Hello! I’m @myoshida from the Merpay SRE Team. This article is for the 8th day of Merpay Tech Openness Month 2021. (available only in Japanese)
The SRE Team is constantly at work on various improvements to provide a better user experience for our customers. One example is how we introduced the concept of playbooks, an initiative for reducing the burden of operations. Read on to learn more!
Overview
At Merpay we have an on-call system where both application engineers and SRE are involved with operations.
Operations involve various challenges, one of which is figuring out the best approach to manuals.
Where should we keep them? Are they being updated? What should they include? When should we be using them? Perhaps in varying degrees, these are questions that any kind of development team will face.
As a potential solution, we introduced the concept of playbooks to our current operations system. By using playbooks, a systematically assembled set of documents, we aimed to reduce the burden for those working on call and create a better operations experience.
By linking playbooks with our current SLO-based approach to operations, we were confident that we could also increase awareness of SLOs in operations.
Let’s take a closer look at our current approach to operations at Merpay and how we went about implementing playbooks.
What is a playbook?
Originally referring to a set of strategies in American football, the term playbook is nowadays also used in business to mean a collection of strategies or knowledge.
In the world of IT, you often see "runbook" used to describe operations manuals, but today many companies also use playbooks to define their approach and mindset.
Engineer Involvement in Operations at Merpay
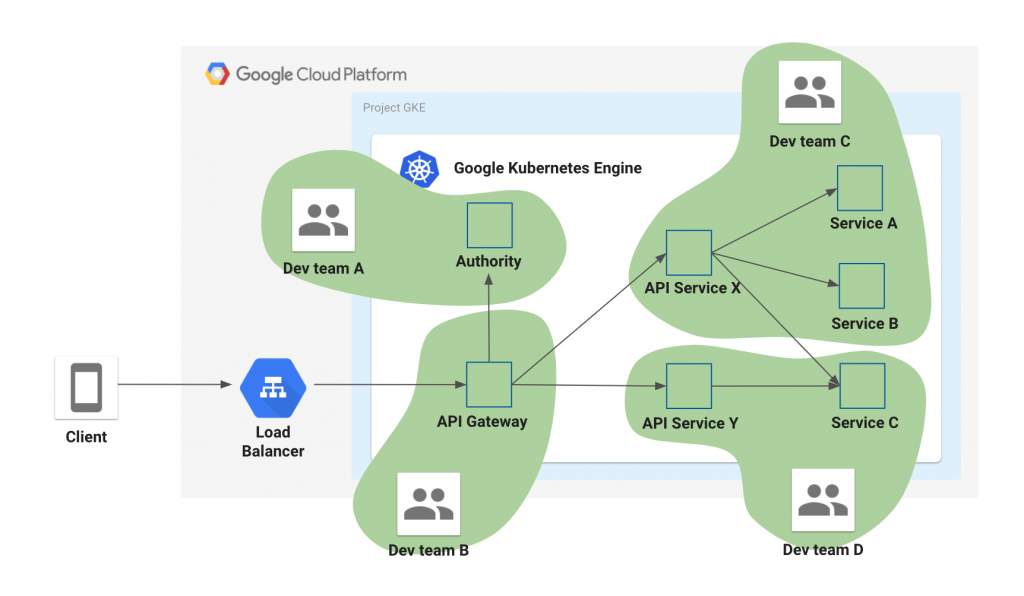
In order to providing our Merpay service, we utilize a system structure known as microservices architecture, where we build and operate multiple microservices.
Application engineers are in charge of a few microservices, handling everything from development to operations.
SRE will step in along the way to provide support for areas such as the shared platform and operations, to work with engineers on alert analysis, and to take on improvement tasks.
SRE also takes a proactive role, setting aside time to develop tools, promote the use of new mechanisms, and try out new approaches to more efficiently use SaaS.
In order to be less reactive in operations and not simply wait for an alert or issue to arise, SRE proactively makes improvements which can reduce the number of alerts and allow for more proactive operations. As a result, engineers can spend their time on more meaningful tasks.
On-Call Rotation System
At Merpay we have an on-call system for operations monitoring. Members are assigned to weekly rotations to conduct monitoring and other operations work. SRE also follows this system.
Each team decides the specific responsibilities of those assigned to on call. For SRE, the role includes the following responsibilities.
