Author: @deeeeeeeet
Platform Developer Experience (DX) team is one of the Developer Productivity Engineering Camp teams. It focuses on providing a state-of-the-art developer experience where product teams can take full end-to-end service ownership without any frictions so that they can deliver great products to Mercari customers faster and easier.
In this blog post, in the beginning, I will explain the background of this team from the history of developer experience at Mercari. And then, I will show some of the recent and future initiatives.
History of Developer Experience at Mercari
This section gives a brief history of the developer experience at Mercari and explains why it is getting crucial.
The Beginning and Initial Philosophy (2018)
The Microservices platform team started in 2018 when we began microservices migration. Since then, we’ve provided infrastructure and DevOps toolchains to the product teams.
One of the main motivations of microservices migration was that even if the organization grows, each team can release products and feature independently and encourage microdecision. Our infrastructure and toolsets are designed to envision this motivation.
One of the biggest challenges we had was to foster DevOps culture in Mercari. Before microservices migration, there was no chance that the Dev team configured production infrastructure or DB and always needed to depend on the central Ops (SRE) team when doing something. To have independent releases and faster development cycles, we believed the product team needed full responsibility for the service lifecycle: build, test, deploy and operate, instead of depending on the centralized teams. Since it’s challenging to do everything by the product team, we started offering the system and tooling to support all phases.
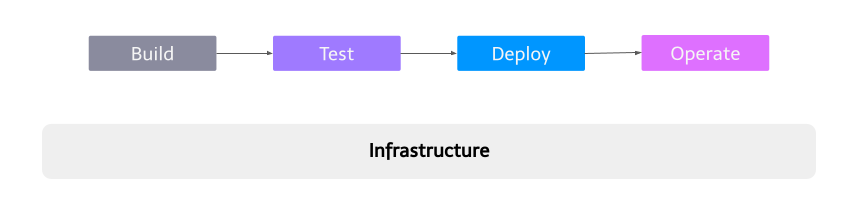
(Abstract diagram of our offerings as a platform. We provide base infrastructure and toolings in each SDLC phase. e.g., in the deploy phase, we provide Spinnaker.)
Fundamental Building Blocks (2019)
After two years, we finished providing the basic fundamental building blocks of the service development. For example, we provide:
- Terraform module named microservice starter kit, which bootstraps required infrastructures for a microservice (e.g., Kubernetes namespace, GCP project, SaaS accounts, and so on)
- Terraform monorepo where developers can provision its microservice cloud resources (e.g., Cloud Spanner or GCS) by themselves
- Kubernetes monorepo where developers can write Kubernetes manifest for its microservices deployment
- Spinnaker where developers can configure various delivery strategies for microservices)
As an outcome, we support 400+ services across Mercari JP, Mercari US, and Merpay. 100+ infrastructure changes per day and 300+ deployments per day are happening as of writing this post now. These are not done by the centralized Ops team but by the product team. To think about the initial motivation to foster DevOps culture, we have achieved some extent of the initial goal.
Adverse Effects and New Focus
But, while achieving some of the goals, there are some drawbacks: too many burdens on the product teams. From the multiple developer surveys we conducted and discussion with backend teams, we identified the following issues:
- Too many manual configurations: since platform offering is too fundamental, you can do whatever you want based on your needs but, on the other hand, this means the product team needs to configure many things by themselves to create a new service: initialize base codes, set up the testing environment, prepare the build pipeline, write the wall of YAML (i.e., deploy configuration), set up the delivery pipeline and monitoring…
- Exposure of low-level infrastructure: Some platform components were released with exposing low-level configurations. Due to this, developers need to write infrastructure-specific configurations, which is an overhead important for product development and should usually be controlled by the platform or security team. This also created issues when the platform team wanted to make cluster-wide changes: we needed to ask developers to take action.
- Boilerplate codes and configs of cross-cutting concerns: even though we have some common services like gateway or authority service, or library which, e.g., handles Go application observability, there are many boilerplate codes or infrastructure configurations that need to be written by the product team every time they build a new service.
Because of them, the cost of building new production-ready microservices and the maintenance cost of the existing services is very high.
To solve this issue, we set a new goal: building Platform-as-a-Service (This does not mean deploying an actual PaaS like CloudFoundry but providing more abstracted UI/UX around our existing infrastructure and toolings. The abstraction is specific to our organization and the culture. It should balance with flexibility for the complex application that the previous PaaS can not achieve) and focus on enhancing the developer experience (DX).
