この記事は、Merpay Tech Openness Month 2022 の19日目の記事です。
こんにちは。メルペイのソフトウェアエンジニアの@goukiです。
今日はMerpay MLチームで取り組んでいる人手による確認を組み込んだ機械学習処理パイプラインについて紹介します。
機械学習パイプラインとは
メルペイは、メルペイスマート払いという後払いサービスを提供しています。
その裏側では与信額を決定するMLモデル(以下:与信モデル)が運用されており、定期的に最新データを使って再学習してモデルを更新、最新モデルを使った推論処理を実施し、推論処理結果に基づいて与信額を更新しています。

与信関係の機械学習処理に関係する定期処理はすべてGCP Composerを利用しAirflowのワークフロー(DAG)として実装/運用しています。
特徴量作成処理、学習処理、推論処理、その他後処理をDAGとして実装、定期的に実行しています。上の図の中で長方形で囲まれている処理がこのDAGによって実現されている部分になります。一方で、上の図の中で角丸四角形で囲まれている部分は学習処理、推論処理(とその後の後処理)のあとは手作業で各処理の次のステップに進む前に人手による確認を実施しています。
この人手による確認は以下のような観点で実施しています。
- 品質保証の観点で、特徴量作成の過程でユニットテストで確認しきれない本番データの不正値等を検知するため
- 将来のモデル改善等の目的で特徴量の変化の推移を確認するため
- 推論結果に基づいて作成したデータが意図しない分布になっていないか確認するため
本来、できることならすべての処理を完全自動化し、人が作業するときの作業ミスのリスクを排除することで高効率な機械学習処理運用を実現したいところですが、品質を担保するために、モデル更新 ⇒ 推論処理 の間、 推論処理結果 ⇒ サービスへのリリース の間で次のステップに移ってもよいか関連データを人が確認する作業をしてから進めています。
機械学習パイプライン運用上の課題
しかしながら、これらの確認は人手で行うがゆえに以下の様な作業ミスのリスクがありました。
- 確認用データの準備も手作業で行う手順になっており、その準備段階のミスで間違ったデータを確認してしまうリスク
- 確認自体は確実に行えた場合でも、人の判断結果に基づき次の処理系を実行する過程で作業ミスが発生し、間違った処理を実行してしまうリスク
これまでチームメンバーの努力でこれらのリスクについて、ミスが発生してもリリース前に訂正され、正しい運用を維持していましたが、今後対象モデルが増えたり、更新頻度を増やす場合にはこのリスクが増す恐れがあります。これらのリスクに起因する今後の運用上の課題は以下大きく三つがあります。
- 確認に必要なデータの作成も手作業で行う部分もあり、確認対象のデータ準備にミスが入り込む余地がある
- 確認後、次のパイプライン実行のための設定変更と実行が手作業で、ここにも設定上のミスが入り込む余地と、実行作業自体が遅延してしまうリスクがある
- 確認用データが現状手作業で作成する必要があることに起因して各データが統一的に管理されず、確認時に複数箇所を個別に確認する必要がある

試行中の課題解決策
これらの課題に対し現在試行している解決方法を以下ご紹介します。
まず基本方針として、以下の三つを上げています。
- (1) 人の確認以外の部分はできるだけ自動化する
- (2) 確認の失敗リスク(確認データの作成ミスや閲覧対象間違いのミスなど)を小さくする手段を提供する
