Merpay Advent Calendar 2020 の10日目の記事です。
こんにちは。Merpay Solutions Teamの @orfeon です。
3ヶ月ほど前のブログ記事でメルペイでのFlexTemplateの活用例を紹介しましたが、ここで使われていたソフトウェアを先日、OSSとして公開しました。
この記事ではこのOSSとして公開したMercari Dataflow Templateについて紹介します。
BigQueryから取得したデータを別のDatabaseサービスに保存したり、異なるデータソースからのデータをSQLで結合・加工したり、AWSのS3にデータを出力したりなどなど、GCP上での何らかのデータの処理に関わられている方は役立つケースがあるかもしれないのでぜひご一読頂ければ幸いです。
Mercari Dataflow Templateとは何か
Mercari Dataflow Template (以下MDT)は GCP の 分散データ処理サービスである Cloud Dataflow を使ってデータ加工・処理を手軽に行うためのツールです。
社内でもマイクロサービスをまたがるデータソース間のデータ結合・加工・保存や、Databaseサービスのバックアップ・リストアなどに用いられています。
Cloud Dataflowはフルマネージドな分散データ処理サービスです。Cloud Dataflowによるデータ処理にはデータ処理パイプラインのポータビリティフレームワークであるApache Beamを利用します。Apache Beamで記述したデータ処理プログラムをビルドしてCloud Dataflowにサブミットすると、処理に必要なサーバが自動的に立ち上がりデータ処理が分散実行されます。さらにデータ量や処理負荷に応じたオートスケールや処理完了後のサーバの停止も行ってくれます。そのため我々はデータ処理のためのプログラミングに専念することができます。
ある程度定型的なデータ処理であれば今回公開したMDTを使うことで、データ処理のプログラミングをも省略して、データ処理内容をパイプラインファイルに宣言的に定義するだけでデータ処理を行えます。
ここではMDTを使ってデータ処理が簡単にできることを理解してもらうために使い方の例を紹介します。
利用例1: BigQuery to Spanner
まずはシンプルな例としてBigQueryからSQLで取得したデータをSpannerに保存する例を紹介します。
まず以下のようなパイプラインファイルを定義してGCS(Google Cloud Storage)に保存します。
パイプラインファイルではデータの読み込み元と書き込み先を定義するモジュールとして、それぞれbigqueryとspannerをsourcesとsinksフィールドで指定しています。
{
"sources": [
{
"name": "bigqueryInput",
"module": "bigquery",
"parameters": {
"query": "SELECT * FROM `myproject.mydataset.mytable`"
}
}
],
"sinks": [
{
"name": "spannerOutput",
"module": "spanner",
"input": "bigqueryInput",
"parameters": {
"projectId": "myproject",
"instanceId": "myinstance",
"databaseId": "mydatabase",
"table": "mytable"
}
}
]
}次に以下のようなにコマンドを実行します。
(ここではMDTをgs://example/templateにデプロイ、パイプラインファイルをgs://example/pipeline.jsonに保存したとします)
gcloud dataflow flex-template run bigquery-to-spanner \
--template-file-gcs-location=gs://example/template \
--parameters=config=gs://example/pipeline.jsonしばらくするとDataflow Jobが立ち上がって処理が実行されます。
こういった処理を行う際にありがちな単純だけれどひたすら煩雑な、異なるデータサービス間のスキーマ変換処理定義は全て自動で行われます。
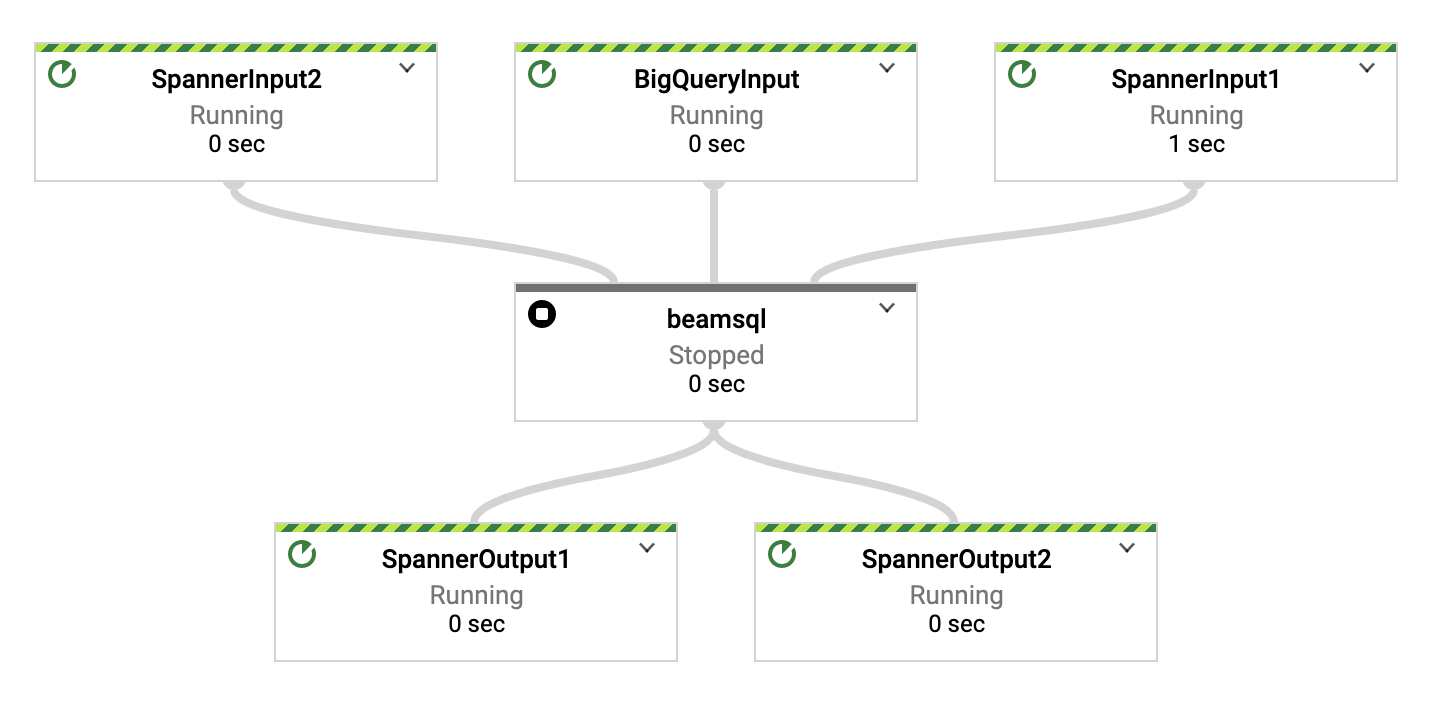
