こんにちは、メルカリUS でData Engineerをしている @hatone です。
メルカリUSのData Engineering Team(DEチーム) では、MLやBI、会計、マーケティングなど、多岐にわたるチームとプロダクトにデータを提供する必要不可欠なパイプラインを担当しています。
今年の7月に Data Reliability Engineering Team (DRE: データ信頼性エンジニアリングチーム) というチームを立ち上げました。日々増え続けるDB上のレコードとそのデータの活用を滞りなく実現するため、Data Engineeringに対しDevOpsとSREの原則を適用することでスケールさせていこうとしています。
Mercari Advent Calendar 2022 の19日目では、チーム各々が安心してデータを利用できるようプロジェクトパイプラインの監視・自動化・管理など、私たちチームで行っているDREのお話をします。
@daniel によるEnglish Version。

Data Reliability Engineeringとは?
Data Reliability Engineering (DRE) は、”データインフラの管理に対して、DevOpsとSite Reliability Engineering(SRE)の原則を適用する、データエンジニアリングの専門分野”と私たちは定義しています。
DB上のレコードは、思いがけないケースで壊れることがあります。データ品質の問題、レコードの欠落、重複、更新漏れ、アクセスの問題など、様々な問題があります。APIやパイプラインの実装によってレコードが変わるだけで、ドミノ倒しのように、関連するテーブルが壊れていき、そして原因を究明するには時間が必要になりがちでした。
DREでは、データの生成プロセスの観測可能性を向上に重きをおいて、より早くインシデントを検知し、データ障害が起きたとしてもその傷口がより浅くなるように目指しています。またCI/CDのようにパイプラインを構築し、ヒューマンエラーを引き起こす可能性のある手動な手順を徹底的に自動化しています。
すべてのインシデントを回避することはできませんが、それでも、その可能性を大幅に低減し、解決までの平均時間を短縮させることに繋がります。
メルカリUS、DREチームはじめました
メルカリUSでは、前述したようにMLエンジニア、データサイエンティスト、アナリストなどプロフェッショナル達がデータを活用して価値を創造しています。しかし、その求めているデータが望んだ形式で生成されていなかったり、データそのものが不正確なために作業をやり直して長時間待ったり、問題を調査するために長時間かかってしまったり…….。「欲しかったデータがDB上に適切にあり不安なく使える状態となっていれば、その日一日気持ちよく働けたのに」と歯がゆい日もありました。