- Check the alerts and make an initial response
- Handle troubleshooting that has been escalated to those on call
- Update the production database, handle any tasks related to the Kubernetes infrastructure platform, and update the production infrastructure using Terraform
- Handle any other requests from other teams
- Write and share a summary on daily operations
Operations-Related System Building
Merpay uses Datadog as a monitoring platform, through which we receive application logs and metrics from almost all of our microservices.
When an alert is created, a notification will be sent to the respective Slack channels according to the alert settings. The member assigned to on call will then check the notification.
Based on the type of alert, the on-call member set on PagerDuty may also automatically receive a phone call.
Challenges
Since being assigned to on call myself, some of the challenges I’ve faced include the following.
- Multiple alerts coming up that result in SRE or the corresponding engineer in charge being contacted and woken up to help out, even though the given circumstances should not have prompted such a response.
- As the organization has grown, we have more and more microservices and increased complexity; it’s very difficult to understand what exactly has happened from the customer’s perspective when an alert comes up.
- From SRE’s perspective, it’s difficult to know why the on-call team decided not to take action on a given alert.
- Operation manuals are saved on multiple document platforms at the discretion of each individual and managed only thanks to the passion and good faith of certain engineers.
We’ve tried various solutions to the challenges described above. One of these approaches is the shared management of playbooks, where we are striving to improve engineer operations efficiency from the operations manual side.
Defining the Concept of the Playbook within Merpay
When it came time to add the playbook management feature to our existing operations system, we discussed the role it could play at Merpay and researched companies that have already implemented playbooks.
Approach #1 – PagerDuty
The runbook refers to the operations manual, and the broader concept which includes the runbook is known as a playbook.
If a runbook is a recipe or cookbook, then the playbook would be the guidebook for hosting a given social event—a wedding, for example. The cookbook is needed to effectively cook the meals, but the food is just one aspect of the entire event.
More concretely, a runbook is an overview of routine tasks, such as applying batches to servers and updating website SSL certificates.
(Reference)
Approach #2 – Amazon Web Services
Used for incident response, a playbook lists the steps to take in order to identify an issue.
Playbooks provide adequately skilled team members, who are unfamiliar with the system at hand, the guidance necessary to gather information, identify potential sources of failure, and determine root cause of issues.
Playbooks preserve the knowledge of your organization’s systems and policies. They ease the burden on key personnel by sharing their knowledge and enabling more team members to achieve the same outcomes.
(Reference)
Merpay’s Approach to Playbooks
Playbooks at Merpay are tied to the SLO and cover the entire process of handling an SLO alert, including what an engineer should do and what they should keep in mind when an SLO-based alert pops up.
The parts of these procedures pertaining to operations can then be separated out and reused as a runbook. Parts of existing manuals that can be easily reused have already been excerpted for use as runbooks and are organized so that they can be accessed from a playbook.
This perspective of making information available to all, in one shared location, can be applied for general information sharing and onboarding, just like the approach taken by Amazon Web Services.
Playbook Templates
The following is an example of an actual template. After any necessary information has been added, it will be saved on Github as a playbook.
---
title: Playbook1(Maybe similar to monitor name)
severity: <critical|warning>
---
## Effects
### Customer
- some effect for customers (free text)
### Employee
- some feature degradation (free text)
## What
- description of what happened
## Why
- description of why alert is kicked
## Who to contact
- Merpay SRE
- Platform Group Platform Infra
## Investigation
### Case A
- Run 1
- Run 2
- Run 3
### Case B
- Run 1
- Run 2
- Run 3
## Mitigation
### Case A
- Run 1
- Run 2
- Run 3
### Case B
- Run 1
- Run 2
- Run 3
## Post Check for Recovery
### Case A
- Run 1
- Run 2
- Run 3
### Case B
- Run 1
- Run 2
- Run 3See below for more information on each field.
Title
The title of the playbook.
Severity
Mercari and Merpay have defined several levels of severity, but for playbooks, we categorize alerts as either Critical (affects customers) or Warning (does not affect customers).
Effects
The scope of impact and specific situation that would require referencing this playbook.
Some microservices will affect not only customers but also employees, while others affect only employees. Therefore, that scope can be defined as either "Customer" or "Employee.”
What
The specific situation that would require referencing this playbook.
Why
Why the specific situation that would require reading this playbook has occurred.
Whom to contact
Whom to contact when in a situation that requires reading this playbook. Here we would include the Slack ID of a given team.
Investigation
The investigation method and approach for breaking down the issue. Investigations that require documenting multiple cases should be written out in separate fields.
Mitigation
Provisional measures to take. Investigations that require documenting multiple cases should be written out in separate fields. Links for existing manuals that can be reused will be included here.
