
I’m @manami-n, a Software Engineer Intern in the Machine Learning team at Souzoh.
In this article, I introduce how my internship went and the task, which is the verification of a machine learning model (price estimation model) for proposing "Smart Price" (売れやすい価格) to customers.
Overview of my task
Souzoh provides a service called Mercari Shops.
Mercari Shops is a service that allows sole traders and individuals to have their shop and sell their products easily within Mercari, which can be easily viewed and purchased from the "Shops" tab in the Mercari app.
Customers often have difficulty setting prices when listing their items on the market.
Mercari already has a function that automatically suggests "Smart Price" to solve this problem. We are currently investigating the possibility of introducing such a machine-learning price suggestion function to Mercari Shops. This time I examined how accurate the price estimation model can be with Mercari Shops data.
For this validation, the model in the past Kaggle competition, “Mercari Price Suggestion Challenge", organised by Mercari for the accuracy of price estimation models, was used.
The dataset for this competition was from Mercari US when Mercari Shops did not yet exist. However, the properties of the Mercari Shops data, which can be sold as a shop, may differ from the Mercari JP and US data, which are sold as individuals. Therefore, we ran the training on actual Mercari Shops data to verify the results.
Price Estimation Model
Here are the details of the inside of the model referred to.
For validation of the model, in running the training several times to adjust the batch size and number of Epochs, I decided to keep logging using a callback. The logging made it possible to draw the data in TensorBoard together with the previous data, facilitating comparisons.
RMSLE was calculated and used as a reasonable valuation for this Price Estimation model.
The graph below shows an experiment comparing the number of Batch counts when training is rotated on the same data set, drawn in TensorBoard.
The warm colours are validation data, and the cold colours are training data.


Evaluation and discussion of the Price Estimation models.
Another validation was then carried out on indicators that could be used to determine whether to introduce the feature itself.
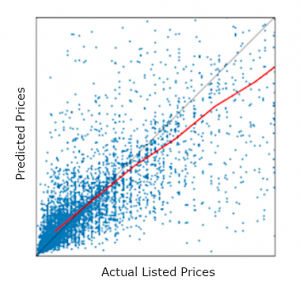
As a method, the difference between the actual listing price and the predicted price of the price estimation model was drawn.

The closer the black line, the closer the actual listing price is to the predicted price.
The red line groups products with close actual listing prices (x-axis) and plots the average predicted price (y-axis).
Initially, a line was plotted that approximated the whole range to a single straight line, but this was heavily influenced by a small number of high price data sets, as the error for products with large prices was calculated to a large extent. Therefore, it was difficult to determine the overall trend by simply plotting a one-dimensional approximate line, and a decision was made to take an average for each range.
At this point, I decided to check the predicted trends for each category, as I thought the trends for different products in each category might be very different.
For example, for listings related to the clothing, the figure below shows the predictions. The figure seems mostly correct for low-priced items, which are frequently listed.
On the other hand, food category has a high concentration of lower-price listings.
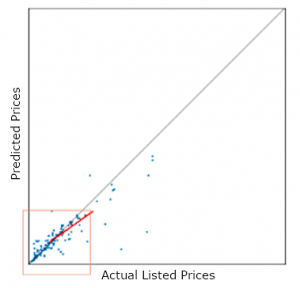
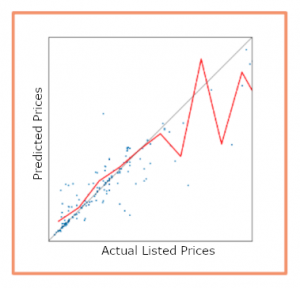
A further narrowing of the scope looks at trends at the lower end of the range.
Lower-price items seem to be correctly predicted, but the items on the higher-price range seem less well predicted since there are fewer data.
One interesting piece of this research is that the trend of predictions differs between "make-up" and "cosmetics".
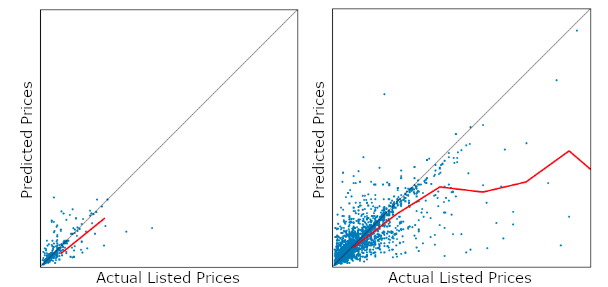
As a genre, "make-up" is a sub-category of cosmetics.
Here, we saw outliers in cosmetics entries, where luxury brand perfumes were not correctly predicted in many cases.
This can be attributed to the fact that Mercari Shops currently does not have a section for registering the content quantity when listing an item. In many cases, the application asks you to describe it in the title or details section. For this reason, the model cannot learn the content quantity and number of pieces as a numerical feature separately from the title, etc., and there seems to be room for improvement here.
Summary
What I did:
- Validated the Price Estimation Model with data from Mercari Shops.
Improvements discovered:
- The average forecast is reasonable and mostly accurate, especially in the lower price range, but there is room for improvement in forecasting the higher price range.
- There are significant deviations from the trend when looked at by category and individually.
Proposed Improvement:
- It may be possible to change the product content that customers are asked to fill in. The price estimation model is often affected by not recognising the content quantity or number of units, which affects the prediction.
Impressions of the internships
It was only a month and a half period, but a great learning experience thanks to my mentor and the team’s tremendous support!
One example of what I learnt is the construction of the environment. However, as I did not replace it often, I had little opportunity to consider environmental construction. My personal PC at the university was not in a good state environmentally, with many things installed frantically, using pip and brew after trial and error in the learning process.
This time, as an intern, I received a company PC that was in a clean state, so the questions pondered in my mind about good environment construction, such as “What is a good environment construction?”; “Are there any valuable extentions?”
The Machine Learning team at Souzoh uses pyenv and Poetry to build their environment. pyenv’s advantage is that it allows you to deploy a specific version of the Python runtime environment that you specify.
Furthermore, you can store multiple versions in different directories and switch between them so that you can change the environment for various projects. In addition, your teammates can easily reproduce the same development environment by installing the packages described in pyproject.toml in Poetry to the Python runtime environment prepared in pyenv.
The “environment breaks” also occurred, and we had the opportunity to try to rebuild the environment many times, which resulted in a good learning experience, as we could understand what pyenv and poetry were, which we had never heard of at first. I think this is the knowledge that I could not have gained without experiencing corporate team development.
I suffered a lot on many other issues, such as the process of code refactoring, but my mentor @nao wrote an article (Japanese only) to teach me, and with the team’s help in online meetings and Slack, I managed to progress with the task.
It is true what other interns have written in their blogs about the environment that allows remote work, such as Slack communication. Still, I thought it was a very comfortable company to work for, where I could enjoy coming to work and genuinely choose how to work.
I also had the opportunity to interact with people from outside the team. I learnt a lot from the open company culture and the friendly way they spoke to me, even though I was only an intern for a short time.
I set the goals when interviewing for this internship after the Build@mercari training programme.
- Gain experience and insight through real work that cannot be found in university.
- Listen to different people and explore my career path in years to come
As a result, it was a very productive period of learning.
This environment allows you to align your tasks with what you want to do before the internship starts. It is a suitable environment for those with some learning and a vision of gaining practical experience in this field.
So…this is the end of my article and internship! Thank you!



