Greetings, I’m Abhishek Munagekar from the Search Infrastructure Team at Mercari. Our team manages several Elasticsearch clusters deployed on Kubernetes, forming a crucial part of our search infrastructure. We rely on the Elastic Cloud on Kubernetes (ECK) Operator to orchestrate these clusters, all housed within a dedicated namespace maintained by our team.
To leverage the advancements in recently released ECK operator versions, we embarked on an upgrade project. Operator upgrades are inherently complex and risky, often involving significant changes that can affect system stability.
In this article, I’ll delve into the challenges we encountered and the strategies we employed to manage operator upgrades for stateful workloads like Elasticsearch. Additionally, I’ll detail how we modified the ECK operator to facilitate a more resilient side-by-side upgrade process.
Minimizing Risk in a Critical Infrastructure
At Mercari, our Elasticsearch infrastructure is integral to multiple business units, notably powering the marketplace search functionality. Any disruption or downtime to this infrastructure carries the potential for significant financial repercussions. Therefore, our primary objective during ECK operator upgrades is to mitigate risk to the absolute minimum. This necessitates a cautious and strategic approach, favoring gradual rollouts over abrupt big-bang deployments, employing side-by-side upgrades instead of in-place replacements, and ensuring robust disaster recovery plans.
We utilize a suite of safety nets and backup mechanisms, including Elasticsearch snapshots, real-time write request backups, standby cluster preparations, and rigorous testing across multiple environments. While the details of these mechanisms are extensive, they fall beyond the scope of this particular article.
In-place Upgrade Mechanism used by the Native ECK Operator
Typically, Kubernetes operators, including the native ECK operator, perform in-place upgrades, where an existing component is directly replaced with a newer version. In contrast, a side-by-side upgrade involves running two versions of the same component concurrently. Here’s a comparative overview:
| Feature | In-place Upgrade | Side-by-side Upgrade |
|---|---|---|
| Downtime | Possible | Minimized |
| Rollback | More Difficult | Feasible |
| Resource Usage | Lower | Higher (Double) |
| Complexity | Lower | Higher |
| Examples | OS upgrades | Database Upgrades |
In-place upgrades carry inherent risks, particularly with stateful workloads like Elasticsearch. If issues arise, rollback is complex and time-consuming, leading to prolonged recovery periods. This is in contrast to stateless workloads, where recovery is generally faster and less risky.
Limiting Standard ECK Upgrades
A standard ECK operator upgrade triggers a rolling restart of Elasticsearch nodes across all clusters simultaneously. This all-at-once approach is unacceptable for our high-stakes production environment, where a more gradual rollout is essential. The ECK operator offers an annotation, eck.k8s.elastic.co/managed=false, to temporarily unmanage Elasticsearch clusters, allowing for one-by-one upgrades.
However, this solution conflicts with our infrastructure’s CPU-based autoscaling mechanism. Our system monitors data nodeset CPU usage and scales Elasticsearch by modifying the manifest, with the ECK operator provisioning the necessary nodes. Disabling the operator’s management effectively halts our autoscaling (detailed in this blog article).
One workaround would be to manually scale workloads to maximum capacity, apply the unmanaged annotation, and then proceed with a serial upgrade process, by removing the unmanaged annotation one at a time.
Following is a flowchart for the proposed plan.

But this was rejected for the following reasons:
- Costly: Disables crucial autoscaling features.
- Inflexible: Prevents scaling during unexpected traffic surges.
- Restrictive: Blocks any configuration changes to Elasticsearch during the upgrade.
Our Solution: A Custom Side-by-Side Upgrade Strategy
To circumvent these limitations, we chose to implement a custom side-by-side upgrade approach that mimics the granular control of eck.k8s.elastic.co/managed=false but is tied to the operator’s version.
