
Hello, I’m Tianchen Wang (@Amadeus), a Site Reliability Engineer Intern, working in the Platform/SRE team at Mercari.
In this blog, I’ll detail the project I took part in during my internship period (2023.11 – 2024.1), where I tackled the challenge of migrating service logs to BigQuery tables as a cost-effective manner.
Introduction
Recently, the SRE team started to investigate possible ways to reduce costs at Mercari Shops, because system costs were growing disproportionately to our business growth.
In Mercari Shops, the log data is stored in Google BigQuery and is used to analyze product incidents. We currently use Cloud Logging Sink to export log data into BigQuery tables directly from Google Cloud Logging. Cloud Logging Sink inserts streaming logs into BigQuery tables via small batches in real time, which is called streaming insert. However, as the number of requests and logs have increased, we have found that the cost of streaming insert into BigQuery tables has also significantly increased.
To address this issue, we designed and implemented a more cost-effective method for log data migration. The new method is expected to reduce the entire streaming insert cost substantially.
Streaming Insertion Method
The existing log data migration method was based on the Cloud Logging Sink (streaming insert). Logs generated in Microservices are first stored in Cloud Logging. The data is then transmitted to the specified BigQuery tables in real time through Cloud Logging Sink. This process results in significant costs as we generate a large number of log data every month. This streaming insert cost accounts for more than 68% of the total cost of the Streaming Insertion method, and the cost of data storage is difficult to reduce. Therefore, optimizing the cost of the streaming insert is currently the most pressing issue.
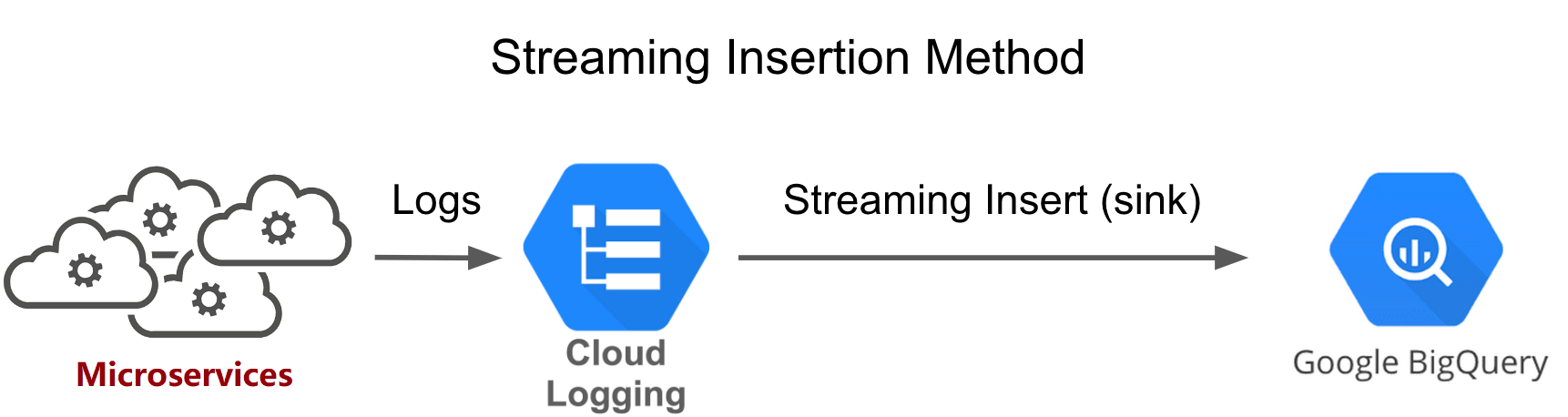
Figure 1: the streaming insertion method
Batch Loading Method
BigQuery External Tables (Rejected Method)
The first idea is to store data in GCS and use BigQuery external tables for querying because loading data to GCS via Logging Sink is free. External tables are similar to standard BigQuery tables but their data resides in an external source.
However, this approach would potentially extend query times by up to a factor of 100 compared to query to the standard BigQuery tables. Additionally, due to the repeated reading of data, the costs of a single query can sometimes exceed $10.
Furthermore, using an external partitioned table preserves the logical partitioning of your data files for query access, which in turn speeds up data querying. The external partitioned data must use a default Hive partitioning layout but Cloud Logging Sink can not apply formats that support partitioning when exporting log data to GCS.
This is why we chose not to utilize external tables for queries.
Batch Loading (Winning Method)
After investigation, we found that in addition to streaming insert, we can also use batch loading to ingest data into BigQuery tables. Unlike the high cost of streaming insert, batch loading is free, although it requires sacrificing the real-time performance of data migration [1]. In fact, it turned out that real-time data is not necessary for our team, and updating the log data every hour is enough. So we planned on using a scheduled workflow to batch load data hourly.