利用例2: 複数のリソースからデータをSQLで結合する
データの単純な移動だけではなく、SQLによる加工処理なども間に差し込むことができます。
以下のパイプラインファイルの例ではBigQueryへのクエリ結果とSpannerテーブルとをSQLを使ってJOINして結果をSpannerのテーブルに保存しています。
先の例で出てきたsourcesとsinksに加えてデータ処理用のモジュールを定義するtransformsで、SQLで入力データを処理するためのbeamsqlモジュールを指定しています。
{
"sources": [
{
"name": "BigQueryInput",
"module": "bigquery",
"parameters": {
"query": "SELECT BField1, BField2 FROM `myproject.mydataset.mytable`"
}
},
{
"name": "SpannerInput",
"module": "spanner",
"parameters": {
"projectId": "myproject",
"instanceId": "myinstance",
"databaseId": "mydatabase",
"table": "mytable",
"fields": ["SField1","SField2"]
}
}
],
"transforms": [
{
"name": "beamsqlTransform",
"module": "beamsql",
"inputs": [
"BigQueryInput",
"SpannerInput"
],
"parameters": {
"sql": "SELECT BigQueryInput.BField1 AS Field1, IF(BigQueryInput.BField2 IS NULL, SpannerInput.SField2, BigQueryInput.BField2) AS Field2 FROM BigQueryInput LEFT JOIN SpannerInput ON BigQueryInput.BField1 = SpannerInput.SField1"
}
}
],
"sinks": [
{
"name": "SpannerOutput",
"module": "spanner",
"input": "beamsql",
"parameters": {
"projectId": "anotherproject",
"instanceId": "anotherinstance",
"databaseId": "anotherdatabase",
"table": "anothertable",
"createTable": true,
"keyFields": ["Field1"]
}
}
]
}その他にもBigQueryからParquetなどで指定したフィールドの値や日付ごとにGCSにファイル出力したり、SpannerからBigQueryやSpannerテーブルにデータ移動したりなど。事前に定義されたモジュールを組み合わせることで様々なデータ処理ができます。
このようにMDTを使うことでデータ処理内容をパイプラインファイルとして宣言的に定義して、Dataflow にサブミットすることでデータ処理を実行できます。
その他のパイプラインファイルの例もGitHubにexampleを記載しているので、興味を持たれた方はぜひ自分がやりたいデータ処理に近いファイルがあるか探してみてください。
使い方
ここからはMDTの使い方をもう少し詳しく紹介したいと思います。
基本的な使い方はMDTをデプロイした上で、処理したい内容をパイプラインファイルとして書いてGCSにアップロードし、gcloudやDataflowのtemplate起動用のREST APIを使って起動するという流れになります。
ここでは処理内容の記述方法と実行方法について紹介します。
(MDTのデプロイ方法はドキュメントを参照ください)
パイプラインファイルの定義方法
パイプラインファイルは主に、データ読込元を定義するsourceモジュール、処理内容を定義するtransformモジュール、データ書込先を定義するsinkモジュールを記述するためのフィールドであるsources、transforms、sinksから構成されています。
{
"sources": [
{ "name": "input1", "module": "bigquery", "parameters": {...}},
...
