This article is a translation of the Japanese article published on February 25th, 2022.
*This article is part of our "Blog Series of Introduction of Developer Productivity Engineering at Mercari."
Author: k-oguma (ktykogm) (Microservices SRE Team)
In this article, I discuss some specific examples related to the previous article, "Embedded SRE at Mercari." I’ll be covering some issues I’ve actually encountered while working as an embedded SRE in product teams, as well as our efforts to resolve these issues. I’ve also realized that there are some benefits to working as an embedded SRE, and I’ll summarize these benefits at the end of this article.
Terminology used in this article
- SRE
- Abbreviation for "Site Reliability Engineering"
- Methodologies, concepts, and best practices related to reliability
- SREs
- “Site Reliability Engineers”; Engineers who specialize in SRE
- I use this plural abbreviation sometimes to differentiate between site reliability engineering (SRE) and site reliability engineers
- Microservices SRE
- The name of a team that implements or promotes SRE, formed from embedded SREs working on Mercari microservice development teams (product teams), or the name of the job done by these engineers
Intended audience
This article is intended for the following audiences.
- SREs
- Engineers with experience implementing SRE
- People learning about SRE
Overview of Microservices SRE
The mission of the Microservices SRE Team is summarized below in three objectives:
- Provide support, as Embedded SREs, in improving reliability based on the unique circumstances of the microservice team to which they are assigned
- Expand the adoption of SRE practices throughout the entire organization
- Help implement new features on the microservice platform developed by the Platform Team
Work done by Embedded SREs
In this section, I discuss some examples of work done by Embedded SREs.
Let’s start by defining what Embedded SREs are. They work embedded in service development teams to implement SRE, and serve to communicate SRE best practices to service developers and the rest of the team. In other words, they function as SRE evangelists.
You may have heard the phrase, "Enabling SRE." Our SREs go from team to team to communicate policies for strengthening and improving SRE even in organizations where SRE is already enabled, so we are more like evangelists or circuit preachers.
At Mercari, Embedded SREs do not have fixed positions and generally are given a degree of mobility (they are technically “movable Embedded SREs”), allowing them to work with various teams and cover a wider area.
Teams I was embedded
I’ve worked as an Embedded SRE in mainly two product teams. The first was a user-social team, which is responsible for My Page and user social services.
The second (where I am now) is actually a collection of multiple teams responsible for services including the product details service, "like" service, and UX-related services.
I’ve encountered the same kinds of issues in multiple teams:
- Issues with on-call organization
- Insufficient SLO monitoring
- DB performance issues
- Delays introducing new features
- … and others
In the following sections, I discuss some of my work on these issues.
Issues with the on-call organization
The way a team organizes their on-call can often present a major issue in operating a microservice. This is because a single development team will be developing and operating multiple services, and the team will soon run out of people if it simply assigns one person to each service. For example, my current team had only two people on-call, and they alternated every other week. It’s crucial to maintain a proper on-call setup.
But it can often be difficult to determine how best to build an operations setup that can meet that need. For example, many teams don’t know how to rotate on-call duties among members (or how many people should be in the rotation), or what people should and should not do when on-call.
This is closely connected with on-call onboarding. A problematic on-call setup can cause concerns and apply pressure to team members, making it difficult to increase on-call members.
If you’re in a situation where you struggle to get the right number of people on-call, you will naturally have trouble strengthening that on-call organization. This makes it difficult to ease concerns and pressure, and more difficult to implement onboarding. We recognized that it’s important to prioritize improving the on-call structure in order to escape this vicious cycle.
Improving the on-call organization
In order to improve on-call operations, it’s crucial to clarify policies as well as in-team promises, peace of mind, and awareness.
Reducing confusion, unease, and pressure will help improve operations. It will also help improve psychological safety.
Just like with clarifying budget policies, there are best practices when it comes to SRE.
https://sre.google/workbook/on-call/
I wrote and prepared the following specific references and guidelines. Some of these guidelines are:
- How many people are required at minimum to avoid single-person on-call and excessively long shifts?
- How many people are required to eliminate certain types of toil?
- How many people are required to achieve certain MTTA/MTTR target values for each SEV level?
- How can the on-call organization be improved even with a small development team?
What are SEV levels?