(Actually, reducing the developer’s burden and frictions is not the only reason for this goal. From the platform maintainability point of view, hiding the raw level infrastructure configuration from developers is very important. For example, if we want to change some of the Kubernetes manifests for reliability improvement, it’s easier to change if it’s abstracted and in our hands. The product team does not take any action, but if not, we need to ask each team to update it).
Platform Reorganization (2020)
In the Spring of 2020, to scale teams and reduce the cognitive loads of members, we reorganized the platform team into multiple dedicated teams. As shown in the following diagram, we divide the teams into the dedicated responsibility area of platform offering.

(Abstract diagram of platform team reorganization. We assign a team to each phase of the SLDC phase, e.g., assign CI/CD team to Test and Deploy phase.)
Platform DX team was born in this reorganization with DX specialization. The team focuses on enhancing the DX and providing related toolings and services. Platform DX team also supports other teams to ensure the unified DX across all platform toolings.
Recent projects
This section describes some of the Platform DX team’s recent projects. A detailed explanation will be covered in the follow-up posts from blog series articles.
Kubernetes manifest abstraction
We’ve been using Kubernetes (k8s) as the main application platform. One of the most significant issues we had in our k8s setup was deploying applications; developers need to write a wall of raw YAML manifests, i.e., everyone needs to be a YAML engineer, and that’s a huge cost.
To solve this issue, we started to develop Kubernetes manifest abstraction framework. Previously even for simple deployment, for a production-ready application, developers needed to write around 1000 lines of configuration but, with this framework, only 130 lines are required (90% reductions). The following is an example of the configuration we have (This is based on CUE. If you want to know the implementation details, please check the member’s post on the CUE community):
// Minimum required base configuration of the application and its delivery pipeline.
Metadata: {
name: "echo"
serviceID: "kouzoh-echo-jp"
}
App: kit.#Application & {
metadata: Metadata
}
Pipeline: kit.#Pipeline & {
metadata: Metadata
}
Delivery: {
echo: kit.Delivery & {
pipeline: Pipeline.pipeline
resources: App.resources
}
}// Minimum required new regional deploy patches
Metadata: region: "osaka"Temporary role granting system
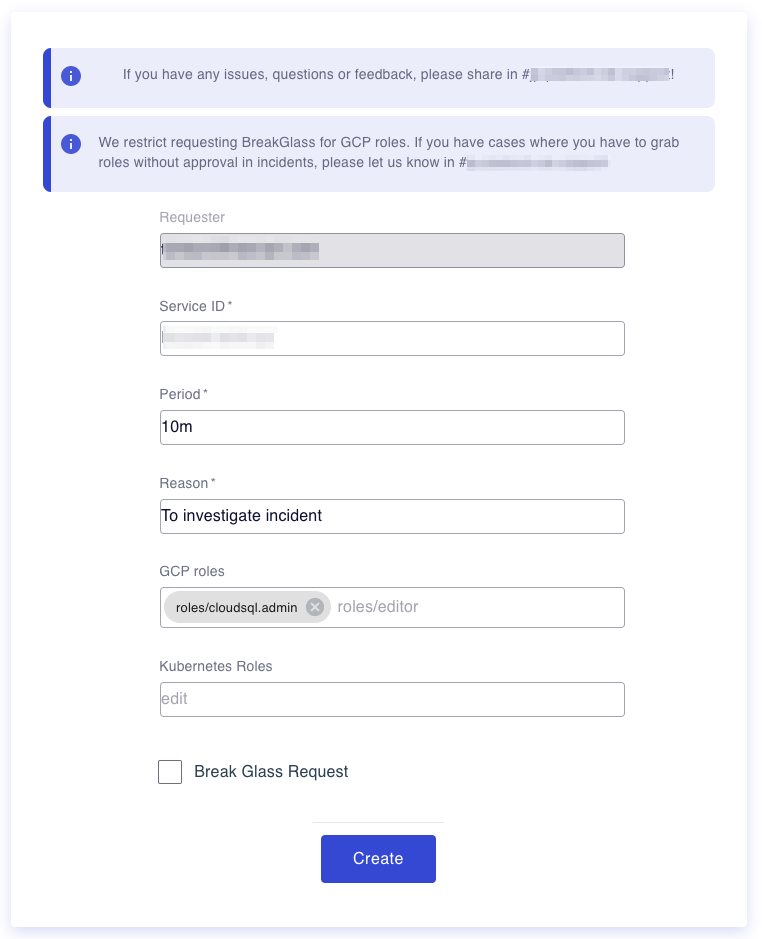
At Mercari, we ask developers to take on-call responsibilities and handle incident responses related to their services. So improving production operation, DX is also very important. Since everyone can access production, we set a zero-touch production to reduce the risk and harden security in the production environment. The platform DX team started building tooling for it.