],
"transforms": [
{ "name": "trans1", "module": "beamsql", "inputs": ["input1"], "parameters": {...}},
...
],
"sinks": [
{ "name": "output1", "module": "spanner", "input": "trans1", "parameters": {...}},
...
]
}source、transform、sinkモジュールでは、nameとmoduleフィールドは必須です。moduleフィールドで利用したいモジュール名を指定します(提供されているモジュールの一覧はGitHubのリポジトリを参照ください)。nameはpipelineの処理のステップ名を指定するものでパイプラインファイル内でユニークになるように指定します。
transformとsinkモジュールにはそれぞれ処理・出力対象となる入力ステップ名を指定するinputs, inputフィールドがあります。パイプラインとして各ステップを繋げていく際には入力としたいステップ名をこれらinputs,inputで指定します。
parametersフィールドでは各モジュール特有の設定フィールドを指定します。

入出力の関係は1対多、多対多も可能です。読み込んだデータを別々に処理して出力させたり、並列に複数テーブルのデータをコピーしたりもできます。
またtransformモジュールでは、あるtransformモジュールの処理結果を別のtransformモジュールが受け取ることで多段階に加工処理を重ねることもできます。(BeamSQLはサブクエリは未対応ですが、beamsqlモジュールを複数接続することで同じ処理を定義できます)
動的なパイプラインファイルの構成
パイプラインファイルはテンプレートエンジンApache FreeMarkerによる動的な生成にも対応しています。
例えばFreeMarkerの記法に従って以下のような変数を使った設定を定義します。
{
"sources": [{
"name": "datastoreInput",
"parameters": {
"projectId": "myproject",
"gql": "SELECT * FROM MyKind WHERE created_at > DATETIME('${current_datetime}')"
}
}],
...
}実行時に以下のように変数名に接頭辞template.を付けたパラメータを追加で指定することで、パイプラインファイルで定義した変数を置き換えて実行できます。
gcloud dataflow flex-template run bigquery-to-spanner \
--template-file-gcs-location=gs://example/template \
--parameters=config=gs://example/pipeline.json \
--parameters=template.current_datetime=2020-12-01T00:00:00Zパラメータ置き換えだけでなく、以下のようにFreeMarkerの制御構文を使って処理グラフ構造の構築もできます。
{
"sources": [
<#list ["Table1", "Table2", "Table3"] as table>
{
"name": "input${table}",
"module": "bigquery",
"parameters": { "query": "SELECT * FROM mydataset.${table}" }
},
</#list>
],
...
