* This article is a translation of the Japanese article written on April 28, 2022.
This article is for day 19 of Merpay Tech Openness Month 2022.
Hello. This is @gouki, a software engineer at Merpay.
In this article, I discuss the machine learning pipeline incorporating manual confirmation used by the Merpay ML Team.
What is a machine learning pipeline?
Merpay provides a deferred payment service called Merpay Smart Payment.
We use an ML model for this to determine credit limits ("credit model" below). We regularly use updated data to retrain and update the model, use the updated model to perform inference processing, and then update credit limits based on the results of inference processing.

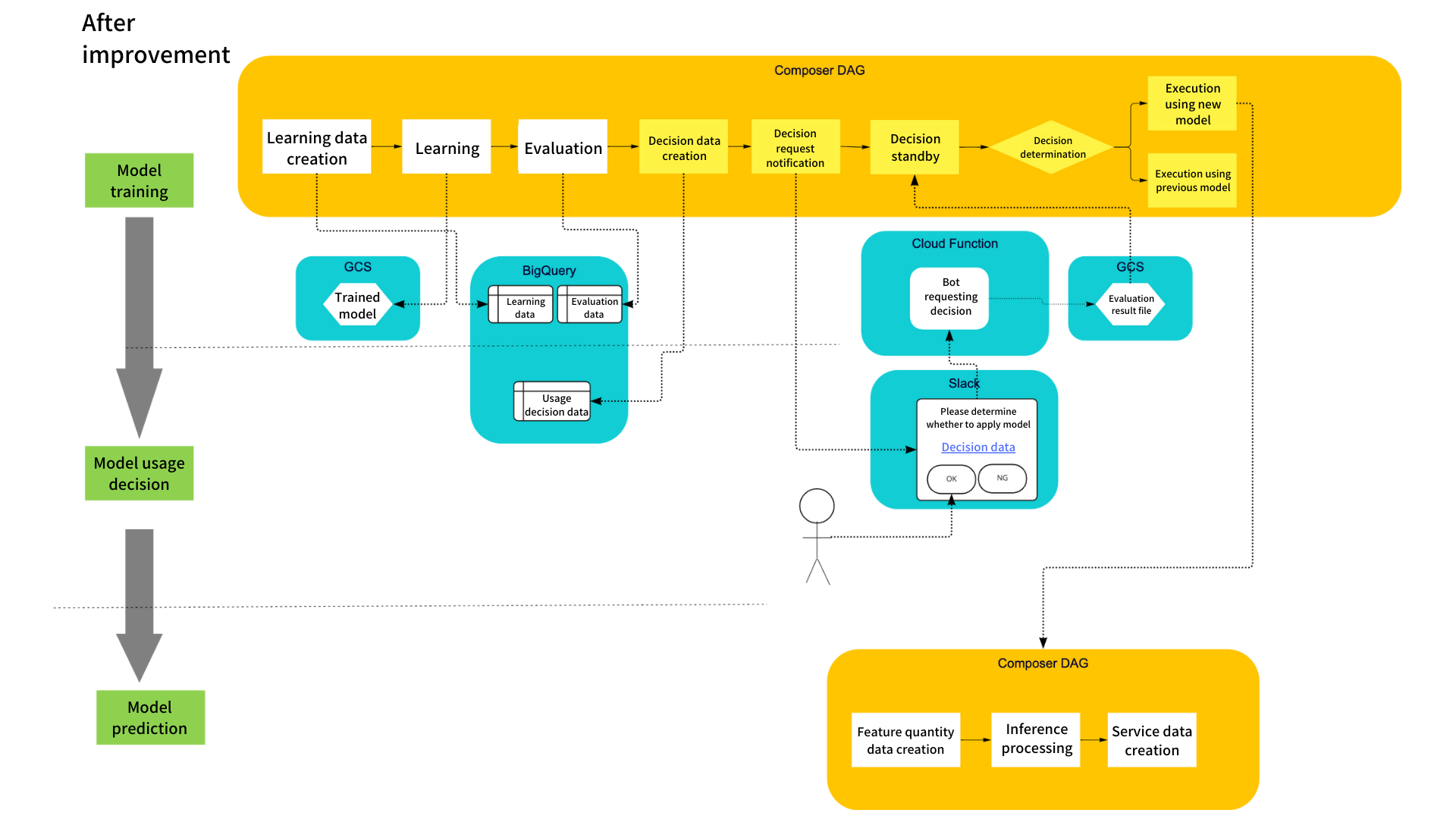
We use GCP Composer to implement and operate all regular processes involved with credit-related machine learning, as Airflow workflows (DAGs).
