* This article is a translation of the Japanese article written on September 7, 2021.
Hello. This is @orfeon. I’m an engineer on the Merpay Solutions Team.
This article is for day 5 of Merpay Tech Openness Month 2021.
The Merpay Solutions Team is responsible for several duties, including internal technical consulting and technical research, and providing solutions for shared issues discovered across divisions. I focus mainly on providing solutions to data-related issues. I release some of my work as OSS.
In this article, I cover one way to easily provide search functionality (with some conditions). Search functionality is required in various situations, but implementing it can be difficult due to issues such as operational loads.
Basic idea
Searching is used frequently and in many different settings, including text or location searching. However, to build and run a search server you need to take lots of factors into consideration, including data consistency and monitoring. I think this causes hesitation among many engineers, and I wondered whether it might be possible to more easily build a search API server if we set some minor usage conditions, such as not updating data in real-time or excluding data too large to be managed with a single server.
More specifically, we could include the search index file directly in the container image we will use as the search API server. This would allow us to ensure data consistency as data is updated and deleted, as well as eliminate tedious tasks like data migration when the index is changed. We could also deploy the search container image on an environment such as Cloud Run or Kubernetes Engine in order to reduce the operational load of the server cluster. Finally, another options would be to use Cloud Dataflow to take the data we want to target for search and incorporate it easily from various data sources into the search index file by specifying SQL parameters.
This should make operation much easier, but would also result in the following constraints (mentioned previously).
- Data cannot be updated too frequently (daily frequency)
- Only data contained within a single container image can be handled
In other words, the solution covered would allow for a search API to be easily used in a project where these constraints would be acceptable.
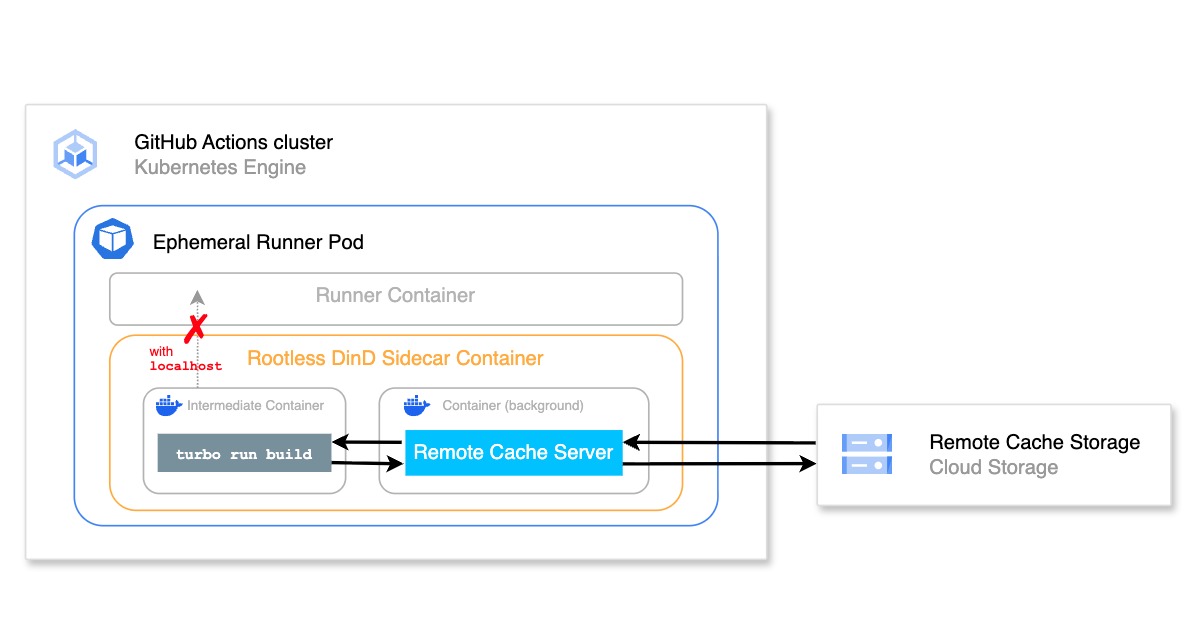
Overall system configuration
The following figure provides the basic configuration of the entire search API server. The following explanation assumes that data is loaded from BigQuery (the data source to search) into Apache Solr (the search engine), and that the search server runs on Cloud Run.

Cloud Dataflow is used for search index generation. Specified SQL parameters are used to load the data to search from BigQuery, and the specified schema file is used to generate the Solr index file. We register this as a Flex Template ahead of time, and specify SQL parameters for execution during index generation, so that we don’t need to modify code each time the index content changes when executing Cloud Dataflow jobs. (The Cloud Dataflow Flex Template introduced here has been released as a Mercari Dataflow Template module.) In this solution, we’re using query results from BigQuery as our search index, but you can simply switch the module if you want to import data from sources such as Cloud Spanner or Cloud Datastore.