}実行方法
ここからは定義したパイプラインファイルを使ってDataflow のJobを実行するやり方について紹介していきます。
コマンドラインによる実行
これまでの例でも紹介してきた通り、gcloudコマンドを使って先に準備したパイプラインファイルを指定してJobを実行できます。
gcloud dataflow flex-template run bigquery-to-spanner \
--project=myproject \
--region=us-central1 \
--template-file-gcs-location=gs://example/template \
--parameters=config=gs://example/pipeline.jsonFreeMarkerによる変数を指定する場合は先に紹介した通り、変数名に接頭辞template.を付けたパラメータを追加で指定することで、パイプラインファイルで定義した変数を置き換えて実行できます
gcloud dataflow flex-template run bigquery-to-spanner \
--project=myproject \
--region=us-central1 \
--template-file-gcs-location=gs://example/template \
--parameters=config=gs://example/pipeline.json \
--parameters=template.current_datetime=2020-12-01T00:00:00Zまた、{ステップ名}.{モジュールのパラメータ名}をパラメータとして追加で指定することで、各ステップのパラメータを置き換えて実行もできます。
gcloud dataflow flex-template run bigquery-to-spanner \
--project=myproject \
--region=us-central1 \
--template-file-gcs-location=gs://example/template \
--parameters=config=gs://example/pipeline.json \
--parameters=step1.query=’SELECT * FROM mydataset.mytable1’ \
--parameters=step2.query=’SELECT * FROM mydataset.mytable2’REST APIによる実行
gcloudコマンドによる実行では裏側でCloud Dataflow の REST API が呼ばれています。
プログラムを使ってTemplateからDataflow Jobを実行したい場合などは直接このAPIを利用して実行できます。次に紹介するCloud Schedulerからの実行ではこのAPIを使って実行しています。
以下はcurlコマンドを使ってREST APIからJobを実行する例です。
PROJECT_ID=[PROJECT_ID]
REGION=us-central1
curl -X POST -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" "https://dataflow.googleapis.com/v1b3/projects/${PROJECT_ID}/locations/${REGION}/templates:launch"`
`"?dynamicTemplate.gcsPath=gs://example/template" -d "{
'parameters': {
'config': 'gs://example/pipeline.json'
}
'jobName':'myJobName',
}"※ gcloudとREST APIとでFlexTemplateのデプロイ方法が少し異なるので注意ください
Cloud Schedulerからの定期実行
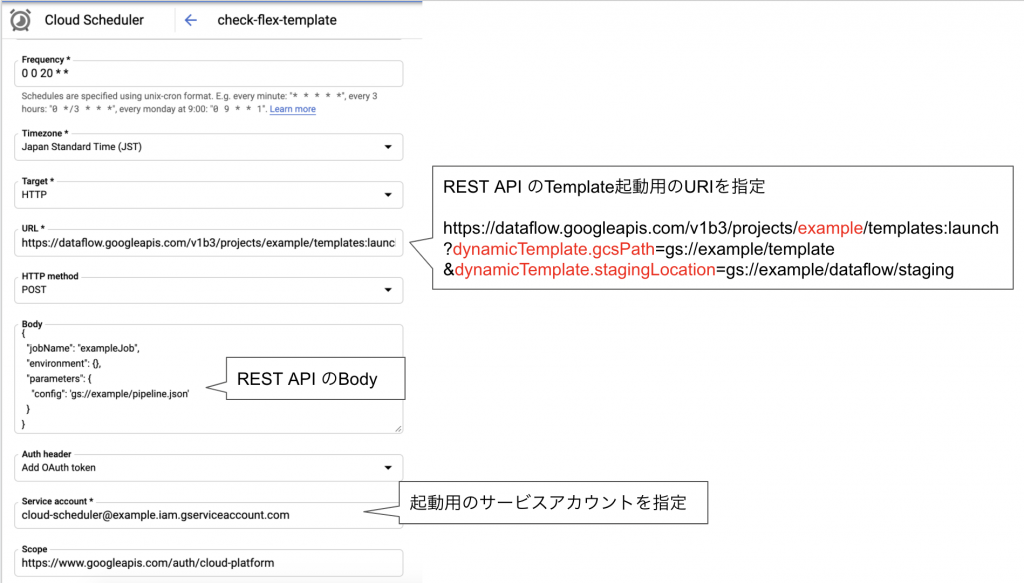
定期的に実行したい場合には先に紹介したREST APIを使ってCloud Schedulerから定期実行もできます。
以下のようにCloud Schedulerの設定でTargetをHTTPにして先に紹介したREST APIを実行するよう設定します。
定期実行で起動時間に基づいた変数を指定したい場合には、FreeMarkerの記法に基づいて実行時に現在時間が代入される変数をパイプラインファイルに記述もできます。
以下の例は起動日時をHour単位で丸めて起動Hour以降のデータだけを取得しています。
{
sources: [
{
"name": "datastoreInput",
"module": "datastore",
"parameters": {
"projectId": "myproject",
"gql": "SELECT * FROM MyKind WHERE created_at > DATETIME('${.now?string['yyyy-MM-dd']}T${.now?string['HH']}:00:00Z'))"
}
}
],
