
Creating labels for machine learning is hard and time consuming, wouldn’t it be nice to train a model without any? We can with self-supervised learning!
I’m Paul Willot from the AI/ML team and in this post I’ll introduce an experiment we did to get rid of labels by leveraging the structure of Mercari’s data.
Let’s dive in!
Self-supervised learning
Self-supervised learning, or SSL for short, is a training method free of external supervision. Instead labels are generated from a proxy task. Solving this task will require the model to learn a representation, usable for downstream applications.
The difficulty is of course to define that proxy task! But before showing how to create one let’s see why SSL might be useful in the first place.
Why SSL?
In short: collecting good labels is hard, but raw data is plentiful. SSL allows us to use a large dataset to bootstrap a model, then fine-tune on only a few high quality samples.
Let’s make a concrete example.
As a Mercari user, when selling an item I can select the category that best describes it, making my item easier to find for buyers. However, picking the correct category is cumbersome. Machine Learning (ML) can help by suggesting likely categories directly from the item pictures. We can define this problem as a simple classification objective, a common ML task. Good!
However the existing categories, our labels, might have a few issues. Notably class imbalance, label noise (picking among many is hard) and ambiguity as some items straddle categories. The model will also learn a task specific representation, which might be hard to transfer to other tasks.
Those issues come from the need for labels, so not needing any would be great. That’s where self-supervised learning can help!
Defining a proxy task
Various proxy tasks have been crafted for SSL, like solving jigsaw puzzles or predicting an image rotation. Recent state of the art methods have focused on simpler proxy, like randomly augmented images, in which the task is defined as obtaining consistent representations despite visual deformations.
For example, in the image of a golden retriever below, after alterations each transformed image (called a view) still contains a recognizable part of the dog.

Augmented views
Choosing which augmentations to apply is not easy however. We need to make it hard enough for the model to learn a useful representation, but not too hard that it becomes impossible. Augmentations add design choices and picking the right ones is an ongoing research topic.
Ideally, we would like to use existing views.

Natural views
Luckily we have billions of those at Mercari!
When selling, uploading pictures from multiple angles improves buyers’ appreciation, so the large majority of listings have multiple views. We call them natural views, as they are taken to show multiple aspects of an item in a natural context.
We can note that between views, more than just the camera angle might change, for example the shoes above are positioned differently on the box. This is good! We want the model to learn a common representation that is not tied to a particular pose.
Some sets of views might be harder to associate, for example an item and it’s enclosing box photographed separately. In practice this was not an issue for us as those are relatively rare.
Contrastive learning
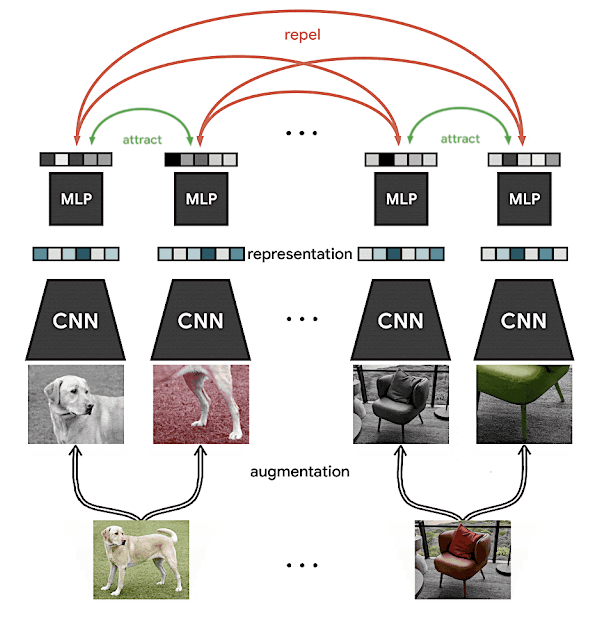
Contrastive learning on a pair of images (credit: SimCLR)
Now with those views, we can define a learning objective through contrastive learning, that is: the same views should produce representations that are more similar, and different views should produce representations that are dissimilar. Visually, we can imagine representations of views of the same item being pushed closer together, and of different items being pushed apart, as the figure above illustrates.
Note that "embedding" and "representation" are used interchangeably in the litterature, both stand for a 1 dimensional scalar vector in a SSL context.
Contrastive learning is related to siamese networks, an older ML technique, but has regained popularity in the last two years with numerous methods narrowing the gap with supervised training on the ImageNet benchmark. This SimCLR blog post is a good place to go deeper.
Introduced by the Bootstrap your own latent paper, momentum based methods have also appeared recently. They simplify the implementation by using only positive pairs and address the issue of large batches. I recommend the SimSiam paper to understand momentum learning.
