This post is for Day 19 of Mercari Advent Calendar 2022, brought to you by Daniel Lameyer from the Mercari US Data Reliability Engineering team.

Introductions
Mercari US Data Engineering is responsible for many essential pipelines that provide the data for many teams and products such as machine learning, business intelligence, accounting, and marketing.
Every year, the data footprint at Mercari US expands in the cloud, and Data Engineers will need to apply the principles of DevOps and SRE to scale with it and enable developers to still be able to take on data projects with our partners.
In order to successfully do so, the Data Reliability Engineering team is here to monitor, automate and manage pipelines to enable our partner USDE teams to have the ease of mind to tackle projects to help Mercari move forward.
What is Data Reliability Engineering?
Data Reliability engineering evolved as a specialization in Data Engineering by applying the principles of DevOps and Site Reliability Engineering to manage data infrastructure.
Like software, data can break in countless different ways; from data quality issues, missing records, duplication, missed updates, access issues, and many more. Although we cannot avoid all incidents, we can significantly reduce the likelihood and reduce the average time to resolution when they do occur.
Data Reliability Engineers (DREs) establish intelligent monitoring and data testing to improve the observability of the essential data processes. They build processes like CI/CD and automate away manual procedures that can cause issues to the system from human error. DREs will also establish systems to recover and secure data for whenever disaster strikes.
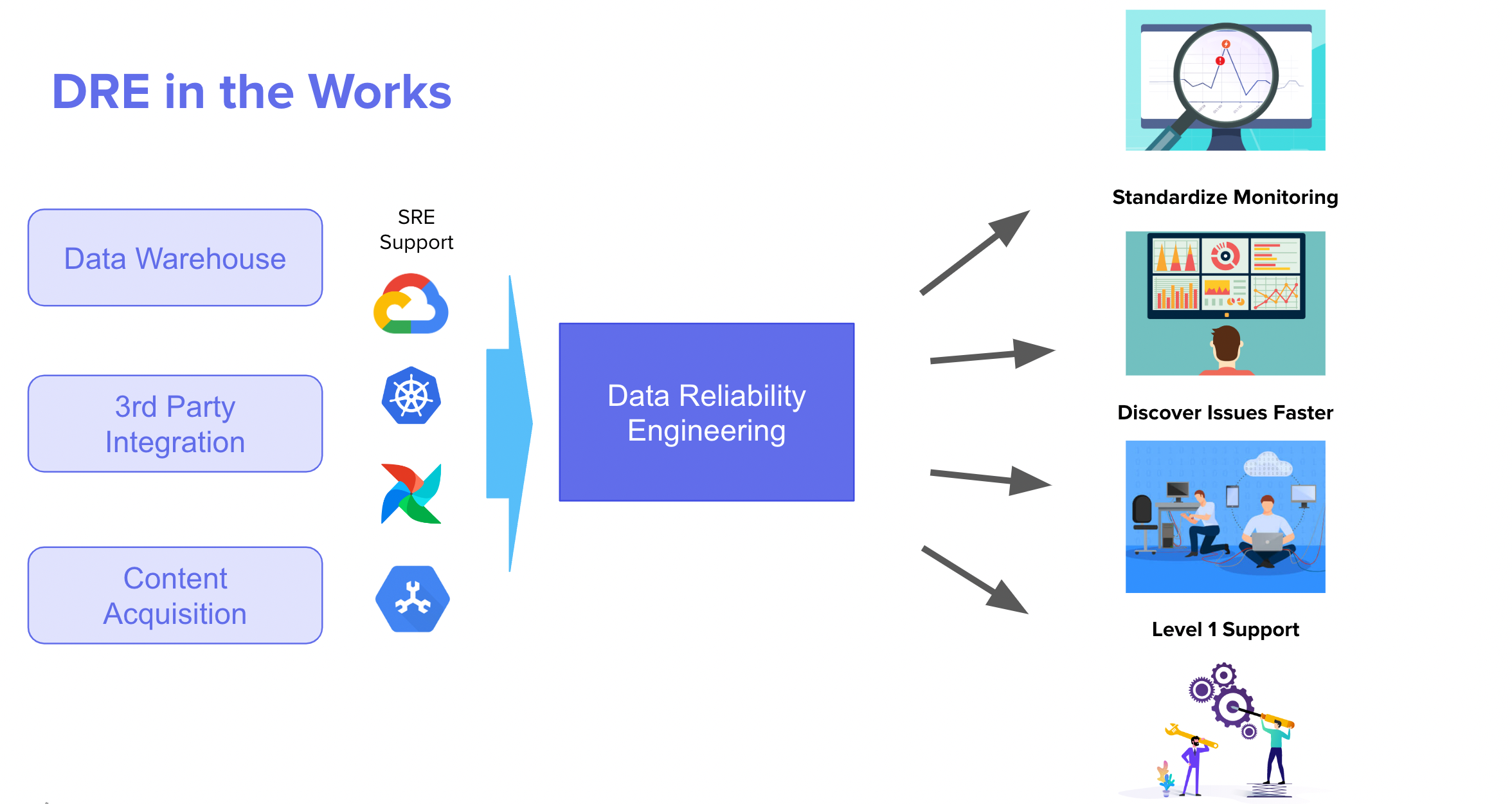
DRE in Mercari US Data Engineering
In July of this year, US Data Engineering (USDE) expanded into four focused teams; Data Warehouse, Third Party Data Integration, Content Acquisition & Knowledge , and Data Reliability Engineering.
Before Mercari US DRE team was formed, each of the Data Engineers was responsible for developing data pipelines (the automation of extracting, transforming and loading of data) along with managing the infrastructure, security, monitoring, and support across the entire portfolio. Without a dedicated focus to address all the operational responsibilities of managing data infrastructure, there were many challenges to reach the level of excellence needed to provide the level of support required by the business. Now with a dedicated team focused on Data Reliability, specialized data engineers can work on what they do best without worrying about all the operational and technical maintenance surrounding data pipelines.
Out the gate, the Mercari DRE team had four core objectives to expand the capabilities of the Data Engineering organizations
- Onboard and Establish Level 1 Support for Data Pipelines
- Modernize Data Pipeline Infrastructure
- Proliferate Data Operations, and Monitoring Practices
- Secure access to Customer Data
We are proud of the accomplishments we made this year on these key areas and will outline the details below.
1 – Onboard and Establish Level 1 Support for Data Pipelines
USDE is responsible for many core processes that stream raw data from the application databases, and make them available in a comprehensive data warehouse for Mercari employees to gain access for their projects. To ensure that an appropriate level of focus and support is being provided to the pipelines, DRE is the first line of defense for these core business. DRE has set up a system of onboarding, training and recording knowledge transfer in a detailed catalog to ensure developers in USDE are fully aware of how to support our complicated systems. DRE will be the first to be alerted when there are issues with the pipeline or data anomalies in the end dataset, and will troubleshoot and triage to quickly lead to resolution.

