※本記事は2022年5月13日に公開された記事の翻訳版です。
※この記事はSecurity Tech Blogシリーズ: Spring Cleaning for Securityの一環で書かれています。
こんにちは。Security EngineeringチームのDavidです。
この記事では、メルカリが独自に実施しているSOC(セキュリティオペレーションセンター)の取り組みを紹介します。少しでも読者の脅威検出の取り組みをスタートするきっかけになれたらと思っています。
はじめに
一般的に、サイバーセキュリティは、防止(Prevention)、検出(Detection)、対応(Response)の3つの主要原則に分類されます。最近のブログ投稿やオンライン登壇では、SecurityチームとMicroservice Platformチームが主にセキュリティの防止の側面 [1] について触れてきました。この記事では、焦点を検出に移し、対応についても少し掘り下げていきます。
防止は、全体的なリスクを軽減し、メルカリをサイバー脅威から守るうえで重要な役割を果たします。しかし、いかなる防止手法も完璧ではありません。攻撃者は容赦なくさまざまな攻撃手法を試し続けるため、最終的には最強の防御さえも打ち破られることも想定しなければなりません。その場合、攻撃者をできるだけ早く検出することが不可欠です。強力な検出機能は、攻撃者が組織内に足がかりを築く前に、そして重要なデータやシステムに到達する前に、根本的な問題を把握し対応して、攻撃者を根絶する手助けにもなります。
NIDS (Network Intrusion Detection System)とエンドポイントデバイス上の単純なマルウェア対策ソフトウェアで充分だったのは、とうの昔の話です。今日、データはこれまで以上に分散化され、インフラはクラウド上の一時的な基盤が用いられ、従業員のワークスペース・アクセス元端末の種類は増加し、組織基盤を構成するクラウドサービスやAPIの数は指数関数的に増加しています。メルカリもこの動向の例外ではなく、何をどのように監視するかを探るということでさえ難しい課題になっています。
「分散型」セキュリティオペレーションセンター(SOC)
従来、この課題に取り組むための一般的な対策の1つはSOCを確立することでした。ただし、業界は継続的に変化しており、DevOpsとSREによるIT業界の変革に類似した変化が起こっています。メルカリSOCのティアレベルにはアナリストがありません。代わりに、セキュリティ監視機能を設計および管理するDetection Engineerがいます。Detection Engineeringは、脅威インテリジェンス(Threat Intelligence)と脅威ハンティング(Threat Hunting)の成果、効率化、スキルの向上に重点を置いています。この種のSOCモデルの例は、Googleのホワイトペーパー「Autonomic Security Operations」ですでに詳しく説明されています。
メルカリは、強力なエンジニアリング文化および「Go Bold」という文化を持っています。上記に加え、下記の目標も念頭に置いて、先進的なSOCを構築するために、このようなビジョンを設定しています。
- クラウドワークロードとクラウドネイティブインフラを使用した監視
- データ挿入からパース、正規化まで、大規模に実行されるデータパイプラインの制御
- ベンダーロックインのない、柔軟性のあるカスタムツール
- 保持制限がなく、セキュリティテレメトリ、分析、調査に使用できるデータレイクの構築
- 人々の創造性をエンパワーする。高度な脅威と戦いながらも、アラートを手動でトリアージする必要性を抑える
Detection Engineering
Detection Engineeringの中心となる考え方は、ソフトウェアの開発と同じ方法で脅威の検出に臨むことです。これは、プログラミング言語で検出ルールとプロセスを書くことで、テスト駆動の開発を採用し、バージョン管理システムを活用し、変更をピアレビューし、CI/CDワークフローを使用してデプロイを自動化することを意味します。
Detection Engineerは、ソフトウェアエンジニアであるだけではなく、攻撃手法、脅威モデリング、脅威インテリジェンス、脅威ハンティング、インシデントレスポンスの専門家でもあります。彼らは、組織に固有のリスクに関連した検出機能の有効性と適用範囲を測定し、絶えず変化する脅威の状況に基づいてこれらの機能を継続的に再評価および改善します。Detection Engineerは、次のような質問に答えられる必要があります。
- What are the threats that we need to 検出すべき脅威は何か
- 現在の機能とテクノロジーで何を検出できるか
- 本当にこれらの脅威を検出することができるのか
- 脅威をどのくらいうまく検出できているか
