spinnaker による自動デプロイ
任意のバージョンの Search Middleware でベンチマークテストを実行するため、Spinnnaker を用いて指定のバージョンを事前にデプロイし、サービスが起動したタイミングで実行します。
Gatling を使用したベンチマークテスト
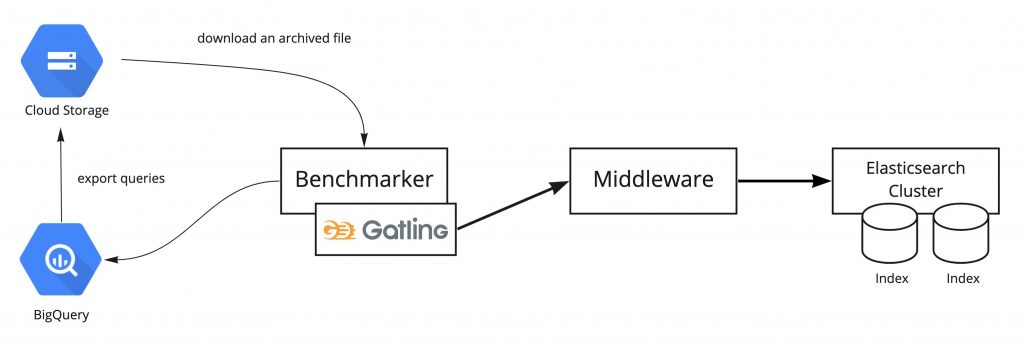
負荷テストツールの Gatling を使用して、検索クエリを並列で Search Middleware へリクエストし、レスポンスタイムやステータスを計測します。Gatling は非常にリッチなHTMLのレポートを生成することができるため、Cloud Storageに保存し、Slackのベンチマーク結果通知から結果のサマリと共に確認できるようにしています。 また、テストに使用する検索クエリは、BigQuery に保存されているクエリログからテストに必要な量のクエリを抽出して Cloud Storage にエクスポートしたものをダウンロードして、ベンチマーク実行時に読み込んでいます。
これから取り組もうとしていること
現時点ではまだまだ開発中で、後述のように、サービス連携やテスト結果の可視化を強化し、使いやすいプラットフォームを目指していきたいです。
ベンチマークスコアの算出
現在は Gatling のテスト結果を通知しているため、一見しただけでは性能の良し悪しが分かり難いという課題があります。テストの結果を正確に反映したベンチマークスコアを計算して提示することで、人にとっても分かりやすく、機械にとってもモニタリングする際などに扱いやすいものになります。
Datadog 連携
Benchmarking Platformのあらゆるメトリクスは Datadog に登録されているため、ベンチマークテスト実行中の CPU 使用率、エラー率、レイテンシなどと一緒にベンチマークテストの推移や結果を同じダッシュボードに表示することで、細かい分析が可能になったり、問題発生時の原因の特定につながると考えています。
GitHub連携
GitHub の Pull Request からベンチマークテストを実行し、その結果が確認できることで、開発の際の性能低下の有無を即座に確認でき、サービス開発のさらなる円滑化につながると期待しています。
最後に
応答性能の低下を素早く検知するための、定期的且つ自動的なベンチマークテストである Benchmarking Automation の取り組みについて紹介しました。
現在は実装中の機能も多く、効果の測定も十分にできていませんが、改めて続報にてお伝えできればと思います。