We use Cloud Build to generate an Solr search server container from the index file. We then import the index file generated by Cloud Dataflow and generate the Solr search server container image. We use a repository such as GitHub to manage files required for building so that we can load and use these files from the repository when we start the build. We also create a startup trigger ahead of time, and will execute this trigger when starting from Cloud Scheduler. This will be explained later.
We use Cloud Scheduler to periodically and separately run Cloud Dataflow and Cloud Build. The run time is staggered so that the Cloud Build search container image generation process kicks off after index file generation using Cloud Dataflow. (We could also output a file when a job is completed on Dataflow, and then start Cloud Build [for search container image generation] through Cloud Functions, but we will be starting processes staggered in the interest of keeping the configuration simple.)
This allows us to deploy a Solr search server on Cloud Run, with a search index containing the latest data on the cycle specified by Cloud Build. If there is a service for which we want to enable searching, we can now accomplish this by sending search requests to Cloud Run.
System build procedure
Users need to prepare the following configuration information to build a search API server:
- Solr search schema file
- SQL to provide search data
- Pipeline settings file for use in building the search index
- Dockerfile to build the search API server
- Build settings file to deploy the search API server on Cloud Run
- Cloud Scheduler startup configuration
The first three items in this list will be modified each time search index requirements change. The next two will be modified when the API server is updated, such as upgrading to the next version of Solr. The last one will be modified whenever the timing at which the search index is updated is changed.
Now, let’s take a closer look at these settings.
Solr search schema file
Our search index schema is defined for Solr, so we define the following XML as our search schema based on our search requirements.
<?xml version="1.0" encoding="UTF-8"?>
<schema name="content" version="1.5">
<fields>
<field name="ID" type="string" indexed="true" stored="true" required="true" />
<field name="Name" type="string" indexed="false" stored="true" required="false" />
<field name="Address" type="string" indexed="false" stored="true" required="false" />
<field name="Category" type="string" indexed="true" stored="true" docValues="true" required="false" />
<field name="CreatedAt" type="date" indexed="true" stored="true" docValues="true" required="false" />
<field name="LastDate" type="string" indexed="true" stored="true" docValues="false" required="false" />
<field name="Location" type="location" indexed="true" stored="true" required="true" />
<field name="Index" type="text_ja" indexed="true" stored="true" multiValued="true" />
</fields>
<uniqueKey>ID</uniqueKey>
<copyField source="Name" dest="Index"/>
<copyField source="Address" dest="Index"/>
<copyField source="Category" dest="Index"/>
<types>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="long" class="solr.LongPointField" sortMissingLast="true"/>
<fieldType name="double" class="solr.DoublePointField" sortMissingLast="true"/>
<fieldType name="date" class="solr.DatePointField" sortMissingLast="true"/>
<fieldType name="location" class="solr.LatLonPointSpatialField" docValues="true"/>
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="2"/>
</analyzer>
</fieldType>
</types>
</schema>This XML specifies four major elements as search index settings: the individual “field” elements under the “fields” element specify the field name, data type, and indexed conditions to use for the search index; the “uniqueKey” element specifies a unique field name; the “types” element specifies the data type used by the field, as well as text analysis content (for morphological analysis, etc.) when required; and ehe “copyField” elements are used when we want to gather fields together for indexing. For detailed specifications, refer to the Solr schema definition document.
SQL to provide search data
SQL, which provides search data, is used to define queries for loading data from BigQuery, that matches the field names and data types from the search schema defined previously. The search index is recreated in whole each time, so instead of using differential updating, we define this so that all data required for searching will be retrieved.
Pipeline settings file for use in building the search index
The pipeline settings file is a Mercari Dataflow Template settings file used to convert data loaded from BigQuery (using specified SQL parameters) into a Solr search index file and then save it. It is defined as follows:
{
"sources": [
{
"name": "BigQueryInput",
"module": "bigquery",
"parameters": {
"query": "gs://example-bucket/query.sql"
}
}
],
"sinks": [
{
"name": "SolrIndexOutput",
"module": "solrindex",
"input": "BigQueryInput",
"parameters": {
"output": "gs://example-bucket/index.zip",
"coreName": "MyCore",
"indexSchema": "gs://example-bucket/schema.xml"
}
}
]
}We use the SQL parameters defined previously in the BigQuery Source module to specify the GCS path containing the Solr schema file in the SolrIndex Sink module, and the GCS path of the index file output destination. We save this settings file in GCS, and can then specify this GCS path during startup launched by Cloud Scheduler (explained later) to run the Dataflow job used to create a Solr index file from BigQuery.