- 検出された脅威を適切に修復し、適切な対応を行っているか
メルカリでは、Detection EngineerはSOCの主要メンバーであり、「検出」と「対応」の役割を担っています。技術的なインシデントレスポンスが必要となった際は CSIRT(Computer Security Incident Response Team)と連携し、対応しています。
監視プラットフォームの構築:SOAR
SOCの中心には、かならず監視プラットフォームがあります。メルカリの監視プラットフォームに備えようとしている機能は、Gartner社による造語であるSOAR(Security Orchestration, Automation and Response)の定義と一致しています。Gartner社によるSOARの説明は次のとおりです。
「組織がさまざまなソースから情報を受け取り、プロセスと手順に合わせてワークフローを適用できるようにするテクノロジーである。他のテクノロジーとの統合や自動化を通してセキュリティオーケストレーションを行い、求めている成果とより優れた可視性を実現できます。マシンが人間のアナリストをサポートし、人間とプロセスの効率と整合性を向上させることにより、脅威の検出やレスポンスなどのセキュリティ運用の活動を強化するのです。」
市場に存在するベンダーの中には、ポイントアンドクリックのフロントエンドを備えたSIEM(Security Information and Event Management)およびSOARソリューションを提供しているものもありますが、多くの場合、利用可能な統合に制限があったり独自のクエリ言語を使用する必要があったりして、ライセンス料も高くなります。したがって、これらのツールでは、上記のSOCで述べたような目標は達成できません。
では、メルカリではどのように独自の社内SOARプラットフォームを設計したのでしょうか。次のセクションでは、これについていくつかの例を挙げて詳しく説明します。この情報が参考になる自分の組織で同様のソリューションを実装するためのアイデアになれたら嬉しく思います。
アーキテクチャ
メルカリのソリューションの主な考え方としては、メルカリのソフトウェアエンジニアが使用するものと同じまたはそれに似ている技術スタックを使用してソリューションを構築することです。こうすれば、チーム間で知識を簡単に共有し、組織全体で使用されているテクノロジーを最新の状態に保てるからです。また、下記のことが実現できます(ただし、これらに限定されません)。
- マイクロサービス群とサーバーレスの概念を使用した構築
- Goプログラミング言語とそのツールセットを中心に開発を一元化
- DevOps、SRE、IaC、CI/CDのベストプラクティスを使用した構築とデプロイ
- オープンソースソフトウェアプロジェクトとCloud Native Computing Foundation(CNCF)プロジェクトの使用
- Google Cloud Platformでのワークロードの実行
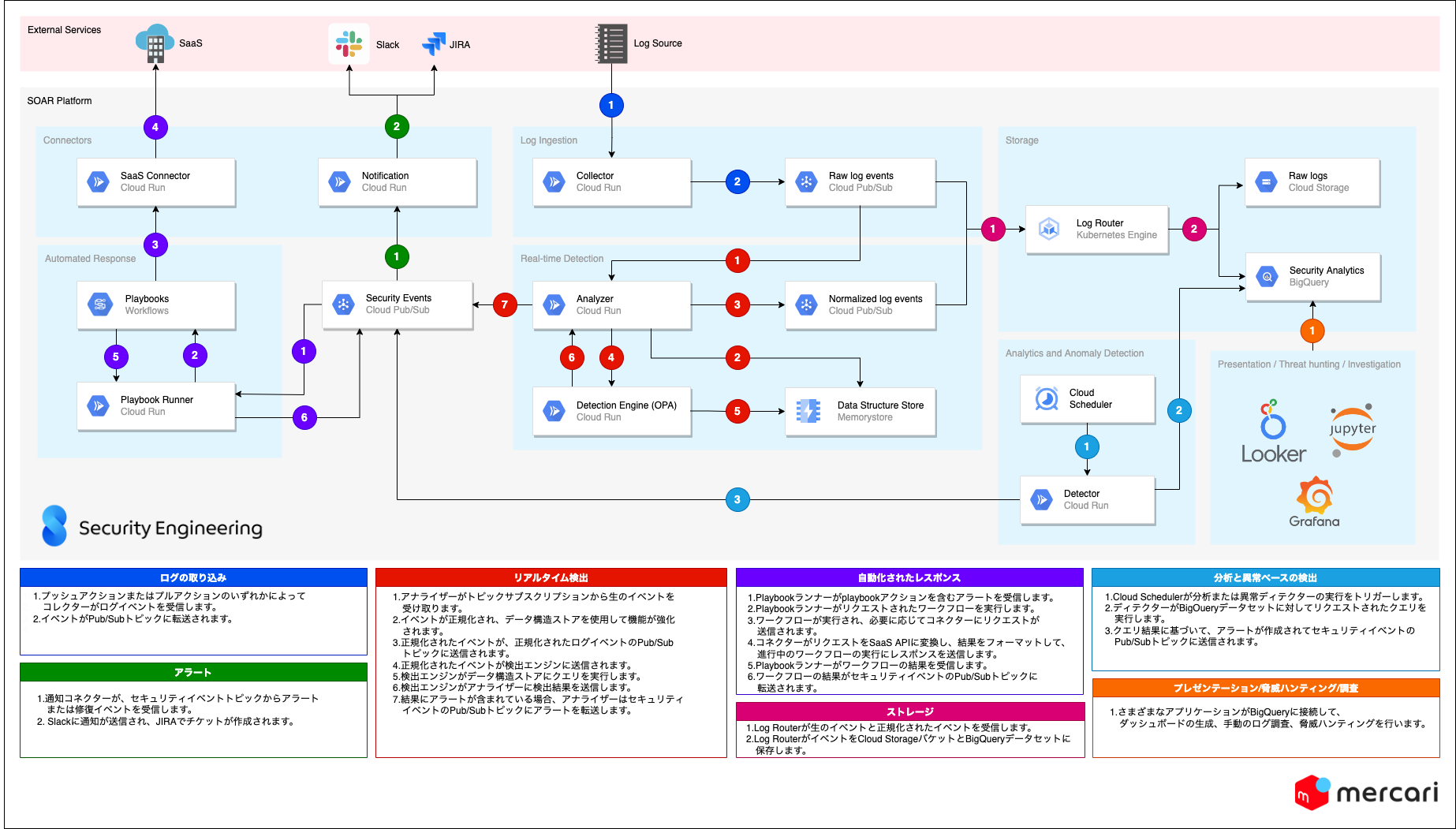
プラットフォームは、Google Cloudにデプロイしたコンポーネントを組み合わせて構築しています。各コンポーネントには特定の役割があり、マイクロサービス同様、APIとイベントブローカーを使用して機能し、相互作用します。
主なコンポーネントは次のとおりです。
-
コレクター
コレクターはプッシュまたはプルメカニズムを使用するサーバーレスエージェントです。コレクターの役割は、さまざまなソースから生のログイベントまたは脆弱性/脅威インテリジェンスデータをリアルタイムで取り込む(リアルタイムが不可能な場合は短い間隔でバッチ処理する)ことです 。これらはインジェストパイプラインの最初のステップであり、コレクターはログまたはフィードの種類ごとにデプロイされます。Splunk HECをエミュレートするコレクターのように多くのログソースを集約できるコレクターもありますが、必要に応じて簡単に分割することもできます。イベントが突然急増した場合の安定性を向上するためにも、デバッグ目的でも、コレクターは特定のソースに限定する方が扱いやすいです。コレクターは、イベントをPub/Subトピックに転送します。Cloud RunおよびCloud Functionで実行されます。 -
アナライザー:
アナライザーはログの種類ごとに存在して、コレクターがストリーミングログトピックにパブリッシュしたイベントを使用します。その役割は、イベントを解析し、正規化し、強化することです。アナライザーは多くのモジュールで構成され、各デプロイメントは、取り込まれたログタイプに応じてモジュールを統合しています。正規化後、イベントを正規化されたイベントのトピックとリアルタイム検出サービスの2つの異なる宛先にストリーミングします。検出サービスの結果に基づいて、脅威が検出された場合、アラートイベントが作成され、セキュリティイベントトピックに転送されます。Cloud Runで実行しています。 -