- SEV levels are classified by incident impact, with smaller values handled as critical incidents
- Metrics with incident response procedures clarified for each SEV level
- References
- https://response.pagerduty.com/before/severity_levels/
- https://dzone.com/articles/practical-guide-to-sre-incident-severity-levels
- MTTA: Mean Time to Acknowledge. The average time from when an alert is reported until on-call responds (the team takes action).
- MTTR: Mean time to recovery, repair, respond, or resolve. Either repair or recovery is normally indicated by the average recovery time, average repair time, average response time, or average resolution time.
For example, upon first being placed on-call, a team member might feel that they will have to resolve all issues that occur while on-call, on their own. We included the following statement in our guidelines to provide peace of mind:
*"No one doubts your abilities, even if you escalate an issue. There’s nothing to fear about being the primary on-call person. If a critical incident occurs, check who is an expert on the matter and feel free to escalate. "
### Escalation policy
- Requires escalation path
- Escalation is a normal functional process
- Even if you escalate, we will NOT suspect your ability
- If anyone suspected that, they need to learn about psychological safety
#### You don't feel afraid to become a `primary` on-call engineer
- **If a critical or significant incident occurs**
- We expect our primary on-call engineer to **escalate to a team member who knows more about the services involved in the incident**
- We need to do the following:
- `first investigation -> overview of the incident -> identify appropriate contact -> escalation`
- **On-call duties do not mean that you alone are expected to solve everything!**Next, I’ll explain what kinds of on-call shifts and operations you can set up, based on the size of the organization.
There are some common elements I’ll explain: the proper frame of mind for responding to incidents and how on-call members should work during the on-call period.
Note that the kind of work that can be done and the goals of doing this work will vary depending on the number of people, since the on-call structure itself varies depending on the number of people on-call.
For example, it would be difficult to have both a primary and secondary person on-call if a team has only three to five members who can take turns in on-call service, so only a single person would be placed on-call. In this case, in addition to responding to incidents, the person on-call will need to run security updates (including Dependabot updates), update internal tools, and participate actively in code reviews.
(*The following has been partially modified.)
### Common
- Formation
- If you have no responsibility on-call, you can still be flexible in case of emergencies.
- If your expertise is needed to resolve an incident, it is escalated to you.
- Otherwise, you will basically leave it to the on-call duty
- Where do I need to contact first?
- [#slack_channel](https://......../)
- What to do while on-call?
- During the on-call period, please stop or pend your normal development work and focus on the following to help everyone!
- Of course, if it does not interfere with your regular on-call work, you can do your everyday (normal) development work
- Or you can do DevOps development to eliminate/reduce toil, indeed DX improvement
### 3 to 5 people
- Formation
- Only primary. (Only one)
- What to do while on-call? (Tasks while on-call)
- Update with dependabot
- Update in-house tools
- Incident response
- Dealing with security issues
- Code Reviews
- Rotation Period
- 1 week (Rotate every 3 to 5 weeks)
- MTTA (Mean Time To Acknowledge) objective (SLA of Response time)
- MTTA <= 30min
- MTTR (Mean Time To Repair/Recovery) objective
- [SEV-1](https://response.pagerduty.com/before/severity_levels/)
- 1h
- SEV-2
- 2h
- SEV-3
- 12h
- SEV-4
- 24h
- SEV-5
- 48h
### 6 people
- Formation
- Two people (Primary 1 + Secondary 1)
- What to do while on-call? (Tasks while on-call)
- Update with dependabot
- Update in-house tools
- Incident response
- Dealing with security issues
- Code Reviews
- Response to inquiries
- If you need to take over, do so.
- Follow up actions for incident resolution.
- Write postmortem in the Blameless
- Development for toil elimination
- Purpose to reduce toil
- e.g. Ops automation, etc
- Update documents
- Target to outdated contents
- Rotation Period
- 1 week (Rotate every 3 to 5 weeks)
- MTTA objective (SLA of Response time)
- MTTA <= 15min
- MTTR objective
- SEV-1
- 0.5h
- SEV-2
- 1h
- SEV-3
- 6h
- SEV-4
- 12h
- SEV-5
- 24hWe also issue tickets each time, in order to lessen the impact on sprints when on-call, share information with others, and communicate information to the next person on-call.