- (3) 確認に必要なデータ群はできるだけ一箇所に集約する
それぞれ、具体的な解決策は以下の通りです。
(1) 人の確認以外の部分はできるだけ自動化する
この課題における「人の確認以外の部分」とは具体的には、「確認に必要なデータの作成作業」と「確認の結果に合わせて次のパイプラインを実行する作業」の二つです。この前者はもともとのDAG上で実行しておけば済んでいた問題で、これまでの運用上優先度を上げることができなかったがゆえに残っていた部分でした。後者については人の確認をトリガーとしてDAGを進行させることができていなかったために自動化すること自体検討に登らずにいました。これを後に説明する方法で人の確認結果を検知し、その確認結果に即した処理を実行する様にDAGを分岐/実行するように変更しました。
(2) 確認の人に対する失敗リスク(確認データの作成ミスや閲覧対象間違いのミスなど)を小さくする手段を提供する
(1)と重なる部分もありますが、人に確認用のデータをDAG上で準備した上でそのデータ(を見るための画面へのリンク)を人にSlackで通知し、通知されたデータを確認すれば判断ができるようにしました。
(3) 確認に必要なデータ群はできるだけ一箇所に集約する
(2)で述べた確認作業用通知に載せる確認作業用データ画面には確認に必要な情報がすべて集約し、複数の異なる箇所を探し回らずとも確認が完了できるようにしました
上記解決策は下の表のような課題との対応関係にあります。
| 課題1: 確認に必要なデータの作成も手作業で行う部分もあり、確認対象のデータ準備にミスが入り込む余地がある | 課題2: 確認後、次のパイプライン実行のための設定変更と実行が手作業で、ここにも設定上のミスが入り込む余地と、実行作業自体が遅延してしまうリスクがある | 課題3: 確認用データが統一的に管理されず、確認時に複数箇所を個別に確認する必要がある | |
|---|---|---|---|
| 解決策(1) 人の確認以外の部分はできるだけ自動化する | ✔️ (確認用データをDAG上で作成) | ✔️(確認結果に従って設定をした上でパイプライン実行) | |
| 解決策(2) 確認時の失敗リスクを小さくする手段を提供する | ✔️ (確認を促すSlack通知に確認データへのリンクを付与) | ||
| 解決策(3) 確認に必要なデータ群はできるだけ一箇所に集約する | ✔️ (確認データ群を一元的に参照できる画面を作成) |
以下、特に実装上複雑であった、上記(1)(2)の解決策のうちの人に必要な情報と共に判断を促す通知をし、それに応じた人の判断結果を受信して、結果に応じた処理を実行する部分についての実装方法を説明します。
試行中の課題解決実装方法
基本方針に従い、具体的な実装は図のようにしました。待機処理のためのOperatorと、Slack通知/Slack botを組み合わせ、人はSlack通知上にあるリンク先の確認用データを閲覧し、判断結果をボタンで回答するだけで確認後の作業も自動実行されるようにしました。
DAG上の処理の流れは以下のようにになります。
- 1:(学習済みモデルの評価処理が終了)
- 2: モデル利用判断に必要なデータ群をBigQueryテーブル群として作成(作成したテーブル群は一つの画面で集約して表示できるように事前にスプレッドシート上で該当するテーブル群を参照するように作成しておく)
- 3: 確認用データへのリンク+判断結果通知用ボタンのついた 通知をSlackへ投稿(この時DAGはGCS bucket上のファイルの更新があるまで待機)