DREチームが結成する前のDEチームでは、データパイプラインの要件定義・開発・監視・障害対応を全てやっていました。データパイプラインの開発に重きをおいてスピード感を実現していたのですがGCPのCloud ComposerのGKE上のpod操作、Data ProcのSparkクラスタのチューニング、MySQLとBigQueryのパイプラインのためのProxyなど関連するインフラタスクを専任とする人間がおらず、障害対応に対して属人化してしまう状況が長く続いていました。
2022年初頭よりDEチーム内での専属の運用チームを作るという動きがはじまりました。これまで、データレイクを開発するData Warehouseチーム、広告や決済会社のシステムのデータを利用するパイプラインを作る 3d-party integrationチーム、蓄積したデータを活用したシステムを開発するContent Acquisition & Knowledgeチームの3チームがありました。7月にメンバーがジョインし、DREチームが立ち上がりました。現在はEM @markrobinsonのもと、@hatone, @Dan M.L @Xi Zhou のチームです。
Data Engineering Teamが提供するデータの質を向上させるために、次の4つを主に実施しています
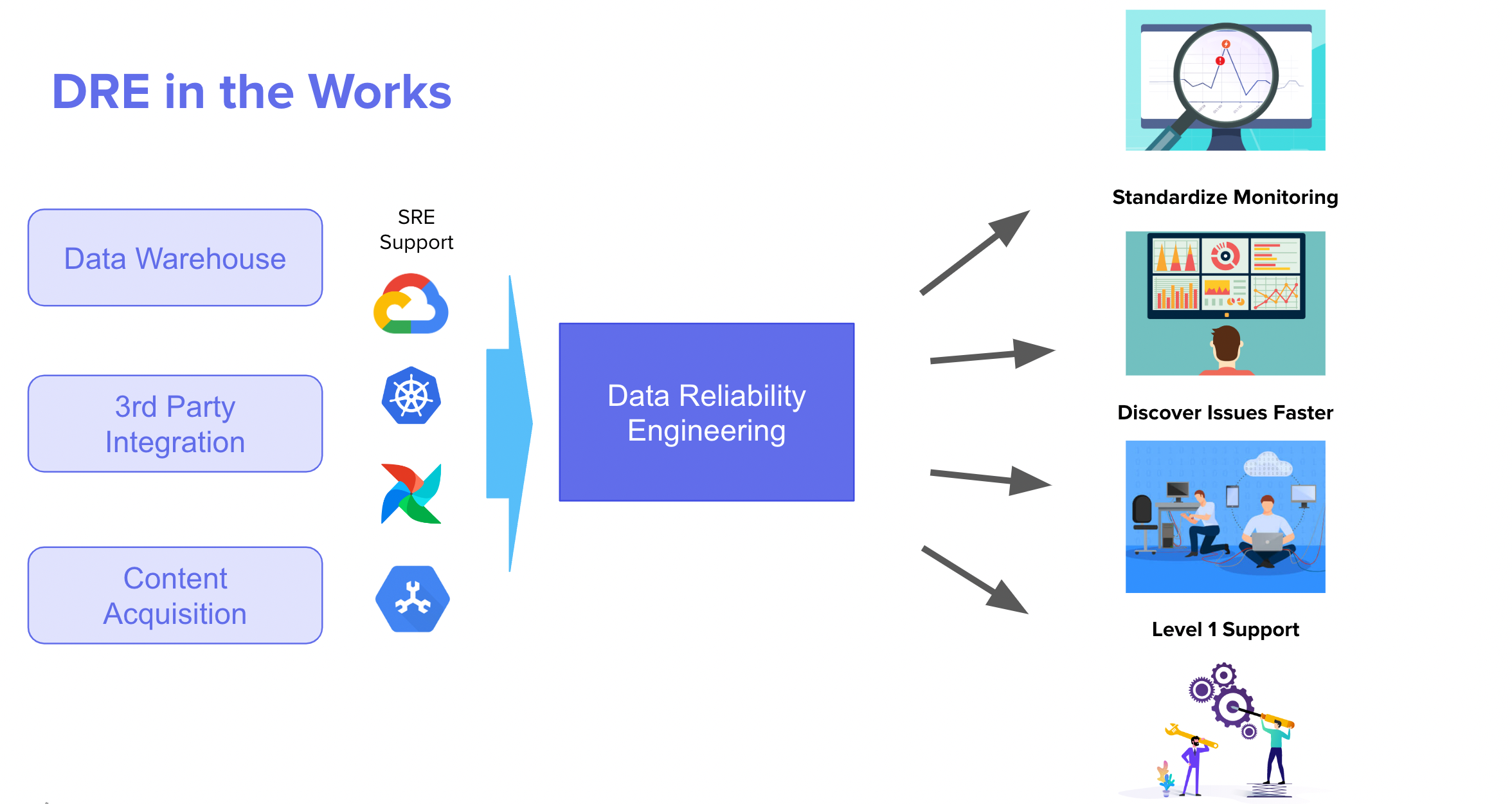
- データパイプラインのオンボーディングとレベル1サポート
- インフラの改善
- データ運用と監視
- お客様情報のセキュアアクセスの担保
1 – データパイプラインのレベル1サポート
DREチームでは、バックエンドチームが開発するMercari Double LogのPipelineや、Data WarehouseチームによるMySQLのbinlogをストリーム処理してデータウェアハウスを作るためのCDC Pipelinesなど、サービスのコアとなっているパイプラインに対する防衛線の役割をしています。GCPのCloud MonitoringとPagerDutyを用いて、パイプラインに問題がある場合やデータの異常がある場合、真っ先にアラートを受けてトラブルシューティングとトリアージをしています。
それだけではなく、DEチームの各パイプラインに対して、テンプレート化した引き継ぎドキュメントの作成サポート、オンボーディングのセッション録画など、DREチームのメンバーだけではなく他のエンジニアが開発・障害対応のサポートを出来るよう、後回しになりがちだった知見のカタログ化を徹底しています。