To run the Dataflow job from Cloud Scheduler using the defined settings file, we register the Mercari Dataflow Template Flex Template in Container Registry (GCR) and register the template file in GCS.
First, we clone the Mercari Dataflow Template from GitHub, and then execute the following command to register it in GCR:
mvn clean package -DskipTests -Dimage=gcr.io/{myproject}/{templateRepoName}Next, we execute the following command to register the template file used to start the Dataflow job from the container registered in GCR:
gcloud dataflow flex-template build gs://{path/to/template_file} \
--image "gcr.io/{myproject}/{templateRepoName}" \
--sdk-language "JAVA"Dockerfile to build the search API server
As shown in the example below, the search server Dockerfile is based on an official Solr image, but configured with the search index file created by Cloud Dataflow incorporated into the image.
FROM solr:8.11
USER root
RUN apt-get update && apt-get install -y apt-utils libcap2-bin
RUN setcap CAP_NET_BIND_SERVICE=+eip '/usr/local/openjdk-11/bin/java' && \
echo "/lib:/usr/local/lib:/usr/lib:/usr/local/openjdk-11/lib:/usr/local/openjdk-11/lib/server:/usr/local/openjdk-11/lib/jli" > /etc/ld-musl-x86_64.path
USER solr
ARG _CORE
COPY --chown=solr:solr ${_CORE}/data/ /var/solr/data/${_CORE}/data/
COPY --chown=solr:solr ${_CORE}/conf/ /var/solr/data/${_CORE}/conf/
ADD --chown=solr:solr ${_CORE}/core.properties /var/solr/data/${_CORE}/
ADD --chown=solr:solr ${_CORE}/solrconfig.xml /var/solr/data/${_CORE}/conf/
ENV SOLR_PORT=80In this settings file, the section under “${_CORE}” would be used to define the search index file generated by Cloud Dataflow. “${_CORE}” indicates the core name for Solr, and will be inserted as a variable when running Cloud Build. This Dockerfile is managed on GitHub or another repository.
Build settings file to deploy the search API server on Cloud Run
The Cloud Build build settings file defines the process for generating a Solr container image from the search index file and deploying it to Cloud Run as follows:
- Copy a local version of the index file generated by Cloud Dataflow
- Decompress the compressed search index file
- Build the Solr container image using the previously defined Dockerfile
- Push the built container image to GCR
- Update the Cloud Run instance from the image registered to GCR
Here is an example configuration:
steps:
- name: 'gcr.io/cloud-builders/gsutil'
args: ["cp", "gs://$PROJECT_ID-dataflow/$_CORE.zip", "index.zip"]
- name: 'gcr.io/cloud-builders/gsutil'
entrypoint: "unzip"
args: ["index.zip"]
- name: 'gcr.io/cloud-builders/docker'
args: ["build", "-t", "gcr.io/$PROJECT_ID/myindex", "--build-arg", "_CORE=$_CORE", "."]
- name: 'gcr.io/cloud-builders/docker'
args: ["push", "gcr.io/$PROJECT_ID/myindex"]
- name: 'gcr.io/cloud-builders/gcloud'
args: ["run", "deploy", "mysearch",
"--image", "gcr.io/$PROJECT_ID/myindex",
"--platform", "managed",
"--region", "$_REGION",
"--concurrency", "300",
"--cpu", "2",
"--memory", "4Gi",
"--port", "80",
"--min-instances", "1",
"--no-allow-unauthenticated"]
timeout: 3600s
substitutions:
_CORE: MyCore
_REGION: us-central1This build settings file is managed in GitHub or another repository.
Note that, as a preliminary preparation step, we also configure a trigger to start Cloud Build from Cloud Scheduler, which will be discussed next. We specify the repository managing the build file and Dockerfile, as the repository to serve as the trigger source. We specify the build file path defined here as the Cloud Build configuration file. We define any variable we want to insert during execution, based on any other requirements we have. Finally, we take note of the ID of the trigger that we set previously, as it will be used as the address for starting from Cloud Scheduler (described in the next section).
Cloud Scheduler startup configuration
We use Cloud Scheduler to periodically run the Cloud Dataflow Flex Template and Cloud Build trigger we prepared previously. In the following example, a job is scheduled to run every morning at 4:30 to tell Cloud Dataflow to generate a Solr index file.
gcloud scheduler jobs create http create-index \
--schedule "30 4 * * *" \
--time-zone "Asia/Tokyo" \
--uri="https://dataflow.googleapis.com/v1b3/projects/${PROJECT_ID}/locations/${REGION}/flexTemplates:launch" \
--oauth-service-account-email="xxx@xxx.gserviceaccount.com" \
--message-body-from-file=body.json \
--max-retry-attempts=5 \
--min-backoff=5s \
--max-backoff=5m \
--oauth-token-scope=https://www.googleapis.com/auth/cloud-platform ^
--project myprojectA body.json file contains request content for the API that starts the Flex Template for Cloud Dataflow. This file specifies the Flex Template GCS path and the GCS path containing the pipeline settings file, which were registered previously.