コネクター:
コネクターは、主に外部サービスのインターフェイスとなり、アクションを実行したり、情報を収集したりします。例えば、イベントをチャネルに送信したりコマンドを受信したりするSlackコネクター、インシデントケースを作成したりまたは単に修復ワークフローでデータを結合したりするJIRAコネクターがあります。Cloud RunおよびCloud Functionで実行されます。 -
リアルタイム検出エンジン
検出ルールは、リアルタイムでログストリームに適用されます。すべてのルールは、Regoと呼ばれる一般的なプログラミング形式で記述されています。検出エンジンは、Open Policy Agent(OPA)サーバーを使用しています。OPAについては、この記事で後に詳しく説明します。Cloud Runで実行しています。 -
ログルーター
ログルーターは、生のログトピックと正規化されたログトピックの両方をサブスクライブし、Google Cloud Storage、BigQuery、その他のPub/Subトピックなどのさまざまなストレージバックエンドに転送します。Kubernetes(GKE)にデプロイされたfluentd/fluentbitコンテナを使用しています。 -
分析と異常ベースのディテクター
We supplement real-time detection with データの大規模な分析、外れ値の検索、特定の動作の検出など、ログストリームでは簡単に実行できないタイプの検出を用いて、リアルタイム検出を補完します。ディテクターは、セキュリティイベントおよびログイベントのデータレイク上で定期的に実行されます。まだ初期段階ですが、ロードマップにいくつかの大きなアイデアがあります。Cloud Runで実行しています。 -
Playbookとワークフローの自動化
We codify SOC processes and response to ンスをplaybookにコード化します。サービスは、アナライザーによって発行されたアラートを監視し、アラートに紐付いた自動化されたplaybookがある場合には実行します。PlaybookはSlackまたはコマンドラインからインタラクティブに呼び出すこともできます。詳しくは本ブログの後半を参照してください。Cloud RunおよびGoogle Cloudで実行されます。 -
データ構造ストア
データ構造ストアコンポーネントには主に2つの用途があり、一部のルールの状態を保存することと、IPアドレスのリスト、脅威インジケーター、ユーザー分析などのさまざまなデータをキャッシュすることです。Redisで実行されます。 -
データレイク
SOARプラットフォームによって取り込まれ、作成されたすべてのデータは、Google BigQueryデータセットに書き込まれます。分析、調査、その他多くの検出ルールに使用できるデータを無制限に保存できます。メルカリでは、BigQueryとJupyter Notebookを使用して調査や脅威のハンティングを行っており、これについては、Simonによるブログ投稿で詳しく情報共有します。Googleは最近、BigQueryがJSON形式の半構造化データとインデックスによる全文検索をサポートするようになったこと、また、ついにBigQueryで機械学習モデルを実行できるようになったことを発表しました。 -
プレゼンテーション
プレゼンテーションコンポーネントは、Securityチームに情報を提示するためのものです。この領域はまだ調査中ですが、Grafana、Looker、カスタムWebフロントエンドの組み合わせを検討しています。現在ケース管理にはJIRAとSlack通知を使用しています。
コード編成に関しては、いくつかのGitリポジトリに分割しました。
- インフラ:Terraformマニフェストでリソース、環境、アクセスを管理しています。
- すべてのSOARコンポーネント(コレクター、アナライザー、コネクター、ワークフロー)を含んだモノレポで管理しています。
- 検出ルール:すべてのDetection-as-Code(コードを用いた検出)ルールの信頼できる情報源です。
- スキーマ:複数のスキーマ(SOARコンポーネント、ログ正規化スキーマ、アラートスキーマ、修復イベントスキーマ)を保持します。スキーマはYAMLファイルで管理しています。これらのファイルは、protobufファイル、Goパッケージ、Pythonライブラリ、BigQueryスキーマの自動生成に使用されます。
- CI/CDパイプライン:継続的インテグレーションと継続的デプロイのための専用リポジトリがあり、セキュリティ上の理由から、上記のコードベースから分離しています。これを行う理由の詳細については、モノレポの外部で管理されるCI/CDおよびCIスクリプトに関するブログを参照してください。
