This article is the 14th entry in the Mercari Bold Challenge Month.
Hello everyone, I’m Kengo (@karolis_ml) and I’m with Mercari this summer as a software engineering intern in the AI Engineering team in Tokyo. In this blog post, I’d like to present the experimental results on information fusion techniques in multimodal modelling in the context of prohibited items detection at Mercari JP.
TL;DR
- Machine learning is essential for a scalable prohibited items detection system
- Simple concatenation of feature vectors still a strong baseline for information fusion
- Max Pooling demonstrated to be effective for feature selection across modalities
- Gated Multimodal Units (GMU), an attention-based mechanism for assigning weights to different modalities, outperforms baseline and provides explainability
Managing Risks at Scale
A platform as sizeable as Mercari inevitably attracts a small but certain fraction of bad agents on both sides of the marketplace in buyers and sellers, and one such example is prohibited items being listed by malicious sellers including drugs, counterfeit goods, cash, medical devices, and many more. A comprehensive list of prohibited items can be found here (JP) and here (EN).
Not only does this behavior present legal risks to the users and the platform, it undermines the ecosystem as a whole when it comes to the sense of trust and safety once these items are seen as tolerated by the platform. Ideally, these prohibited items should not be allowed to enter the marketplace in the first place or taken off of the marketplace as quickly as possible, but the sheer volume of listings with over 13 million MAU makes this process extremely cumbersome and costly to manually deal with.
Here comes in the power of machine learning. Automatic detection of these prohibited items with machine learning helps identify previously undetected items with rule-based systems as well as reducing the cost of customer support. As the cost of false positives where a legitimate item is mistakenly considered as illegitimate is quite high in terms of user experience and customer support, our key metric to focus on is precision. This is to ensure that the items the model predicts to be prohibited are actually prohibited.
In solving this problem of binary classification, we first note that listings at Mercari consist of several components including an image of the item, title, description, price, and item condition and so on. As we build a neural network that takes all these factors into account, we need to somehow represent these features as an input vector that can be fed into machine learning models, and information fusion techniques are primarily concerned with how we combine these different modalities in such a way that we can extract information from them more effectively. With this in mind, I will first outline key methods and then results and implications from experiments for one specific category of prohibited items at Mercari.
Preliminaries
In the literature of multimodal learning, a common baseline for information fusion is to simply concatenate feature vectors across different modalities such as images and texts, which is surprisingly performant in various multimodal tasks. Concatenation was adopted as the baseline in previous experiments at Mercari also in similar settings (see References at the bottom of this post). Other simple yet powerful methods are element-wise linear sum/multiplication for each unit in a fully connected layer of common size (e.g. 512). Nonetheless, these element-wise operations are often limited in expressiveness as some noisy modalities could clutter the entire feature vectors.
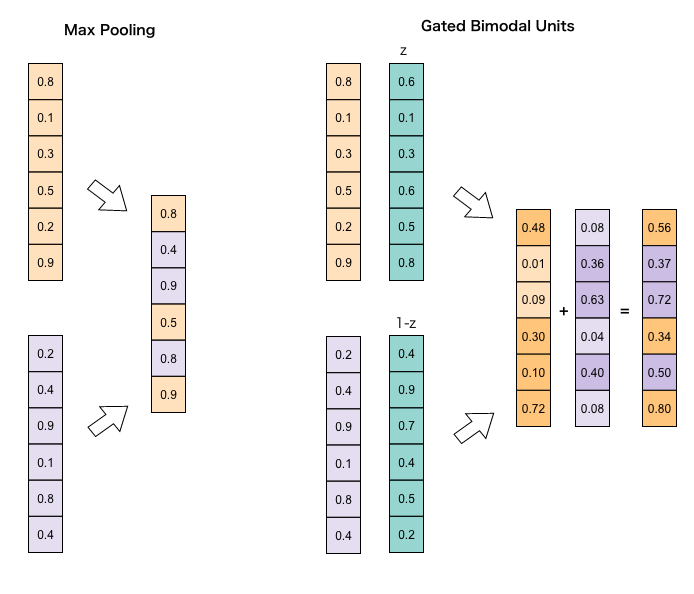
Our main methods of interest are max pooling and Gated Multimodal Units (GMU) as illustrated in Figure 1. One of our previous experiments demonstrated that max pooling helps identify informative units among multiple layers with different modalities, as empirically shown by Duong et al. (2017). GMU proposed by Arevalo et al. (2017), on the other hand, learns weights for each unit in a layer of given modality, in a manner that resembles the attention mechanism. This can be considered as a continuous version of max pooling with units being averaged over with continuous weights, instead of simply assigning a weight of 1.0 to one modality over the other. In Figure 1, weights for inputs in the first modality shown in the upper half are represented by z, and, in this bimodal case, the other modality is assigned weights of 1-z.

Before diving into our own data, we first replicated the results of the paper by reimplementing GMU in PyTorch based on authors’ original implementation in Theano using their preprocessed multimodal dataset from IMDb.com, solving a task of movie genre classification with posters as visual input and titles and descriptions as text input.
Besides the GMU’s competitive performance against the baseline (concatenate) and other existing methods, attention for the feature vector of common size was calculated using the hyperbolic tangent function. In this setting, z indicates the weights of units from the visual input, and Figure 2 from the paper shows the percentage of units that are activated with z more than 0.5 for visual input and less than or equal to 0.5 for text input. Crucially, we confirmed in our environment that genres “animation”, “family”, and “musical” do have a higher percentage of activations than other genres for the visual input, which is sensible in that these movies, especially animation, tend to have a distinctive format or designs in their posters. This provides additional model explainability as we humans have an intuitive and often better understanding of what factors differentiate one class from the other regardless of modalities.