We implement feature quantity creation processing, learning processing, inference processing, and other post-processes as DAGs, and regularly execute these. The processes inside rectangles in the diagram above are processes implemented using these DAGs. The processes inside rounded rectangles are manual tasks performed after training and inference processing (as well as other post-processes), in which a person confirms something prior to the process proceeding to the next step.
Manual confirmation is performed for the following purposes:
- To detect irregular values, etc. in production data that could not be confirmed during unit testing conducted during the feature quantity creation process (for quality assurance)
- To confirm trends in feature quantity changes for the purpose of improving the model, etc. in the future
- To confirm that data created based on inferences is distributed as expected
We originally wanted to completely automate any process that could be automated, and implement highly efficient machine learning processing and operation by eliminating the risk of human error. However, in order to assure quality, we now manually check related data between updating the model and performing inference processing, and between receiving inference processing results and releasing to service, to confirm whether it’s okay to proceed to the next step.
Issues with operating a machine learning pipeline
However, because these steps are confirmed manually, we run into the following risks of human error:
- Risk of making a mistake during the preparation phase and confirming the wrong data, since confirmation data is also prepared manually
- Risk of making a mistake during the process of executing the next series of processes based on a manual decision and executing the wrong process, even if confirmation itself is performed accurately
Thanks to the efforts of everyone on the team, we’ve been able to catch these mistakes prior to release and keep things running properly. However, the amount of risk could increase along with the number of models and the frequency of updates. We can classify operational issues causing these risks into the following three major categories:
- Some data required for confirmation is prepared manually, so there is the possibility of mistakes being made in preparing data for confirmation
- Setting changes and execution are performed manually in order to execute the subsequent pipeline after confirmation is completed, so there is the possibility of mistakes being made in configuring settings, and the risk of execution itself being delayed
- Data is not managed in a uniform manner as some confirmation data must currently be prepared manually, and must be confirmed in multiple locations

Trial solutions
In this section, I cover some of the solutions we’re trying out in order to resolve these issues.
Our basic policy includes the following three rules:
- (1) Automate everything except for manual confirmation, whenever possible
- (2) Provide means to reduce the risk of failure during confirmation (preparing the wrong confirmation data, looking at the wrong data, etc.)
- (3) Aggregate data groups required for confirmation in a single location, whenever possible
Each of these is discussed in more detail below.
(1) Automate everything except for manual confirmation, whenever possible
Here, "everything except for manual confirmation" refers to both preparing data required for confirmation, and executing the subsequent pipeline based on confirmation results. The former is an issue that could have been resolved if we could execute it on a DAG, but still remains because we were unable to increase the operation priority. The latter is a result of being unable to get the DAG running with human confirmation as the trigger, and therefore didn’t come up when we were considering automation itself. We changed our approach to detect manual confirmation results and then branch/execute the DAG so that processing would be executed based on these results. This will be described in more detail later.
(2) Provide means to reduce the risk of failure during manual confirmation (preparing the wrong confirmation data, looking at the wrong data, etc.)
This overlaps somewhat with (1). We altered our approach so that a human is notified via Slack of any confirmation data prepared on a DAG (in the form of a link to a screen they could use to view the data), allowing them to check the data and make a decision.
(3) Aggregate data groups required for confirmation in a single location, whenever possible
We aggregated all information required for confirmation on the confirmation data screen (containing the confirmation notifications described in (2)), allowing data to be confirmed without having to search multiple locations.