- 4:(通知に促され)人が確認実施、 結果をボタンクリックで通知すると、 botサーバによりクリックがHTTPリクエストとして受信し、GCS bucket上のファイルとして人の判断結果情報を更新
- 5: 待機状態のDAGが再開され、ファイルの中身に応じて分岐処理
- 確認OKの場合、新しいモデルを使う様にconfigを設定して次の推論処理DAGを起動
- 確認NGの場合、元々のモデルを使う様にconfigを設定して次の推論処理DAGを起動
改善前のML パイプラインの構造

改善後のML パイプラインの構造
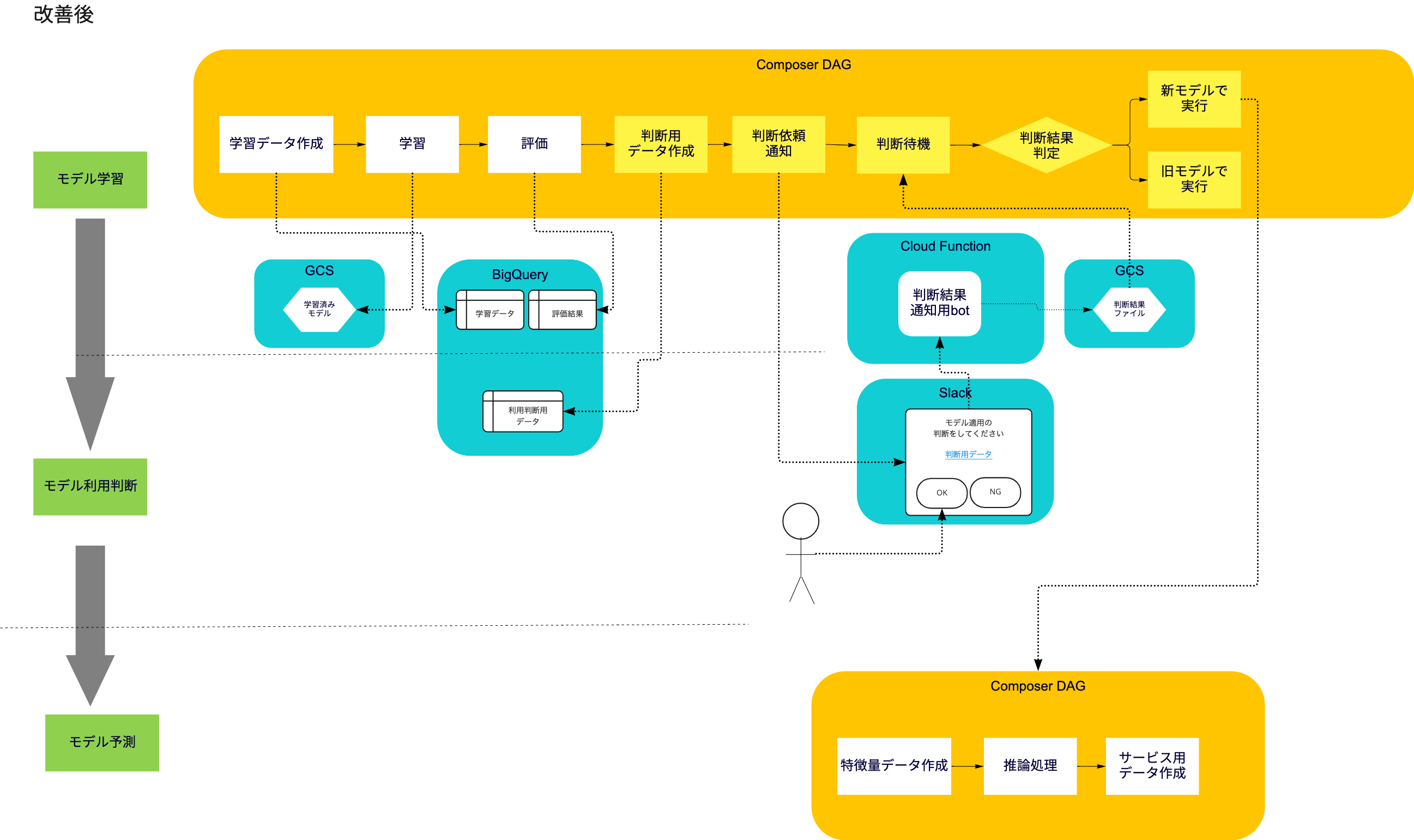
このとき、人の確認の待機処理はairflow.contrib.sensors.gcs_sensor.GoogleCloudStorageObjectUpdatedSensorを使い特定のGCS bucket上のファイルの更新があるのを待機するように実装しました。このOperatorは指定したGCS上のファイルが指定したタイミング以降に更新されたのかを定期的に確認し、更新されるまで確認処理を続けることで待機処理を行います。
まとめ
以下、この取り組みによる効果をまとめます。
まず、先に挙げた課題に対して以下の様に解決が見込まれています。
| 課題 | 実施内容 | 取り組みによる効果 | |
|---|---|---|---|
| (1) | 確認に必要なデータの作成も手作業で行う部分もあり、確認対象のデータ準備にミスが入り込む余地がある | 確認用データをDAG上で作成し、Slackにより通知 | 確認用のデータもDAGで自動作成された上で確認作業用通知により確認必要なデータが人の確認に確実に使われるようになり、ミスが入り込む余地を小さくすることができました |
| (2) | 確認後、次のパイプライン実行のための設定変更と実行が手作業で、ここにも設定上のミスが入り込む余地と、実行作業自体が遅延してしまうリスクがある | 確認結果に従って設定をした上でパイプライン実行 | 次のパイプライン実行も自動実行されるようになり、その設定も確認結果に応じて機械的に設定されるようになったことで設定ミスと実行タイミング遅延のリスクを小さくすることができました |
| (3) | 確認用データが統一的に管理されず、確認時に複数箇所を個別に確認する必要がある | 確認用データ群を一元的に表示する画面を作成 | 確認用のデータ群を一画面で集約して参照可能となり、異なるデータを見てしまうリスクを小さくすることができました。 |
さらに今回の取り組みにより次のような副次的な効果を得ることもできました
- 確認作業が機械的に通知され促されるので確認作業のスケジュール遅延が発生しにくくなりました
- 従来は確認の後、確認結果に応じて人手作業でDAG実行のためのconfigを修正する作業を実施した上で、マニュアル作業でDAG起動を実施していました。これらが確認結果通知用のボタンクリックだけであとは全て自動実行されることとなり、人手作業によるミスや作業遅延が発生しにくくなりました。
機械学習を含んだ処理パイプラインを効率化すべく、現在取り組んでいる人手による確認を含んだ場合の効率化方法についてご紹介しました。
今回ご紹介した内容は現在取り組んでいる活動の一つをご紹介しましたが、今後も継続的に機械学習によるモデルを使ったシステムの改善のため様々なMLOpsの課題の改善に取り組んでまいります。