次に、検出ルールの記述についてさらに説明し、いくつかの例を示します。
脅威検出ルール
検出はどこから手をつけたらいいのでしょうか。また、適切な検出ルールはどのように構築できるでしょうか。
まず、優れたデータがなければ、できることはあまりありません。もちろんセキュリティ監視を行うためにデータを収集して取り込む必要がありますが、優れた分析と検出を行うためにはデータの品質がとても重要です。データに関しては、次の3つの点を考慮する必要があります。
-
データの完全性
完全性とは、ログの可用性の程度と、記録されるイベントの幅と深さのことです。また、ログの保持期間も含まれます。- ログが存在し、取り込むことができる
- 監査する必要のあるサービスまたはシステムのすべてのアクションと要素が記録される
- アクセスレベル(ローカルファイル、データベース、クローズドシステム)
-
データの即時性
これは、いつ情報がアクセス可能、利用可能となるかです。適時性は、イベントが発生してから使用できるようになるまでの時間として表すことができます。- イベントが発生した時点でストリーミングされる
- 特定時点のすべてのイベントが提供される
- すべてのイベントにはタイムスタンプが付けられ、イベントが発生した正しい時刻が表される
-
データの一貫性
同じソースまたは他のソースからの同じタイプの情報を含む他のイベントと比較した場合に、イベント間に不整合がないことを意味します。また、同じアクティビティに対して同じイベントデータを生成する必要があります。- 同じサービスからのログソース全体のフィールドに対して命名規則が標準化されている。同じユーザーデータを表すフィールドが異なる名前を持たないようにする(username、userId、account_name)
- イベントデータはすべてのメッセージにわたって一意の構造またはスキーマに従う
- イベントが重複しない
- 各イベントデータは完全な単一のメッセージとして記録される
第二に、敵がどんなテクニックや戦術を使用したとしても 、それによって必ず環境に変化がもたらされます。Webサーバーのログエントリ、ファイルの書き込み、受信トレイに入ったフィッシングメール、ネットワークソケットの解放、新しいアカウントの作成などが変化の例です。絶えず変化しているクラウド環境では、脅威と見なされるものと通常のアクティビティと見なされるものを識別するのが難しい場合があります。
そのため、検出エンジニアは脅威モデリングと脅威インテリジェンスを組み合わせてルールを構築する必要があります。それらを構築するときは常に、既知と未知のものがあることを心に留めておく必要があります。つまり、アクションには、悪いとわかっているものと悪いとわかっていないものがあるということです。両タイプのアクションを環境の変化または脅威の一部として分類でき、提供するコンテキストのレベル(多~少)もさまざまです。
既知の不正イベント:
- 環境の変化:理解可能で、ルールとして簡単に説明できるイベントです。決定論的で多くのコンテキストを提供します。
ルールは「観察された変化AがBに等しい場合、Wにアラートを発行する」として定式化できます。 - 脅威インジケーター:悪いこととわかっているインジケーターに関連するイベントです。例として、脅威アクターに紐付くIPアドレスと既知のマルウェアのハッシュ値があります。それ自体では、コンテキストが少ない、もしくはまったくコンテキストがありません。
ルールは「インジケーターAが観察された場合、Xにアラートを発行する」として定式化できます。
未知の不正イベント:
- 環境の異常:少数のプロパティを使用して集約することで「通常」のイベントを定義して分類し、その定義からの逸脱を測定します。提供するコンテキストは少ないです。
ルールは「観察された変化AがBに等しく、Cがピアの平均より大きい場合、Yにアラートを発行する」として定式化できます。 - 脅威の動作:上記と同様ですが、ここでは、期間(分、日、週)および空間(デバイスやユーザーなどのさまざまなエンティティ)にわたって、より多くの機能とデータポイントを処理します。アルゴリズムのみが内容を確認でき、人間は確認できない可能性があります。多くのコンテキストを提供します。
ルールは「時間Dでエンティティ(A、B)かつシステムCである場合、Zにアラートを発行する」として定式化できます。このレベルでは、適切なルールを作成するのは難しく、かなりの創造性が必要です。多くの場合、数学モデルでルールを自動的に作成することができます。
コンテキストの少ないイベントであれば多くの誤検知を発生させてしまいます。しかし、高コンテキストなイベントを充実しアラートのSeverityスコアを調整することで誤検知を防ぐことができます。
シナリオを使用して全体像を理解しましょう。