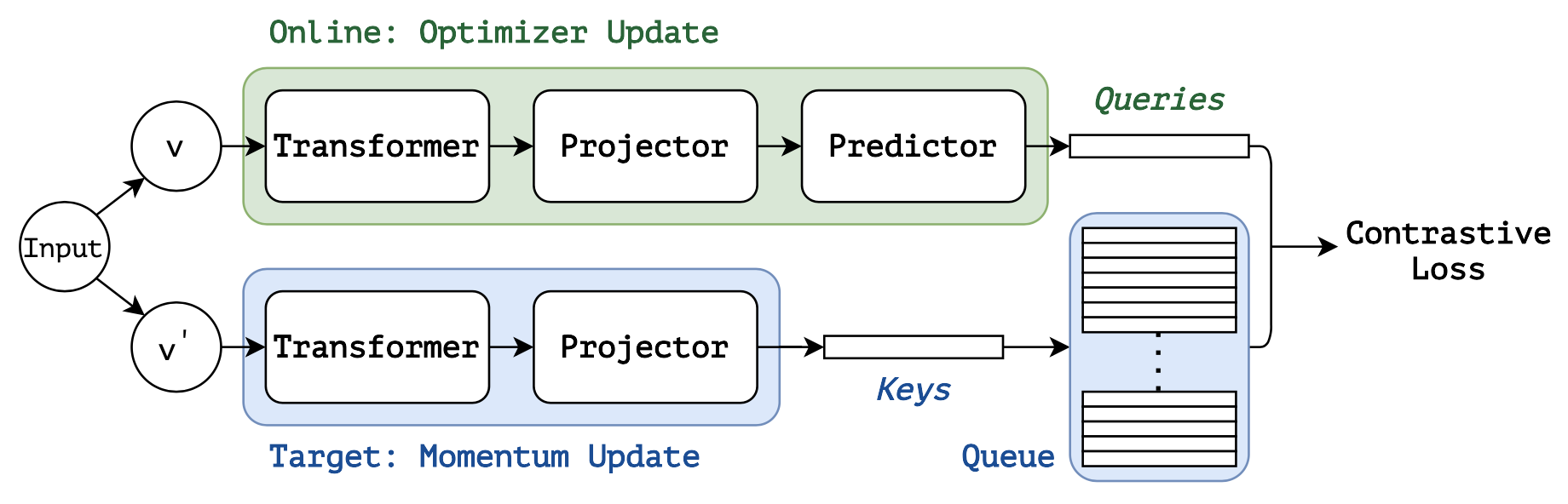
SSL with contrastive loss and momentum, aka MoBY (credit: Self-Supervised Learning with Swin Transformers)
Latest research even combines the two, like MoBY that we used in our experiment.
The key point in these methods is that we can create models that obtain a consistent representation of the subject across multiple views.
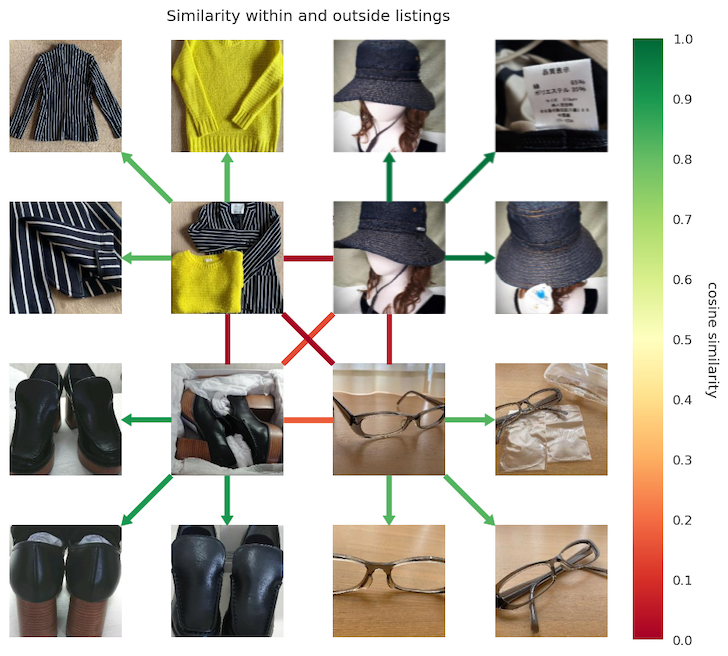
Distance between representations of views within and outside listings.Each quadrant is one listing, the innermost links are between listings green = similar, red = dissimilar
We were able to confirm this in our dataset, as shown above. After training, items within a listing are more similar than across listings, even with large changes in poses or a tight zoom on an object detail.
Regarding training, a few tips that helped during our experiment:
- Large datasets are necessary for any non-trivial task; think millions of samples
- For training, with pre-trained weights you can get by with a couple of GPU-days, otherwise a couple of weeks
- Large models are easier to train, ResNet-50 is still a solid baseline in 2021
- A simple method goes a long way, start with SimSiam
- SSL is neat but if you already have labels, use them! It will be more accurate and faster to train
Using the learned representation
We have a few ways to develop downstream applications using the representations obtained from these images
Using labels, we can train a specialized model on top of the learned embeddings, which will require fewer samples as the input space is smaller and simpler (compared to raw images).
We can also do a nearest neighbor search by looking at the closest representations to infer the properties of a sample. The advantage is that we don’t need further training, and we can leverage any attributes of our neighbors even if poorly structured.
We could compute the cosine similarity (or other divergence measure) between each sample pairs directly, but at Mercari’s scale it quickly become computationally intractable. Instead we can leverage existing vector database search like FAISS or ScaNN to search millions of samples in a few milliseconds.
Conclusion
Even without labels we can train a useful model by leveraging the existing structure of our data.
At mercari we leverage ML across the board, from pricing recommendation, fraud detection, customer profile customization, object detection at the edge… and much more. Obtaining a general representation directly from images and without costly labels is a helpful tool to address those diverse tasks.
Thank you for reading!