Introducing Operator Version Labeling
We introduced a new label:
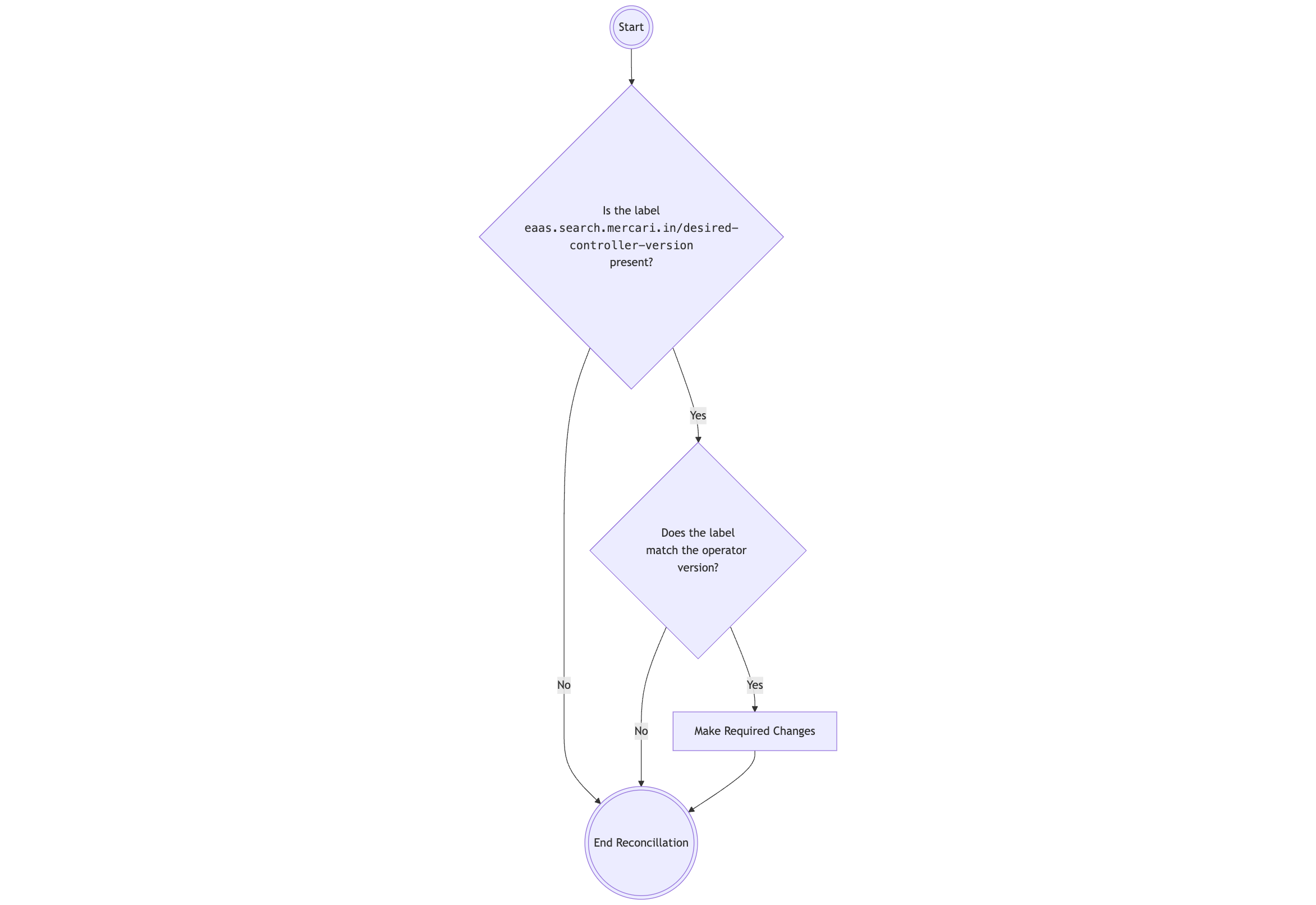
eaas.search.mercari.in/desired-controller-version = x.y.zThis label is applied to all Elasticsearch clusters, initially set to the current (older) operator version. We then modified the ECK operator’s logic(referencing this GitHub link) to recognize this label and control cluster management accordingly.