{
"launchParameter": {
"jobName": "myJob",
"parameters": {
"config": "gs://myproject/pipeline.json"
},
"containerSpecGcsPath": "gs://{path/to/template_file}"
}
}In the following example, the Cloud Build trigger is set to start every morning at 5:00.
gcloud scheduler jobs create http deploy-server \
--schedule "0 5 * * *" \
--time-zone "Asia/Tokyo" \
--uri="https://cloudbuild.googleapis.com/v1/projects/myproject/triggers/${TriggerID}:run" \
--oauth-service-account-email="xxx@xxx.gserviceaccount.com" \
--message-body-from-file=body.json \
--max-retry-attempts=5 \
--min-backoff=5s \
--max-backoff=5m \
--oauth-token-scope=https://www.googleapis.com/auth/cloud-platform \
--project=myprojectThe body.json file is used to prepare a local JSON file indicating the branch name to use during the build, as shown below.
{ "branchName": "main" }Example service using the search API
As an example making use of the solution introduced here, let’s take a look at a service that uses data accumulated in BigQuery to visualize affiliated merchant information for internal use.
The service itself runs on AppEngine, and in the first part we configure IAP (Identity-Aware Proxy) to perform employee authentication.
Service-to-service authentication is used for requests from AppEngine to the search API deployed on Cloud Run.

We can use Solr location search functionality to specify filtering conditions and display matching merchants as a heat map. In the example query, we are searching for ramen restaurants in which payment has recently been made using our services. We can create a visual display of merchants as a heat map or as individual locations pinned on a map. One possible use for this would be to easily find merchants without any recent payments made using our services; this could help us figure out how to increase usage of our services.
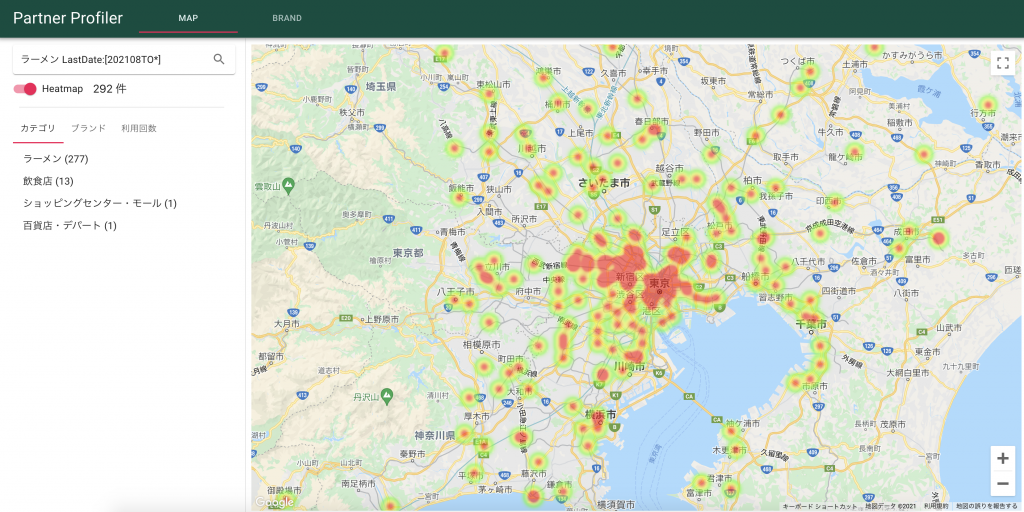
We can use the search API for scope searching, sorting, and facet aggregation, in addition to location searching and text searching. In other words, it’s not only a search engine but a simple database that also supports graphing functionality in addition to maps. For example, you could graph usage trends by merchant or brand.
Conclusion
In this article, I introduced a solution to building a simple search API server on Cloud Run. This solution could be used in situations where you want to introduce simple searching (such as for a service used internally or developed for individual use)—as long as there isn’t too much data to handle and it would be acceptable to update only daily. Running the index on a single server should not present any performance issues as long as the data is not too complicated, even for up to about 10 million entries. This means it should be useful in a wide range of situations.
We generate and accumulate all sorts of data every day on BigQuery, and I think there are still many new potential ways to make use of data that is hiding in plain sight. I hope to continue to provide solutions that make it easier to use data in various situations, so that we can use this hidden data better and apply it to more situations.