Post Check for Recovery
Steps to determine whether or not the problem has been resolved. Investigations that require documenting multiple cases should be written out in separate fields. Links for existing manuals that can be reused will be included here.
SLO
Each Merpay microservice is operated based on a defined SLO (service level objective). An SLO essentially refers to a target level of reliability required to meet the expectations of customers and to reach a certain degree of customer satisfaction.
To learn more about SLOs, see here for a presentation by SRE Team member @foostan at Merpay Tech Fest 2021. (available only in Japanese)
Playbook Linked to SLO
SLOs are the focus of operations at Merpay. To evaluate our operations, we look at whether or not we have met our SLO and the extent to which we are developing features that increase customer satisfaction.
More specifically, each microservice has a few SLOs with an alert set up for each. An alert popping up means that the error budget has decreased and we have moved farther away from achieving our SLO, prompting us to take action.
In other words, the fewer alerts created in order to achieve our SLO the better, and if an alert does pop up, we should act swiftly to fix the issue.
By having the right playbook available for immediate access to predefined steps and approaches for solving an issue, we can more easily reduce loss of error budget and also maintain and increase the reliability of our service.
To make this process possible, we developed a mechanism to make playbooks and link them to the proper SLO alert.
Playbook System Mechanism
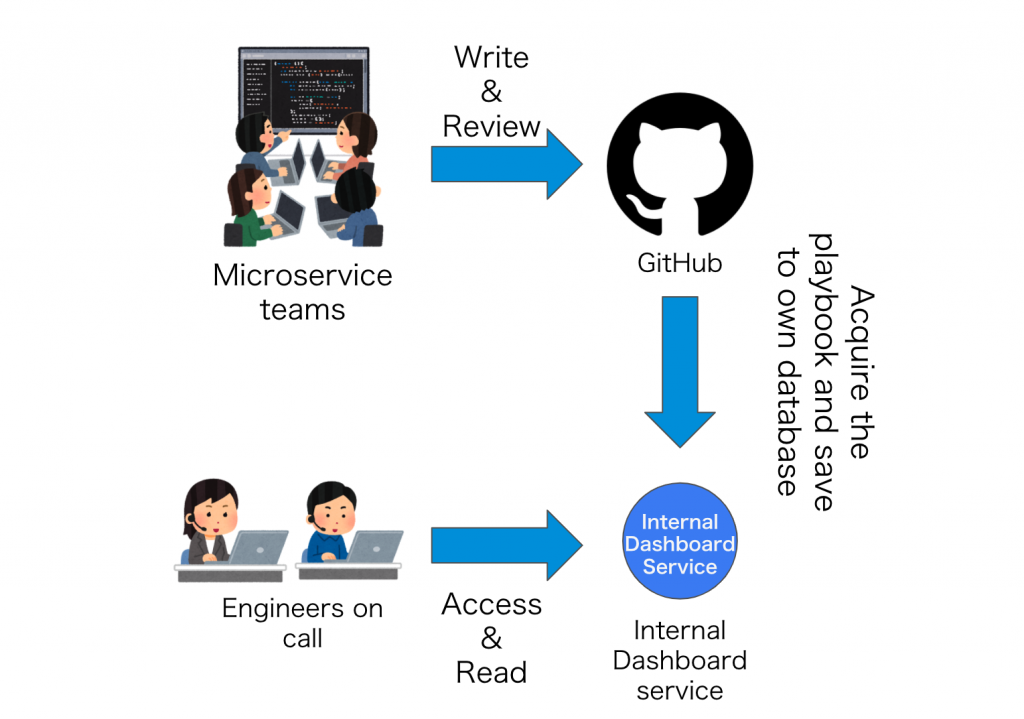
Playbooks must be created within the directory of the specified Github repository, which is the Terraform repository used for centralized management of our microservices.
Once one or a few playbooks have been added to the repository, a pull request is made. After being reviewed and confirming there are no issues, it will be merged. After being merged, it will be added to the internal dashboard service.
The internal dashboard service manages various information all in one place for easy searching and access.
We added features for including and displaying playbooks to our dashboard service.