2 – インフラの改善
GCPのアップデートは目まぐるしく、開発したパイプラインがちょっと気を抜くと陳腐化していきます。GCPのData Fusionは、フルマネージのCDAPです。DREチームでは、DEチーム向けにData Fusionインスタンスを構築し、そこでデータクオリティフレームワーク、パイプラインのバックフィル、Cloud Spanner内のレコードをBig Queryへ転送するなどをバラバラになりがちなパイプラインをまとめて管理しはじめました。
会計向けのパイプラインの例としては、Data Fusionの各ジョブ実行ごとにData Procクラスターを作るのではなく、Cloud Composerでインスタンスを立ち上げて各実行を管理しています。

Data Fusion上のタスクは、jsonで定義できるため、その定義ファイルをgithub上のリポジトリで管理しCircle CI経由でデプロイ出来るようにしています。メンテナンスが追いついていないパイプラインなどを、現在はそこへ移行させています。またCloud Composerのバージョンアップの管理も担当しています。
3 – データ運用と監視
DREチームでは、MonteCarlo、GCP Monitoring、Slack、PagerDutyを統合して、データ周辺を守る体制を強めています。特にDREのツールボックスの中核を担っているのは、MonteCarlo Dataです。

少人数のチームで、多岐にわたるデータセットを必要なレベルで監視するのは、なかなか困難でした。MonteCarlo Dataはデータウェアハウスのデータセットの異常を監視するSaaSで、DREチームではMonteCarloが検知したアラートにフィードバックを与えながら効率化させ、さらに重要なデータセットにはカスタムモニターを作成して監視しています。
もともとDEチーム向けにMonteCarloは導入していたのですが、機械学習モデルによるアラートが多く、精度もあまり高くなく、使いづらい状態でした。
DREチームが出来てからは、日々のデイリーMTGの時間を使ってチーム全員でMonteCarloのアラートを精査し、その結果フィードバックを適切に与えることで観測可能性が高まり、自動アラートのノイズが減少して、インシデントの検知がしやすくなりました。これによって日々手作業で監視していた項目が減り、かなり時間が短縮されました。

これまでデータを利用していたチームが問題に気がついてエンジニアへ報告するまで何時間もかかっていたような障害、例えばバグにより特定カラムのデータ分布がおかしいケース(特定のカラムが通常よりもXX%ほどNullになっているなど)、データ更新スケジュールや更新される行数が通常と異なるケースなどを検知することで、データ障害の規模を小さくすることが出来るようになりました。
4 -お客様情報の秘匿化
DREチームは、開発業務だけではなくプロセスの整備にも力を入れています。これまで、個人情報をマスクした分析/調査用のDBであるAnonDBというMySQLのレプリカがありました。このAnonDBだけではなく、BigQueryのニーズが急増しました。
AnonDB同様に個人情報をマスクするべく、BigQuery上にあるデータウェアハウスの個人情報が含まれるカラムは、全てポリシータグでアクセスを制限し、少数の許可された社員だけがアクセスできるようになっています。また社員による個人情報データへのアクセスのリクエストは、DREチームとコンプライアンスチームが連携し、リクエスト内容の審査と承認するプロセスを整えました。

終わりに
DREチームは結成してまだ5ヶ月ですが、技術面・プロセス面の両方からデータの信頼性を担保していくべくアプローチをし、2022年内にデータ周辺の改善成果を色々出すことができました。「2023年は、ここを改善したいね」という話題で日々盛り上がっています。関連するチームが安心してデータを使えるように、パイプラインの監視、自動化、管理を行っていきます。メルカリ USでのData Reliability Engineeringの知見を積み上げていく機会がまだまだあり、チームで課題をみつけて真正面から取り組んでいきます。
DREチームの挑戦に興味を持ってくださり、ありがとうございました!これからもチームで知見を積み上げ、技術コミュニティへどんどん発信していきたいと考えています。もっとお話が気になる方は、メルカリUS Data Reliability Engineeringチームまでお気軽にお問い合わせください。
Takako Ohshima, Xi Zhou, Daniel Morita Lameyer, Mark Robinson
この記事はEnglish Versionもあります。もしご興味あれば、ぜひどうぞ!
Mercari Advent Calendar 2022 の20日は、 Sahil Khokhaの記事です。お楽しみに。