Modifying the Controller for Dual Version Support
Both the existing (older) and the new ECK operator versions were modified to support this label. Functionally, we adapted the IsUnmanaged function and the main controller loop to:
- Check for the
eaas.search.mercari.in/desired-controller-versionlabel. - Skip reconciliation if the label is missing or if the label’s version does not match the operator’s build version.
Here’s the relevant code snippet:
const desiredECKControllerVersionLabel = "eaas.search.mercari.in/desired-controller-version"
func IsUnmanaged(ctx context.Context, object metav1.Object) bool {
managed, exists := object.GetAnnotations()[ManagedAnnotation]
if exists && managed == "false" {
return true
}
desiredVersion, exists := object.GetLabels()[desiredECKControllerVersionLabel]
if !exists {
ulog.FromContext(ctx).Info(fmt.Sprintf("Object doesn't have %s label. Skipping reconciliation", desiredECKControllerVersionLabel), "namespace", object.GetNamespace(), "name", object.GetName())
return true
}
if desiredVersion != about.GetBuildInfo().Version {
ulog.FromContext(ctx).Info(
fmt.Sprintf("Object is not the target of this controller by %s label. Skipping reconciliation", desiredECKControllerVersionLabel),
"desired_version", desiredVersion,
"operator_version", about.GetBuildInfo().Version,
"namespace", object.GetNamespace(),
"name", object.GetName(),
)
return true
}
paused, exists := object.GetAnnotations()[LegacyPauseAnnoation]
if exists {
ulog.FromContext(ctx).Info(fmt.Sprintf("%s is deprecated, please use %s", LegacyPauseAnnoation, ManagedAnnotation), "namespace", object.GetNamespace(), "name", object.GetName())
}
return exists && paused == "true"
}
Handling Custom Resource Definitions (CRDs)
The ECK operator defines a custom resource of Kind: Elasticsearch. This is a cluster-scoped resource, not a namespaced resource, so we cannot define two distinct versions of the CRD concurrently within the same cluster.
In this scenario, we rely on the backward compatibility of the CRD definition. It’s crucial to note that while CRDs are expected to be backward compatible, they may not be forward compatible. Backward compatibility ensures that older operator versions can work with newer CRD definitions. However, forward compatibility, which would mean newer operators can seamlessly work with older CRD definitions, is not guaranteed.
This implies that the latest version of the CRD must be deployed to the cluster when running two different versions of the ECK operator side-by-side. Failure to do so could lead to issues where the newer operator version cannot interpret newer CRD fields or configurations, resulting in deployment or operational errors. Therefore, before initiating an upgrade, ensuring the newest CRD version is applied is a critical prerequisite.
Handling Validating Webhook
ECK also defines a validating webhook, which validates the Elasticsearch manifests before they are applied to the cluster. When running two versions of the ECK operator concurrently, it is crucial to ensure that each operator version only validates the Elasticsearch clusters for which its desired-controller-version matches.
The default webhook configuration, without any restrictions, would mean that an Elasticsearch manifest could be validated by both versions of the operator. This poses a significant risk because newer operator versions might introduce new features or modifications to the validation logic. These changes could render validation performed by an older operator version incompatible or incorrect for the expectations of the newer operator, or vice versa. This discrepancy could potentially lead to deployment failures, configuration errors, or unexpected behavior.
Instead of modifying the controller logic itself, a simple object selector was added to the webhook configuration.
objectSelector:
matchLabels:
eaas.search.mercari.in/controller-version: x.y.z
This objectSelector with matchLabels ensures that each ECK operator version only validates Elasticsearch manifests that have the corresponding desired-controller-version. By isolating the validation process based on the operator version, we prevent potential conflicts and ensure that manifests are only validated by the operator version that is expected to manage them.
Leader Election for High Availability in ECK Operator Upgrades
The ECK operator employs leader election to ensure high availability. Multiple instances of the operator can run concurrently, but only one acts as the active leader responsible for processing changes. This leader election mechanism relies on Kubernetes leases, specifically by acquiring a Kubernetes lease.