Results of improving the on-call organization
In addition to improving onboarding, these policies also allowed us to prepare related Playbooks and Runbooks (explained later), and to improve how we respond to incidents.
We were also able to reduce pressure and concerns among people on-call, which made it easier for them to do on-call work.
Insufficient SLO monitoring
Next, I’ll discuss SLOs.
SLO stands for "Service Level Objective." It’s a numerical target required to maintain service provision/availability levels. It’s a highly rational and reliable numerical target where the goal is to achieve what’s required for the user experience and nothing more.
According to the Google Cloud Blog, an SLO "sets system availability as an accurate numerical target."
SLOs bring data-driven concepts to monitoring operations, and they are also used as a tool to communicate with other teams across the engineering organization.
While performing tasks such as adding, adjusting, and controlling alerts, I noticed some cases where the current target values for SLO thresholds were the standard values and not suited to the actual conditions.
Communicating the difficult concepts of "percentiles" and "SLO"
Our mission as SREs is to spread the use of SRE, so it’s important for us to communicate the core concepts of SRE to members of development teams.
For example, we sometimes use the concepts of percentiles and the (critical) user journey to explain this and to present policies.
A percentile indicates how far away we are from some minimum value. Our general standard is the 95th percentile, or a position of 95% counted from the minimum value.
For a latency SLO, a position of 95% from the total number of normal requests would be 95th percentile latency.
We use percentiles because an average would also include the long-tail of the distribution, and we want to avoid that.
Specifically, for example, if we experience some extremely large, irregular values, including them in the calculation would cause the average value to jump.
However, one SRE best practice is to not aim for 100%. Doing so allows us to ignore any large values occurring by chance. We can also exclude these as outliers to prevent "noise" during monitoring. For 95th percentile latency, we would ignore the top 5% latency.
This is pretty easy to explain and understand.
However, compared with the 50th percentile (median) or the 75th percentile, it can be difficult to understand trends. It’s also not easy to explain this to everyone.
Some monitoring items require a percentile other than the 95th, so we took some time to consider and discuss this.
For example, we can arrange each percentile for comparison in Datadog APM.

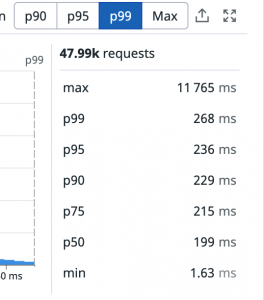
However, it’s difficult to explain and understand when and how each percentile occurs in relation to overall access trends, with just this alone.