2 – Modernize Data Pipeline Infrastructure
Technology evolves at a rapid rate, and a key responsibility of engineers is to keep up with the latest tools so that the experience of developers and end users can improve over time. One new service we are excited about in Google Cloud is GCP Data Fusion which is a fully managed UI based data pipeline tool that natively integrates across GCP products, and enables fast ingestion of large datasets thanks to DataProc (Apache Spark) running behind the scenes.
DRE focused on creating a dedicated instance in the USDE space to enable the development of other systems such as a Data Quality Framework, Data Backfill Processes, as well as simpler ways to expose Cloud Spanner Instances into Big Query. By adopting Data Fusion in GCP we believe USDE can create more reliable data processes as well as faster recovery time when there are issues in the data.

3 – Proliferate Data Operations, and Monitoring Practices
Managing hundreds of production tables is extremely challenging, especially when you have a small team actively working on many projects and cannot provide the level of monitoring needed to each dataset. To address this, one of the most exciting tools we have adopted this year is MonteCarlo Data, which is a SaaS provider that monitors cloud data warehouses for anomalies in datasets utilizing machine learning detection.
By setting up MonteCarlo within our data warehouses, the service automatically creates monitors for all tables to create a baseline for expected behavior and alerts when there are anomalies related to updates, row counts, and schema changes. This saves countless hours of manual effort required to achieve this level of observability.
These ML driven monitors have already saved many impactful incidents from occurring thanks to the quick alerts by MonteCarlo. One example includes anomaly detections on key pipelines where odd distributions of field data that were caused by bugs in our app. Multiple data issues in our data warehouse were also avoided by having these monitors to detect unusual data update schedules and table row counts that would not typically be captured by simple monitors waiting for errors and failures. If it were not for these alerts, it may have taken many hours before an end user realized an issue to report back to the engineers. We are able to resolve issues before our stakeholders can experience an issue.
DRE streamlined the alerts from MonteCarlo, and created custom monitors to focus on the datasets of interest. With greater observability and reduced noise of automatic alerts, the USDE organization can better react to the incidents of impact to quickly recover data outages. US DRE is integrating MonteCarlo, GCP Monitoring, Slack and PagerDuty to mature the support structure around our data.
4 -Secure Access to Customer data
As stewards of data for Mercari, the DRE team takes the security of access to datasets seriously. Our customers trust Mercari with their identity and sensitive data, and it is our responsibility to provide the highest standards to meet that expectations. One of our key accomplishments is providing governance and systems to help keep data access in compliance to regulations and auditing around PII access. All PII fields in our GCP data warehouse are protected under specific tags so that only Mercari employees with approved usage can access.
This allows developers and analysts access to datasets to accomplish their project goals, while at the same time withholding access to very specific field level access, thereby protecting our customers. The DRE team has also partnered with the Compliance team to thoroughly review PII access requests so that data is managed responsibly and true to the approved management of the information. We continue to streamline these processes to improve the developer experience to access the data they need while simultaneously keeping data protected from exposure.

Summary
We in Mercari USDE Data Reliability Engineering team are proud of the accomplishments we made this year having only formed 5 months ago. We rallied around these 4 goals and believe that the data infrastructure is in better condition to support our products and data team to accomplish more in 2023. There are still many opportunities for Data Reliability Engineering practices to mature here at Mercari, and our team is excited to take on the challenges head on.
Thank you all for taking the time to take an interest in our journey! We enjoy talking about our experiences and sharing them with the tech community. If you are interested to learn more, please feel free to reach out to the Data Reliability Engineering team: Takako Ohshima, Xi Zhou, Daniel Morita Lameyer, Mark Robinson
Up next for our Advent Calendar Blogpost, stay tuned for an exciting article by Sahil Khokhar!