攻撃者が、従業員のPCに侵入してSSHの秘密鍵とknown_hostsファイルを盗みます。次に、ssh鍵を使用して既知のホストにリストされているすべてのホストに接続し、それらすべてにクリプトマイナーをインストールして起動します。
- 環境の変化:SSH接続でログイン成功、ファイアウォールにネットワーク接続を記録、ディスクにファイルの書き込み。
- 脅威インジケーター:SSHセッションのソースIPが既知のMoneroクリプトマイナーキャンペーンにリンクされており、ファイルのハッシュ値がクリプトマイナーであることがわかっている。
- 環境の異常:従業員が勤務時間外にSSHでサーバーに接続することはめったにない。サーバーのCPU使用率が突然増加。
- 脅威の動作:ユーザーが短期間に多くのサーバーにSSHで接続し、ファイルを書き込み、ファイルを実行してからすぐにログアウトして、すべてのサーバーが一意の宛先への出力トラフィックの送信を開始した場合、アラートを送信する。
再び同じシナリオを使用し、regoOpen Policy Agent用に構築されたDatalogに基づく宣言論理型プログラミング言語)を用いて脅威検出のルールをコード化する方法を示します。Open Policy Agent(OPA)は、CNCFによってホストされるオープンソースの汎用ポリシーエンジンです。クラスターにポリシーを適用する方法として、通常OPAを Kubernetes上でGatekeeperとともに使用します。regoルールの記述の仕方はこのブログでは触れませんが、regoの知識がなくても、regoがいかに読みやすくシンプルであるかは確実に理解することができると思います。また、データ構造ストアコンポーネントを使用してデータストリームのOPAを拡張するカスタム関数を開発したことにご注意ください。混乱を避けるために、ハイライトしておきます。
scenario_rules.rego
package scenario
alert[msg] {
title := "High ssh login rate for a user"
duration := "5m" # 5 minutes
threshold := 10 # 10 logins
endswith(input.logName, "logs/syslog")
contains(input.jsonPayload.message, "pam_unix(sshd:session): session opened")
user := regex.find_all_string_submatch_n("for user ([^ ]+)", input.jsonPayload.message, 1)[0][1]
hostID := input.resource.labels.instance_id
# rateLimit() is a custom function
sshLoginCount := rateLimit(sprintf("%s-sshLoginCount", [user]), duration)
sshLoginCount > threshold
msg := {
"title": title,
"details": sprintf("%s connected by SSH multiple times (%d) in a short period of time (%s)", [user, sshLoginCount, duration]),
"riskScore": 10,
"entities": [user, hostID],
}
}
alert[msg] {
title := "SSH Login from known threat actor"
hostID := input.resource.labels.instance_id
endswith(input.logName, "logs/syslog")
remoteIP := regex.find_all_string_submatch_n("sshd.*Accepted publickey for [^ ]+ from ([^ ]+)", input.jsonPayload.message, 1)[0][1]
isThreatActor(remoteIP) # Returns true if found, custom function
msg := {
"title": title,
"details": sprintf("Successful ssh login to %s from threat actor at IP address %s", [hostID, remoteIP]),
"riskScore": 20,
"entities": [hostID],
}
}
alert[msg] {
title := "Cryptojacking warning"
cryptominerSHA := {
"c47606c32ad87da2dfc480e6c855da4196ceefb60a27fc69a9da9233d38d697a",