We decided to use a spreadsheet to prepare multiple potential monitoring measurement patterns and gave percentiles for each, for review and discussion within the team.
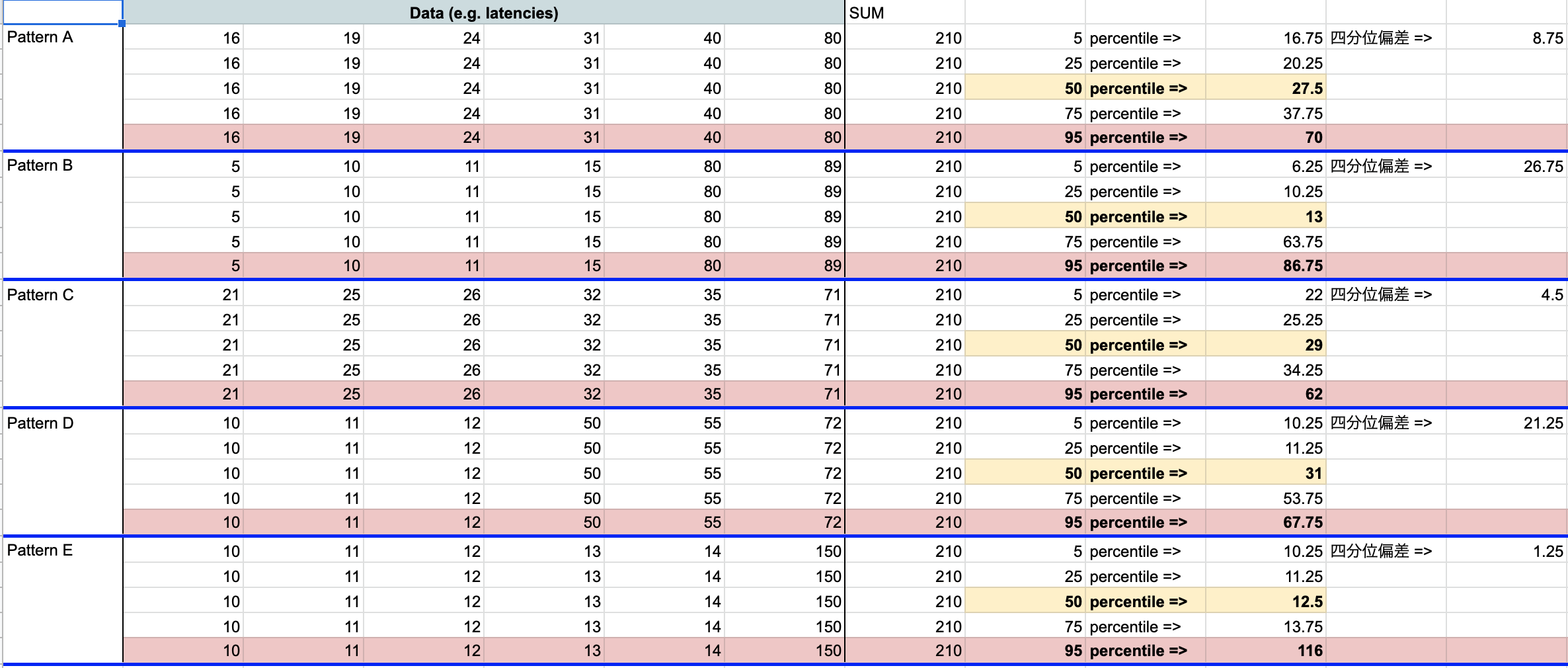
*The values above are not accurate.
In this example, I created five percentile groups (5th, 25th, 50th, 75th, and 95th) for each of five patterns (A through E). I showed trends in each, so that the team could discuss how far to monitor other than the 95th percentile for important metrics, and to what extent to include this in SLOs.
(The interquartile range and interquartile deviation indicate data variation.)
This hopefully shows that it would be difficult to detect overall slowness with the 95th percentile alone (note that there are probably many cases where it is sufficient to monitor only the 95th or 99th percentile).
If there are any monitoring items that would be heavily impacted by overall slowness and causing that delay to be seen as a problem, these items should also be monitored for the 50th percentile or 75th percentile, for example. SRE books say something like, "using the 50th percentile places the focus on typical cases."
This is one way we’ve been able to enhance SLO monitoring.
DB performance issues
We mainly use Google Cloud Spanner (Spanner) for our microservice DBs at Mercari.
As SREs, we are also actively involved in microservice development code reviews, so we sometimes discover slow queries even prior to release.
Improving DB performances
Take secondary indexes, for example. I verify STORING clauses, summarize core usage concepts in documents, and urge whatever microservice team I’m working with to implement them.
I also work on improving performance through composite index and query design.
Delays introducing new features
Although we use GKE at Mercari, everything being managed in the could doesn’t mean the system is perfect. We need to introduce various features and systems, including Istio and cloud network policies.
We also need to introduce tools developed internally by the Platform Team.
However, service development sometimes takes a long time, and the introduction of these features, etc. has been delayed at times.
Promoting the introduction of new features
This is one of the most important tasks for the Microservices SRE Team.
Sometimes we introduce features on our own, and other times together with other teams such as the Platform Network Team.
We also work to ensure that there are no delays with each microservice.
Working with other teams
Each company within the Mercari Group has its own SRE Team.
Mercari also has SREs at each layer/scope.
There are also several SRE/infrastructure-related teams besides our Microservices SRE Team.
For example, the Platform Team is also actively involved in SRE-related work.
We all work together to react quickly when an incident occurs, to provide support and resolve the issue as soon as possible.