One of the first initiatives was providing a temporary role grating system. Instead of having access permissions to the production, this system allows you to grab the role only when required with a proper review process with owners. The following is the example UI of this system (it tries to grab roles/cloudsql.admin for 10m to production incident investigation).
Kubernetes Tenant management with Hierarchical Namespaces Controller
We use the multitenant pattern for our k8s architecture. This means instead of creating k8s clusters per service, we share a single cluster and configure the k8s namespaces (tenant) per service. The problem is that the more the product team creates services, the more the burden to manage these tenants increases, e.g., when a new member joins the team, they need to update all namespaces’ RBAC which the team manages.
We introduce the Hierarchical namespace controller to solve this problem and reduce its management costs. You can read the details on Scaling Kubernetes Tenant Management with Hierarchical Namespaces Controller or watch Mercari Gears session Scaling microservices development with microservices-team-kit.
Terraform module upgrade automation
As described above, we provide a Terraform module named microservices-starter-kit which bootstraps required infrastructures and SaaS accounts for a microservice. This is a core module of the platform team, and every time we introduce a new feature, we do via this module. Once a new version of the module is released, we ask developers to upgrade the module and use the new features.
Since we update the module quite frequently, developers’ cost of upgrading operations was getting very high: they check release notes, create a PR to upgrade the module, check Terraform state diff and confirm there is no unexpected diff, and finally, merge PR…
We built a system to automate everything to reduce this cost and quickly introduce new features. You can watch the details at the member’s talk Management of large scale terraform monorepo. Developers do not need to take any action for the module upgrading.
Developer Survey
Having empathy for the customer, the developers, is essential for the platform engineering to decide what kind of issue to solve next. If you miss it, you just build something useless. To get better insight into what developers are struggling with, we conduct a developer survey every half a year. We design surveys, ask for inputs, and summarize the results. The entire platform team uses the results for better product design.
Future initiatives
The following are some of the future long-term initiatives we are thinking of working on.
Zero Touch Production
We introduced the temporary role granting system to secure the production environment as described above. It’s just the first step toward Zero Touch Production (ZTP). We reduced the production access by this but still, it’s touched directly and many possibilities of human errors.
From our observation, there are some everyday operations on production, e.g., restarting pods or updating HPA. So we are thinking of providing automated workflows with proper guardrails. With this, the temporary role granting system will be the final fallback point of the production operation (break-glass), and most of the process can be via the system or safe proxy. We can reduce the direct production access as much.

Better language framework
In our microservice setup, we mainly use Go as the primary language. When we started microservice migration, we prepared basic standard Go packages (e.g., handles common observability) and a template project which developers can just copy and create their service.
But after the initial version was released, we could not evolve it. So there are lots of room to improve. For example, the template project is good initially, but it’s not good to add extra features later (the team needs to watch changes in the template project and include the changes in their project manually). Or simply, there are lots of boilerplate code which can be hidden as abstractions. Normally they are infrastructure or security-related, e.g., reliable access to other microservices, observability, and so on, and should not be cared so much by developers.
To solve these issues, we are thinking of evolving our internal language framework and enabling developers to focus on business logic. Since we started providing Kubernetes manifest frameworks as described above, we can also consider integrating well. It will be a more PaaS-like experience to deliver a new service.
End-to-end workflow automation
Giving abstraction to each component is not enough. We need to consider better integration across the components. The experience of using different toolings with different UX for every other phase of development is not good: Use tool A to bootstrap project, configure tool B to setup monitoring dashboard, kick tool C to deploy the application, and so on. It also requires lots of learning. We are thinking of providing a single unified interface to handle end-to-end service development workflow in the long term.
We’re hiring!
In this blog post, I introduced a brief history of DX at Mercari, recent projects from the platform DX team, and some of the future initiatives. If this is something that interests you and you would like to know more about us, feel free to DM me on Twitter (or we can have some casual chat on Google meet or any).
Please check the following JDs, too. We also sponsor work visas and support moving to Japan. The Japanese language is not a requirement for our team.