In practical terms, the main difference between the previous implementation and the new batch loading method is that instead of going directly from Cloud Logging to BigQuery, our data is first transferred to GCS buckets. We then periodically batch load the data from GCS to BigQuery via hourly Cloud Run Jobs.

Figure 2: the batch loading method with GCS and Cloud Run
Cost Saving Analysis (Impact)
In order to clearly show the cost reduction and the impact of the Batch Loading method, simulating the cost calculation will be a good way. For all calculations that follow, we will assume that we are dealing with 100TB of raw logs unless otherwise specified. This does not reflect the actual amount that Mercari processes, but it is meant to be a nice reference number to show the actual cost savings. Using this number, implementing the Batch Loading migration method results in the total cost dropping from $8,646 to $2,371.
Cost of Streaming Insertion method
Streaming insert had a cost implication of $0.012 per 200MB [1]. To project the costs for streaming inserting 100TB of logs into BigQuery tables, one would be looking at around $6,291 [2]. Additionally, storing this data within BigQuery incurs a fee of $0.020 per GB. Consequently, the storage expense would have total approximately $2,355 [3].
Hence, managing logs with BigQuery could translate to an expenditure of $8,646 [4] for per 100 TB’s data. This method could result in significantly high costs.
Cost of Batch Loading method
By implementing the Batch Loading method, we are incurring the storage costs for GCS and BigQuery, which happen to be identical at $0.020 per GB. Generally, this cost component will be the same as with the Streaming Insertion method because we remove the data from GCS immediately after loading it into BigQuery. For Cloud Run, if we have 1 vCPU and 1GB memory of migration job, the cost of cloud run is $0.000018 per vCPU-second and $0.000002 per GiB-second [5]. Assuming that the Cloud Run jobs will take 10 minutes each hour, the Cloud Run jobs will take $16 every month [6]. This cost is much smaller than the cost of streaming insert.
Outcome
The outcome is shown in Figure 3 and tables below.
| Streaming Insertion Method | Batch Loading Method | |
|---|---|---|
| Data Load Cost / 100TB | $6,291 (Streaming Insert) | $0 (Batch Loading) |
| Storing Cost / 100TB | $2,355 (BigQuery) | $2,355 (BigQuery + GCS) |
| Job Cost /100TB | $0 | $16 (Hourly Cloud Run Jobs) |
| Total Cost | $8,646 | $2,371 |
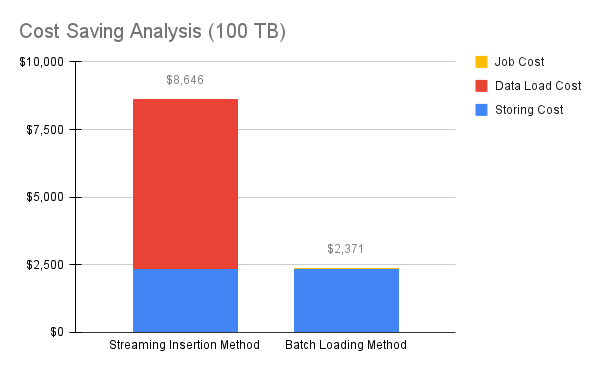
Figure 3: Cost saving analysis
Issues Encountered
We encountered several issues during the implementation of the Batch Loading method.
1. Possible Duplicate Inserts
We sometimes saw duplicate inserts during our hourly Cloud Run Jobs. These were due to the fact that when a job took more than an hour, the next Cloud Run job would start before the previous one had completed, which resulted in duplicate log ingestion. To resolve this, we implemented a locking mechanism to prevent new jobs from running until the ongoing jobs finished.
2. Schema Column Data Type Mismatches
When the auto-schema parameter is set for the bq load command, BigQuery will automatically infer a matching data type based on the loaded data. However BigQuery sometimes misinterprets numeric strings as integers during schema auto-detection. Because of this BigQuery threw errors when it initially misinterpreted the data type for a column as numeric, but subsequently received a string. To address these issues, we decided to manually define the schema for all tables in BigQuery and compare it with the proposed auto-detected schema to rectify discrepancies.
3. bq load Command Succeeded But No Data was Loaded
Sometimes the bq load command produced an empty table even though it reported success. It was later discovered that this was due to the expiration properties of the data [7]. The table had a partition expiration setting of 7 days, and the migrated records were from beyond that period, resulting in their removal from the active partitions of the table. Finally we ignored this issue.