Experiments
Figure 3 illustrates an overview of multimodal modelling with three modalities in our setting at Mercari for prohibited items detection; image, text, and meta information (auxiliary). Features are extracted with sklearn’s TF-IDF Vectorizer for text and pre-trained InceptionV3 for images. Note that while concatenation can be performed on vectors with different lengths (e.g. (n, 4096) for image and (n, 300) for text to create (n, 4396)), other information fusion methods first need to set up a linear layer to align the dimensions (e.g. 512). Here, we pay particular attention to the bimodal fusion mechanism between image and text as indicated in red in Figure 3, where auxiliary features are simply added to the features via concatenation after the first information fusion. This is simply due to the fact that auxiliary features are rather small in dimensions and known to be less informative compared to the other two.
As per the implementation by Arevalo et al. (2017), we added batch normalization and maxout for GMU and max pooling. Since the effect of data normalization was demonstrated in our previous experiment linked above, we trained a different model without batch normalization to reexamine this effect. Additionally, we also included LinearSum (i.e. element-wise sum) as another method for a linear information fusion mechanism, following the experiments by the authors.
Due to the imbalance between prohibited items (positive class) and legitimate items (negative class) in Mercari’s listings, we downsampled the negative pool to match the size of the positive class. Models are written in TensorFlow to fit into our ML platform, and training the neural networks took 5-6 hours for each model on NVIDIA Tesla V100 with the best model chosen based on the validation loss.

Results
The following table summarizes model performance with average precision scores evaluated over an unseen 7-day testing data, as well as precision and recall scores. Negative class was downsampled such that the ratio between positive and negative is 1:3 for each day.
In terms of performance, max pooling trumps other models with average precision of 0.8634 followed by GMU at 0.8631, while concatenation still proving to be a strong baseline at 0.8239. This confirms Kiela et al. (2018)‘s additional experiments on multimodal-IMDb dataset which was originally provided by Arevalo et al. (2017), where max pooling outperforms GMU by a small margin in the task of movie genre classification with a weighted F-score of 0.6220 against the GMU’s 0.6180.
Despite its simplicity, LinearSum also appears to fare well at 0.8420, and this is also in line with Arevalo et al (2017)’s results where LinearSum trails the weighted F-score of GMU by a bit while exceeding the baseline, which we replicated in our environment.
Interestingly, whereas GMU with batch normalization is almost as performant as max pooling, the same model without batch normalization lags behind LinearSum in terms of average precision. This seems to show that, as our past experiment has similarly illuminated, normalization of inputs plays a vital role in information fusion.

Notably, we also extracted weights for each modality in the testing dataset, and confirmed that text has much higher weights than images in this specific category of prohibited items, with the split between the two at around 0.92 for text and 0.08 for images. As the authors demonstrated in Figure 2, we also examined the difference in weights by conditioning on a certain binary attribute X in the testing dataset. We know for a fact that this attribute X has a differential effect on how certain images are presented in this category of specific items, and, as it turns out, images are given higher weights if this attribute takes a value of 1. This indicates that the GMU is properly adjusting weights for certain items where features from one modality are more informative.
Moving Forward
The main implication from the findings above is that the weighting mechanism provides a better understanding of the model on top of its superiority over the baseline method of concatenation, which leads to insights as to how to improve performance. One example is that more sophisticated preprocessing and feature extraction methods for the text features will likely improve the overall performance, given that the weight assigned to text is quite high and that we have a rather simple feature extraction technique with tokenization, normalization, and TF-IDF. In fact, our previous experiment illustrates the superiority of the DARTS-based network with the character-level embeddings for the text input, and an approach like this would definitely be a good start.
Another important takeaway is that having weights for different modalities is also useful in selecting an appropriate number of modalities to use as inputs, especially when some modalities such as images and videos are computationally costly. For instance, while using a visual input might contribute to the model’s performance by an infinitesimal margin, it might not make business sense to deploy a model that is significantly larger and hence harder to maintain.
On top of the superiority in performance compared to the common baseline of concatenation, the explainability provided by an information fusion mechanism like GMU hopefully helps with the exacting task of iterating through different model specifications and preprocessing techniques in other multimodal problems at Mercari and beyond.
Thank you for reading this blog post. If you’re keen on this topic, please take a look at our past experiments and relevant papers shown below, and stay tuned for more updates from the AI Engineering team!
References
- Arevalo, John; Solorio, Thamar; Montes-y-Gómez, Manuel; González, Fabio A. (2017) Gated Multimodal Units for Information Fusion, ArXiv:1702.01992
- Thang Duong, Chi; Lebret, Remi; Aberer, Karl (2017) Multimodal Classification for Analysing Social Media, arXiv:1708.02099
- Kiela, D.; Grave, E.; Joulin, A.; Mikolov, T. (2018) Efficient Large-Scale Multi-Modal Classification arXiv:1708.02099
- マルチモーダルモデルによる不正出品の検知 – Mercari Engineering Blog
- Using neural architecture search to automate multimodal modeling for prohibited item detection – Mercari Engineering Blog