"066f103e7433559e3a128dcee6d78fa49c90edbb63f60d3b0925c0bbfa3a0f13",
"ec9e6b7d3f0df38daf439fa8181c0dcca03a8036104517641c480ba500bcedf4",
}
cryptominerPath := input.osquery.file_event.target_path
hostID := input.osquery.host_identifier
input.osquery.file_event.sha256 == cryptominerSHA[_]
msg := {
"title": title,
"details": sprintf("'%s' was detected to be a cryptominer on host %s", [cryptominerPath, hostID]),
"riskScore": 30,
"entities": [hostID],
}
}記事の前半で説明したように、ルールの正しさを検証するためにテスト駆動開発を採用しています。OPAはテストフレームワークを備えているので、テストは容易に作成できます。それでは、ルールの1つに対してテストを書いてみましょう。
scenario_rules_test.rego
package scenario
test_file_is_a_cryptominer {
input := cryptominerEvent
msg := alert with input as input
count(msg) == 1 # We should get one alert message
}
test_file_is_not_a_cryptominer {
input := normalEvent
msg := alert with input as normalEvent
count(msg) == 0 # We shouldn't get an alert message
}
cryptominerEvent = {"osquery": {
"host_identifier": "hostA",
"file_event": {
"target_path": "/tmp/monero",
"sha256": "066f103e7433559e3a128dcee6d78fa49c90edbb63f60d3b0925c0bbfa3a0f13",
},
}}
normalEvent = {"osquery": {
"host_identifier": "hostA",
"file_event": {
"target_path": "/tmp/safefile",
"sha256": "dafeddc7dec7f4642a7c6ba93329ca88ac4759a61c1a4f9b6ac087eb9ae45899",
},
}}OPAコマンドラインで、ルールテストに合格したことと、テストカバレッジを確認できます。
$ opa test -v scenario_rules.rego scenario_rules_test.rego
data.scenario.test_file_is_a_cryptominer: PASS (483.332µs)
data.scenario.test_file_is_not_a_cryptominer: PASS (253.579µs)
--------------------------------------------------------------------------------
PASS: 2/2
$ opa test -c scenario_rules.rego scenario_rules_test.rego | jq .coverage
52.95次に、Gitワークフローを使用して、ルールのGitリポジトリに変更をコミットし、プルリクエストを送信します。CIパイプラインでテストが実行され、合格したテストはテスト環境に自動的にデプロイされます。これは、ストリーミングされたデータで結果を確認する場合に便利です。ルールが承認されると、エンジニアは変更をメインブランチにマージできるようになり、CDパイプラインがルールを本番OPAサーバーにデプロイします。
脅威の動作ルールの場合、ルールは分析と異常ベースのディテクターとしてデプロイされます。最も基本的な形では、これはBigQueryで定期的に実行されるようにスケジュールされたSQLクエリになります。
自動化されたレスポンス
検出は戦いの半分に過ぎません。何かを検出したら、それに対処する必要があります。これは、他の関連するアクティビティの調査、お客さまへの連絡、ネットワークトラフィックのブロックなどのさまざまな形をとることができます。すべてのタイプの検出の修復とレスポンスを完全に自動化することはできませんが、Detection EngineerはSOARシステムを使用してplaybookを作成し、セキュリティと運用効率を向上させることができます。