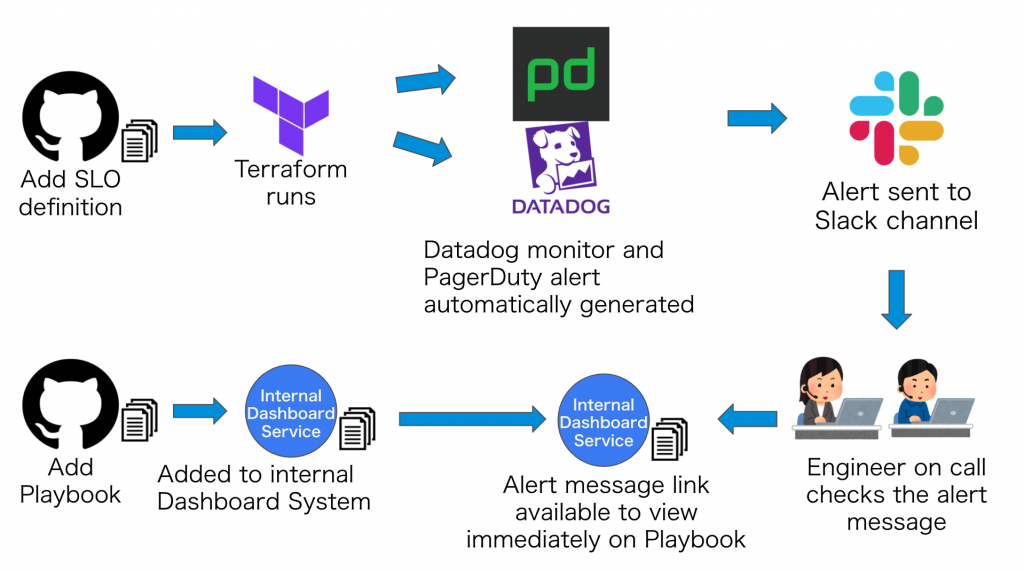
We also already had a mechanism in place where defining an SLO will run Terraform and automatically create a Datadog monitor. We made some changes to this mechanism which allows us to specify a playbook when defining an SLO.
Specifying a playbook for an existing SLO will add a link to the playbook in the monitor alert message. As a result, the engineer on call can click on the link in the alert message to go directly to the playbook on the dashboard service, which makes it possible to more quickly take the necessary actions to solve the problem.
To learn more about automatic generation of SLO related monitoring resources, see here. for an article by fellow SRE Team member @T. (available only in Japanese)
Benefits of Implementing the Playbook System
Using playbooks for each microservice has the following benefits.
- Playbooks are all saved on GitHub.
- Allows for an intuitive process where one can create and update a playbook by making a pull request on GitHub.
- Allows for use of the pull request review feature.
- There are templates available that indicate exactly what you need to write.
- Up until now we’ve left it up to each person to decide what to write and in how much detail. Having these guardrails gives us consistency in playbook quality.
- With a consistent set of fields, the playbooks are easy to read even when working with unfamiliar microservices.
- The alert message includes a link to the playbook, allowing for quick access when on call.
- This quick and easy access means we can more easily achieve our SLO with less error budget loss.
- By making the playbooks more thorough, we can also use them for onboarding new members.
Future Plans
We have just begun this playbook initiative. For now we will have the engineers of each microservice give it a try and provide us with any feedback they have so we can make improvements.
For example, on the dashboard service we already have a feature to see a list of individual team members and of teams managing specific microservices. Engineers working on call could feel more confident taking on their responsibilities if we could better utilize this feature to enable searching for playbooks on the team level.
Playbooks are tied to SLOs. Brushing up the way we use SLOs can also make our playbooks easier to use.
We look forward to working together to continue to make improvements by also fine tuning our SLO-related features.
We’re Hiring!
Here at Merpay we are at work on many exciting projects, including helping out with the launch stage of Mercoin. We need more people to join us!
We have openings for SRE and SRE Manager. Please apply if you are at all interested in any of the current openings.
- Software Engineer (Site Reliability) [Mercoin/Merpay]
- Engineering Manager (Site Reliability) [Mercoin / Merpay]
Stay tuned for more articles about technology at Merpay and our engineering organization for the rest of Merpay Tech Openness Month 2021. (available only in Japanese)
The next article will be about Merpay Android Team onboarding for a seamless launch, by @kenken_merpay.
References
- American football plays – Wikipedia
- What Is a Playbook in Business? | Indeed.com
- What is a Runbook? | PagerDuty
- What is a Runbook? | PagerDuty
- Merpay Tech Fest 2021/Use case of SLOs in Merpay Let’s Define Reliability – Speaker Deck (available only in Japanese)
- Maintain SLO 2020 | Mercari Engineering (available only in Japanese)