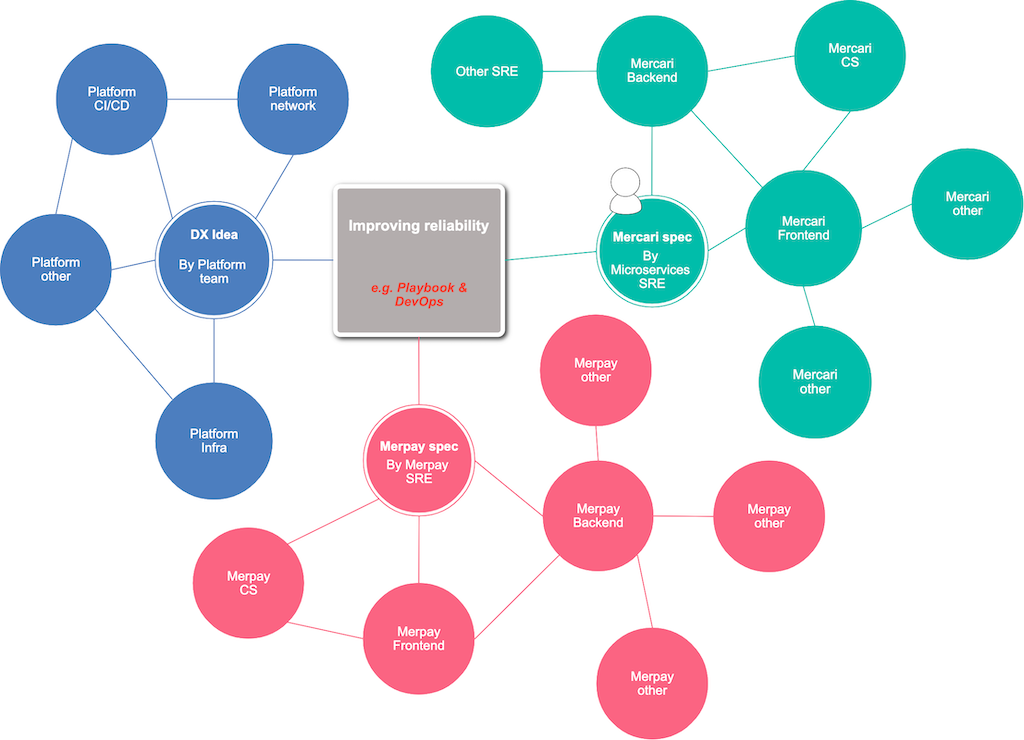
(*The conceptual diagram above shows how teams throughout the organization are involved in improving reliability. It’s not meant to show how teams are actually connected.)
After handling an incident, we also conduct a post-mortem with everyone involved.
A post-mortem doesn’t involve just a single team, and many non-SRE engineers will also typically participate. It’s a great opportunity to exchange information, including insights from microservice developers.
Recently, the Merpay SRE Team and Platform Team have been working on introducing Playbooks and Runbooks.
-
Playbook
- Refers to operational procedures for mainly “handling incidents,” used when on-call or during normal operations