修復プロセスをSOARプラットフォームでの検出にリンクさせる方法は色々とありますが、先ほどのシナリオを再び使用して1つ定義してみましょう。まず、msgの下で、作成したルールの1つに新しいplaybookフィールドを追加します。
scenario_rules.rego
alert[msg] {
title := "High ssh login rate for a user"
duration := "5m" # 5 minutes
threshold := 10 # 10 logins
endswith(input.logName, "logs/syslog")
contains(input.jsonPayload.message, "pam_unix(sshd:session): session opened")
user := regex.find_all_string_submatch_n("for user ([^ ]+)", input.jsonPayload.message, 1)[0][1]
hostID := input.resource.labels.instance_id
# rateLimit() is a custom function
sshLoginCount := rateLimit(sprintf("%s-sshLoginCount", [user]), duration)
sshLoginCount > threshold
msg := {
"title": title,
"details": sprintf("%s connected by SSH multiple times (%d) in a short period of time (%s)", [user, sshLoginCount, duration]),
"riskScore": 10,
"entities": [user, hostID],
"playbook": {
"name": "scenario-demo",
"args": {"userID": user, "hostID": hostID},
},
}
}Googleワークフローを使用してplaybookをコード化し、コネクターで強化します。次の架空のレスポンスを使用してplaybookの実用的な例を示します。
「ユーザーが短期間に複数のサーバーにログインした場合、サーバーとユーザーの現在のリスクスコアを確認する。推奨されるリスクスコアのしきい値を超えている場合、各ホストのauthorized_keysからユーザーのsshキーを削除し、進行中のsshセッションをすべて終了し、実行されたアクションについてユーザーに通知する。」
scenario_demo.yaml
main:
params: [input]
steps:
- init:
assign:
- project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- secret_id: "slack-token"
- version: "1"
- expression:
assign:
- slack_token: ${googleapis.secretmanager.v1.projects.secrets.versions.accessString(secret_id, version, project_id)}
- getUserRiskScore:
call: http.post
args:
url: https://risk-score-abcd12345-an.a.run.app/user
auth:
type: OIDC
body:
parameter: ${input.userID}
result: userRiskScore
- getHostRiskScore:
call: http.post
args:
url: https://risk-score-abcd12345-an.a.run.app/host
auth:
type: OIDC
body:
parameter: ${input.hostID}
result: hostRiskScore
- checkRiskScoreThreshold:
switch:
- condition: ${hostRiskScore.body.value > 30 AND userRiskScore.body.value > 20 }
next: disableUserSshPublicKey
next: endPlaybookExecution
- endPlaybookExecution:
return: Risk score low - Exiting.