These solutions correspond to our issues as follows:
| Issue 1: Some data required for confirmation is prepared manually, so there is the possibility of mistakes being made in preparing data for confirmation | Issue 2: Setting changes and execution are performed manually in order to execute the subsequent pipeline after confirmation is completed, so there is the possibility of mistakes being made in configuring settings, and the risk of execution itself being delayed | Issue 3: Confirmation data is not managed in a uniform manner, and must be confirmed in multiple locations | |
|---|---|---|---|
| Solution 1: Automate everything except for manual confirmation, whenever possible | ✔️ (Create confirmation data on the DAG) | ||
| ✔️ (Execute pipeline only after configuring settings based on confirmation results) | |||
Solution 2: Provide means to reduce the risk of failure during confirmation
| ✔️ (Include link to confirmation data in Slack notifications requesting confirmation) | |||
|---|---|---|---|
| Solution 3: Aggregate data groups required for confirmation in a single location, whenever possible | ✔️ (Create screen to view all relevant confirmation data groups at once) | ||
With regard to solutions (1) and (2), the process of sending notifications containing required information that request the human to make decisions, receiving the decisions, and executing processes based on these results was particularly complicated to implement. I discuss this in more detail below.
Implementing trial solutions
We implemented this based on our basic policy, as shown in the diagram below. Our solution combines operators for standby processes with Slack notifications and Slack bots. A human checks confirmation data linked in a Slack notification and then makes a decision simply by pressing a button. This allows the tasks following confirmation to be automatically executed.
The process flow on the DAG is as follows:
- 1: (Trained model evaluation processing is completed.)
- 2: Create data group required for model usage decision, as a BigQuery table group (a spreadsheet referring to the applicable table group is prepared beforehand, so that the table group can be aggregated on a single screen).
- 3: Post a notification on Slack, containing a link (to the confirmation data) and decision notification buttons (the DAG remains in standby until the file on the GCS bucket is updated).
- 4: (A person receives the notification.) Once the person confirms the data and clicks the appropriate decision button, the bot server receives the click as an HTTP request and updates the person’s decision information as a file on the GCS bucket.
- 5: The DAG resumes from standby and performs branch processing based on the content of the file.
- If the result is "OK," the config is updated to use the new model, and the next inference processing DAG is started.
- If not OK, the config is updated to use the original model, and the next inference processing DAG is started.
ML pipeline structure prior to improvement

ML pipeline structure after improvement

We used airflow.contrib.sensors.gcs_sensor.GoogleCloudStorageObjectUpdatedSensor to implement manual confirmation standby processing, so that these processes would wait until a certain file on GCS bucket is updated. This operator runs standby processing by regularly checking whether the specified file on GCS is updated after the specified time, and continuing to check until the file is updated.
Summary
The results of our efforts are summarized below.
First, we expect our issues to be resolved as follows.
| Issue | Response | Result | |
|---|---|---|---|
| (1) | Some data required for confirmation is prepared manually, so there is the possibility of mistakes being made in preparing data for confirmation | Prepare confirmation data on the DAG and send notifications on Slack | Confirmation data is automatically prepared on the DAG and notifications are sent to a human to check the data, ensuring that data required for confirmation is used for manual checking, and reducing the possibility of mistakes being made |
| (2) | Setting changes and execution are performed manually in order to execute the subsequent pipeline after confirmation is completed, so there is the possibility of mistakes being made in configuring settings, and the risk of execution itself being delayed | Execute pipeline only after configuring settings based on confirmation results | Subsequent pipeline execution is also performed automatically, while settings are also configured automatically based on confirmation results, reducing the risk of configuration mistakes and execution timing delays |
| (3) | Confirmation data is not managed in a uniform manner, and must be confirmed in multiple locations | Create screen to display all relevant confirmation data groups at once | Confirmation data groups can be viewed aggregated on a single screen, reducing the risk of viewing the wrong data |
We’re also enjoying the following secondary benefits:
- Notifications are automatically sent to request a human to confirm data, making confirmation schedule delays less likely to occur.
- Previously, after confirming, we had to manually revise the config for executing the DAG based on the confirmation results, and then had to manually start the DAG. All of this is now done automatically once the person in charge clicks one of the confirmation result notification buttons, making human errors and work delays less likely to occur.
In this article, I discussed how we were able to improve efficiency when incorporating manual confirmation steps in order to optimize a process pipeline that includes machine learning.
Although I covered only one of our efforts in this article, we will continue to work toward resolving various MLOps issues in order to improve systems that make use of machine learning models.