- A type of guidebook for alerts, that contains escalation information, contact information, and other relevant information
-
Runbook
- Refers to procedures or a (semi-) automation tool or a command, for a single purpose or task
- Contains no information on microservices or responsible personnel
- If a Playbook is like a guidebook, then this would be a link destination within that guidebook
- Handled as a component of a Playbook, making it highly reusable
- Refers to procedures or a (semi-) automation tool or a command, for a single purpose or task
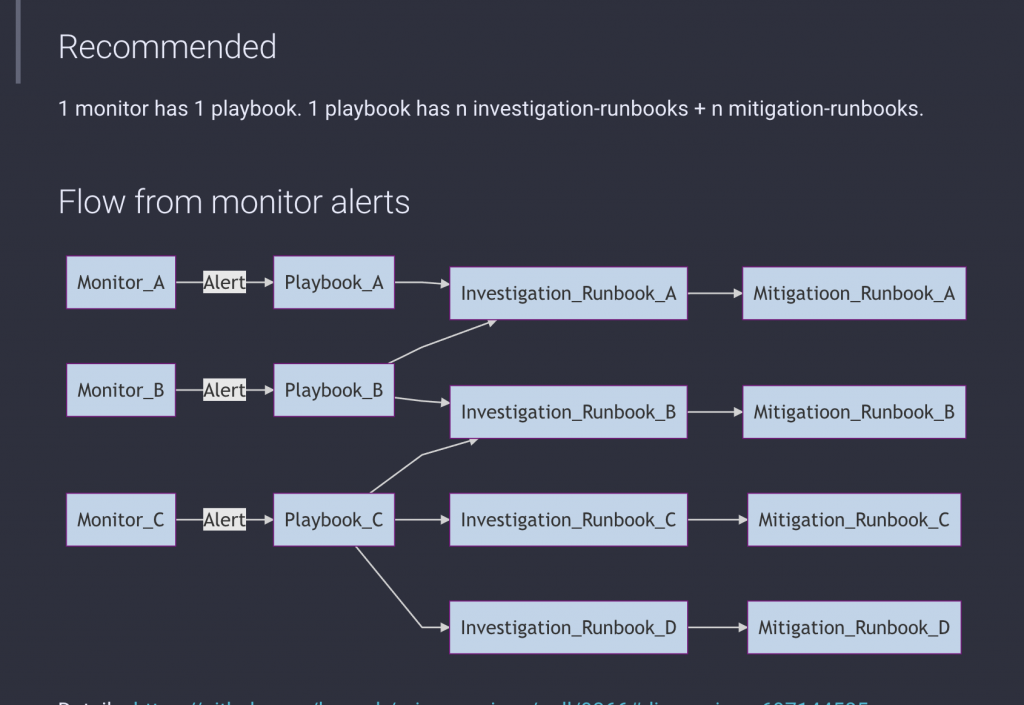
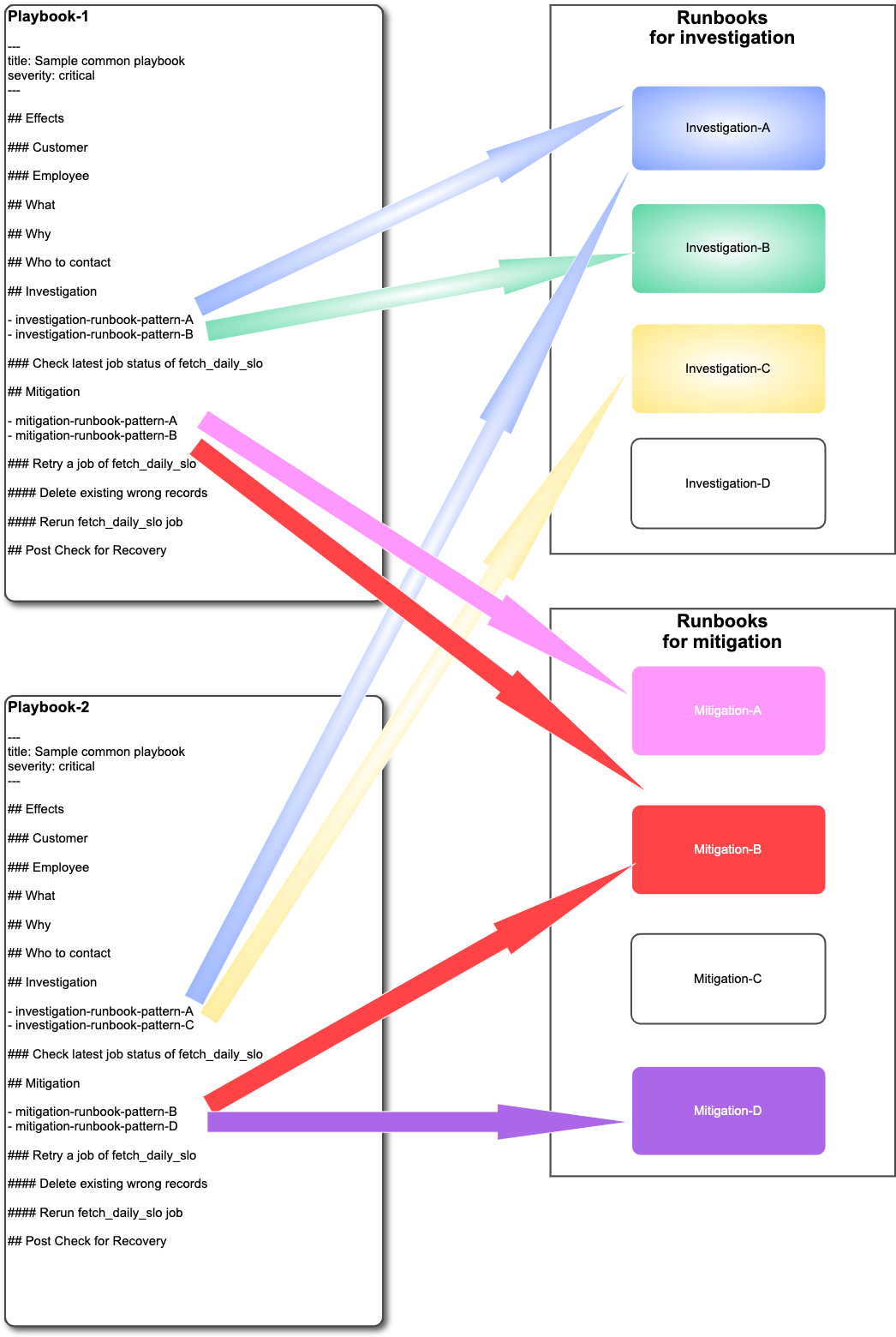
*I referred to the "What is a Runbook?" article on PagerDuty for defining a Playbook and a Runbook.