4. bq load Command Failed When the Migrated Data Volume was Too Large
During testing in the PROD environment, accumulated data in GCS caused the bq load command to fail because it exceeded the maximum size per load job of 15TB [8]. To resolve this, we limited the number of files processed by the script and changed the file transfer strategy from transferring the entire folder to selecting specific files.
We encountered the ‘Argument list too long’ issue related to the previous one when selecting specific files for transferring. Specifically, this issue was due to passing many file paths as arguments exceeded the maximum length limit for command arguments, which MAX_ARG_STRLEN defines. To address this, we assessed the maximum length and reduced the number of imported files to ensure that the MAX_ARG_STRLEN limit is not exceeded (131072 bytes) [9].
Internship Impressions
My contributions
I implemented the Batch Loading method in the services of Mercari Shops for both the development and production environments, with details as follows.
- Created BigQuery tables, GCS buckets, Cloud Logging Sink and IAM permission with Terraform.
- Checked the existing schema of BigQuery tables and generated schema files.
- Created Datadog monitor to monitor the failed Cloud Run Jobs and send alerts.
- Discontinued previous migration method by removing existing Cloud Logging Sink.
- Completed runbook and some documents for the Batch Loading method and the issues we have faced before.
Challenge & Improvement
As the only non-Japanese member of the SRE team, it took me some time to adjust to conducting meetings and daily work in Japanese. The members of the team worked hard to communicate with me in easy-to-understand Japanese, and English was the main language when writing daily Pull Requests and documents. After the internship, I felt that my Japanese language skills had improved a lot, which is a very valuable thing for me if I plan to work in Japan in the future.
Before Mercari’s internship, I had no development experience with Terraform, Datadog, GitHub Actions or other SRE-related technology stacks. Using a new technology stack from scratch is also a challenging aspect of this internship. Today, as the internship is coming to an end, I can say that I have some practical experience with the above tools.
I also experienced a difference between Mercari and the two companies that I have previously worked at, which were a startup and a fintech company, respectively. The development experience in Mercari was undoubtedly the best. Multiple sets of automation tools help Engineers simplify the development process and reduce possible human errors. In addition, the strictness of the Pull Request review within the group is also different from previous internships. I think starting a career from Mercari is a great option for New Grads.
Work Experience
As my fourth internship, Mercari stands out as the most tech-centric environment I’ve been a part of. It’s a place where engineers are provided with an optimal development experience, enabling them to create incredible products that unleash the potential in all people.
Mercari’s Culture and Mission breathe through our day-to-day work; faced with options, team members consistently favor boldness and the pursuit of meaningful impact, even at the risk of failure.
Additionally, the monthly intern dinners hosted by our Teaching Assistants have been excellent networking opportunities, allowing me to forge new friendships and engage with other teams. I also had the privilege of participating in Mercari’s year-end party, an experience rich in Japanese tradition and a wonderful way to immerse myself in the company culture.

Figure 4: Year end party
Advice for new interns
During my internship I found that effective communication was crucial, especially when not using my native language. So it’s best to do everything you can to let your mentors and managers know your progress, challenges, and other issues. You can also take the initiative to engage in 1on1 and cafe chat with team members to deepen your relationship.
Other than that, I recommend staying bold. Everyone in the company will try to help you, so why not try something more challenging? This will help you grow quickly.
In Closing
I eagerly anticipate the chance to leverage internship opportunities to gain exposure to various companies and explore different roles during my time as a student. Such experiences are bound to leave a profoundly positive mark on my career trajectory. Without question, Mercari has provided me with an unparalleled internship experience. I must also extend my gratitude to my manager, mentor and team members for their patience with my errors and their willingness to respond to my inquiries. My heartfelt thanks to all!
Mercari is currently recruiting for interns throughout the year, so if you are interested, please apply below!
Students | Mercari Careers
Acknowledgment
I’d like to acknowledge @ganezasan, who laid the groundwork for this project through his initial design and investigative efforts. And also acknowledge @G0G0BIKE, who mentored me and gave plenty of meaningful feedback in my internship period.
Reference
[1] https://cloud.google.com/bigquery/pricing#data_ingestion_pricing
[2] $0.012 × (100TB × 1024 × 1024 / 200MB)
[3] $0.023 × 100TB × 1024
[4] $6,291 + $2,355
[5] https://cloud.google.com/run/pricing
[6] $0.000038 × 600s × 24h × 30d
[7] https://stackoverflow.com/questions/25452207/bigquery-load-job-said-successful-but-data-did-not-get-loaded-into-table
[8] https://cloud.google.com/bigquery/quotas#load_jobs
[9] https://www.in-ulm.de/~mascheck/various/argmax/