- disableUserSshPublicKey:
call: http.post
args:
url: https://oslogin-connector-abcd12345-an.a.run.app/user/disable
auth:
type: OIDC
body:
parameter: ${input.userID}
result: disableUserResult
- validateDisableUserResult:
switch:
- condition: ${disableUserResult.body.outcome == "success" }
next: slackNotify
- slackNotify:
call: http.post
args:
url: https://slack.com/api/chat.postMessage
headers:
Content-Type: "application/json"
Authorization: ${"Bearer " + slack_token }
body:
channel: C046N1DTZGB
attachments:
- blocks:
- type: section
text:
type: mrkdwn
text: ${"We have detected suspicious SSH activity from your account " + input.userID }
- type: section
fields:
- type: mrkdwn
text: SSH login access to servers was disabled. Contact the security team for details.ここでは便宜上、gcloud CLIを使用してローカルマシンから直接ワークフローをデプロイします。
$ gcloud workflows deploy scenario-demo
--source=scenario_demo.yaml
--service-account=workflows-sa@security-project.iam.gserviceaccount.com
WARNING: The default location(us-central1) was used since the location flag was not specified.
Waiting for operation [operation-1652438877333-5dee2684be826-a327dc7a-e07d750b] to complete...done.
createTime: '2022-05-13T09:24:13.204483835Z'
name: projects/security-project/locations/us-central1/workflows/scenario-demo
revisionCreateTime: '2022-05-13T10:47:57.443412797Z'
revisionId: 000009-0dc
[...]
state: ACTIVE
updateTime: '2022-05-13T10:47:58.402442707Z'これでPlaybookが利用可能になり、次回その特定のルールに対してアラートが発行されたときに実行されます。アラートはセキュリティイベントトピックにパブリッシュされ、playbookサービスは「playbook」フィールドを探し、提供された引数を使用して指定されたワークフローを呼び出して実行します。
次に、playbookをテストするために架空の数値を与えます。ユーザーのBobは、深夜に突然sshを使用して5台のサーバーに接続し、各サーバーにクリプトマイナーをダウンロードしてから切断します。サーバーごとに多数のアラートがトリガーされ(サーバー上にクリプトマイニングツールのハッシュ値が見つかったなど)、サーバーのリスクスコアが60に上昇すると同時に、 Bobによる異常なアクティビティによって彼のリスクスコアが50に上昇します。
ここでも便宜上、データ構造ストアにスコアを入力し、ローカルマシンから必要な引数を使用してワークフローを実行します。
$ gcloud workflows run scenario-demo --data='{"userID":"bob@corp","hostID":"d1277634511"}'
WARNING: The default location(us-central1) was used since the location flag was not specified.
Waiting for execution [d106b6c0-1105-4495-82ca-d7083f00fd12] to complete...done.
argument: '{"hostID":"d1277634511","userID":"bob@corp"}'
endTime: '2022-05-13T10:52:37.575712559Z'
name: projects/1234567890/locations/us-central1/workflows/scenario-demo/executions/d106b6c0-1105-4495-82ca-d7083f00fd12
result: 'null'
startTime: '2022-05-13T10:52:36.023992096Z'
state: SUCCEEDED
workflowRevisionId: 000009-0dc

ワークフローには既成の監査ログが含まれているため、誰によって、いつ、なぜplaybookが実行されたかを常に知ることができます。
最後に
脅威の検出はメルカリでのセキュリティプログラムの基本的な部分です。Detection-as-Code(コードを用いた検出)とSOARを使用したアプローチにより、検出ルールの構築とデプロイが迅速になり、検出するまでの平均時間とインシデントにレスポンスするまでの平均時間をさらに短縮することができました。
次の記事では、検出範囲が充分であることを確認する方法と、フレームワークと方法論を使用して検出品質を測定する方法について詳しく説明します。
Securityチームでは、チームの一員となる、この分野が得意なセキュリティエンジニアを探しています。私たちと一緒にSOARプラットフォームを改善することに興味がある方はこちらの求人情報をご覧ください。
参考文献
[1]関連ブログとトークイベント
https://engineering.mercari.com/en/blog/entry/20220121-securing-terraform-monorepo-ci/
https://engineering.mercari.com/en/blog/entry/20220203-defense-against-novel-threats-redesigning-ci-at-mercari/
https://speakerdeck.com/rung/cd-pipeline
https://speakerdeck.com/tcnksm/how-we-harden-platform-security-at-mercari