What we’ve made
So far, I’ve just discussed some examples of work related to organization and management. However, I’ve done all kinds of work outside of microservice SRE support.
Here are some of the things we have made:
- Migration tools
- Slack bot
- ITGC (Information Technology General Control) and IT controls
- Monitoring/management tools (development, maintenance, operation)
- Commands related to service development
One specific example is that I’ve created a server with Go using a headless browser, and I am developing a solution to start it on Buildpacks and then on Cloud Run.
It uses the following technology stack.
- Go
- Buildpacks
- Docker
- Terraform
- Google Cloud Run
- knative
- Google Cloud Scheduler
- Google Secret Manager
Although I want to create things that will be used by multiple teams, at the end of the day, those of us on the Microservices SRE Team are Embedded SREs.
We tend to do more work involved in creating things within our current microservice development team or revise existing service code, giving us fewer opportunities to create cross-organization tools, etc.
However, we might be able to tackle a wide variety of challenges someday, if the size of our team increases.
Embedded SREs keeps on moving
It’s assumed that microservices SREs won’t stay in the same place for long and will move between service development teams.
Although this is done to help cover a wider area, the real reason for doing this is that there aren’t enough Embedded SREs for each and every microservice and microservice development team.
I mentioned earlier that SREs serve as evangelists, and this is why. They spread knowledge and awareness of SRE wherever they go.
Of course, that doesn’t mean that they just do the same thing each time they switch teams.
Although teams sometimes share certain characteristics, there are many situations where you need to adapt to the unique characteristics of a team or service. We also continue to automate and eliminate the more tedious tasks.
We have many divisions called "camps" in our development organization. Each of these divisions includes multiple development teams, and we have begun creating cross-team groups called "backend guilds" that contain one or two backend engineers from each team, in order to make cooperation and management easier (see this article for more information on these development organizations: [Transcript] All of our product development organization disclosed – Cross-functional team in Mercari (Japanese only)
I’ve recently been participating as a member of one of these guilds, with the goal of becoming an embedded SRE in multiple microservice development teams.
The goal is to connect multiple microservices within the backend guild and rotate members through embedded positions more efficiently.
You can find more details in the "Rotation" and "Embedded to the division, instead of the team" sections of a previous article, "Embedded SRE at Mercari."
Recently, I’ve been working on introducing Playbooks and Runbooks (discussed previously) along with other members of the backend guild.
Benefits and drawbacks of working as a microservice SRE
I’ve been working as an Embedded SRE now for some time, and have realized some benefits and drawbacks to this approach. I’ll mention these below, though of course this is just from my own perspective.
Benefits
- You can work closely with members of microservice development teams
- You learn a lot
- You are involved in both service development and infrastructure work
- It’s fun
- You can quickly identify issues
- It’s easy to contribute directly
- Investigation work spans a wide range of domains, from infrastructure to the app itself
- You can establish a good knowledge community
- There’s good diversity
Drawbacks
- It’s easy for your OKRs and the number of meetings, etc. to get out of hand (too many and too much overlap)
- This is because you are participating in meetings, etc. for both SRE and microservice development
- High cognitive load
Conclusion
I hope I was able to give you a decent idea of what the Mercari Microservices SRE Team and Embedded SREs do.
Of course, we do a lot more than what I covered here.
Mercari is currently looking for people to join our Microservices SRE Team and is conducting casual interviews. Feel free to contact us if you want to hear more!