}仕組み
ここではMDTの仕組みについても少し紹介したいと思います。
MDTはCloud Dataflowを動かすためのApache Beamのフレームワークを使った実装となっていますが、利用者がデータ処理で使う際にいちいちソースコードからビルド・デプロイしないでも使えるように、FlexTemplateという機能を使って実行できるように実装されています。
ここからはまずFlexTemplateとは何かについて説明します。
そもそもFlexTemplateが必要となる背景として、データパイプラインを開発する人と利用する人で役割分担できるようにしたいというニーズがありました。
この目的のためにCloud DataflowにはTemplateという機能が提供されています。
Dataflowのパイプラインのプログラムを書く人は実行時に受け取ったパラメータを処理内容に反映するようなコードを書いてデプロイし、パイプラインを使う人はDataflowのTemplateを起動するAPIでパラメータを指定して実行します。
ただ全てのパラメータを実行時に反映できるわけではありません。例えばパイプラインの構造自体を実行時に変更することはできません。(例えばBigQueryからCloud Spannerにデータを移すTemplateを作った場合、BigQueryへのクエリや宛先テーブルを指定することはできても、BigQuery以外の読み込み先、Spanner以外の書き込み先を実行時に変更するようなことはできません)
またデータ読み書き用にフレームワークで提供されている一部の組み込みコンポーネントはこうしたパラメータに対応していません。例えばDataflow実行時に指定したクエリでCloud Spannerへのクエリ結果を取得するTemplateを作るには、自前で実行時パラメータを受け取ってCloud Spannerへクエリを実行する処理を作る必要がありました。
これはパイプラインの構造が、パイプライン開発者がビルドし&デプロイするタイミングで確定する仕組みになっているからです。
このため利用者がちょっとしたパラメータを実行時に変更することはできても、処理グラフ構造を変更するようなTemplateを提供することは難しくなっていました。

FlexTemplateはこうした課題を解決するため、パイプライン開発者がTemplateを手元の環境やCI環境などでビルドしてデプロイしていたのを、利用者による実行時にビルド・デプロイして実行できるようにした仕組みになります。
FlexTemplateでは、これまで開発者が手元やCI環境などで行っていたビルド・デプロイを実行するためのコンテナイメージを作成してGoogle Container Registry(GCR)に登録します。その際にGCR上に登録されたイメージの場所を指定したFlexTemplate起動用のファイルをGCSに置きます。
利用者はJobを実行する際にこの起動用ファイルを置いたGCSのパスをパラメータと指定してDataflow のFlexTemplateを起動するAPIを実行します。
そうするとDataflow のAPIサービスはDataflow Jobを開始する前にまずGCEインスタンスを起動します。起動されたGCEインスタンスは先に指定されたGCSのパスにあるGCRからコンテナイメージを読み出して、Templateのビルドとデプロイを実行します。この際にパイプラインの内容が確定します。GCEはTemplateのデプロイを終えた後にそのTemplateからDataflow のJobを起動した後に削除されます。

MDTでは利用者が実行時に動的にパイプラインを組み立てるためにこのFlexTemplateの機能を利用しています。
MDTは実行時にJSON形式として受け取けとった処理内容のグラフをパースしてパイプラインの処理を組み立てています。
各種モジュールは共通のメソッドを持つクラスとして実装されており、実行時にJSONをパースして得た処理のグラフ構造からこれらのモジュールを繋ぎ合わせることでパイプラインを組み立てています。
今後の開発
Mercari Dataflow Templateは今後も継続的に機能追加を行っていく予定です。
今のところ、以下のような機能の追加を検討しています。
- Workflow機能追加
- 読み書きの待ち合わせ(BigQueryでテーブル書き込み完了後にクエリ実行など)
- Streaming対応強化
- 各種DatabaseサービスのMicrobatch読み込み
- PubSubのAvro以外のフォーマット対応
- ML予測機能追加
- AutoML APIやAI Platformへの自動リクエスト&予測結果付与
- ONNXファイルロード&予測結果付与
- ローカル実行対応
- ローカルでDirect Runnerによる小規模データの手軽な処理
- Spanner Emulator対応
問題・要望などあれば気軽にIssueなど立てて頂ければ幸甚です(もちろんPRも大歓迎です!)
明日の Merpay Advent Calendar 2020 は同じSolutions Team の apstndbさんによる 「Cloud Spanner の実行計画の活用に関する取り組み」 です!