In a standard, in-place upgrade scenario, the ECK operator uses a constant Kubernetes lease named elastic-operator-leader. Regardless of the operator version, they all contend for this same lease. When an in-place upgrade occurs, the new operator version simply replaces the old and takes over this existing lease.
The following diagram illustrates the leader election process during a standard in-place upgrade:

However, the default lease strategy presents a challenge for our side-by-side upgrade approach. Since both the older and newer ECK operator versions would try to acquire the same elastic-operator-leader lease, it would result in contention and only one version of the operator could run at a given time. To facilitate our dual-version scenario, we needed a way to separate the leader election for each version.
To address this, we modified the ECK operator’s leader election logic to create distinct Kubernetes leases based on the operator’s version. This ensures that each operator version has its own separate leader election process, allowing them to run in high availability side-by-side without conflict.
We made changes to the LeaderElectionID in the ECK operator code. This ID now includes the operator’s version:
func GetLeaderElectionLeaseName() string {
buildInfo := about.GetBuildInfo()
k8sVersion := strings.ReplaceAll(buildInfo.Version, ".", "-")
leasePrefix := "elastic-operator-leader-v"
leaseName := fmt.Sprintf("%s%s", leasePrefix, k8sVersion)
return leaseName
}
LeaderElectionID: GetLeaderElectionLeaseName()
In essence, this change transforms the default elastic-operator-leader lease into version-specific leases, such as elastic-operator-leader-v2-16-1 for version 2.16.1. With these versioned leases, each ECK operator instance will only participate in leader election with instances of the same version. The following diagram shows the leader election process with our side-by-side upgrade:
Testing Our Approach Thoroughly
The Search Infrastructure Team at Mercari leverages three distinct environments to ensure the stability and safety of our infrastructure changes:
- Laboratory Environment: This environment serves as a dedicated playground, allowing the infrastructure team to rigorously test changes without impacting the development environment. It’s our sandbox for experimentation and initial validation.
- Development Environment: This environment mirrors the production setup to a significant degree and is primarily used for Quality Assurance (QA) testing and the development of new features. This is where we validate changes under conditions closely resembling those in production.
- Production Environment: This is the live environment serving real user traffic, demanding the highest level of stability and reliability.
Before any production deployment, changes are meticulously tested in both the laboratory and development environments. We conduct comprehensive testing to ensure both the older and newer versions of the ECK operator can coexist without conflicts. This includes verifying the labeling system, controller logic modifications, CRD handling, and validating webhook changes. We also perform thorough rollback tests to guarantee that we can quickly revert to the previous state if issues arise. This rigorous testing across multiple environments is crucial to minimizing risk in our high-stakes production environment.
Rollout to Production: A Phased and Monitored Process
Our production rollout follows a phased and closely monitored approach to minimize risk. This involves:
- Preparation: Verify CRDs and webhook configurations are compatible with the new operator version.
- Labeling: Tag all Elasticsearch clusters with
eaas.search.mercari.in/controller-versionset to the current operator version for tracking. - Dual Deployment: Deploy both old and new ECK operators concurrently.
- Gradual Rollout: Upgrade clusters incrementally by updating their labels to point to the new operator version (
eaas.search.mercari.in/controller-version=<new_version>) cluster-by-cluster. - Continuous Monitoring: Track key metrics like error rates, system stability, and resource usage during each upgrade.
- Validation & Rollback: After each cluster upgrade, validate success or rollback by reverting labels and configurations if needed.
- Completion: Upgrade remaining clusters, validate, and then remove the older operator version.
The following diagram illustrates the workflow that we follow.

Conclusion
In summary, upgrading critical systems like the ECK operator needs careful planning and testing. Mercari’s specific needs led us to create a unique side-by-side upgrade strategy. By carefully changing the operator and using a step-by-step release, we successfully reduced risks and kept our search system running smoothly.
It’s often hard to perfectly copy real-world workloads in testing environments. This can lead to bugs slipping through. This challenge highlights a limitation of the standard approach, as standard operator upgrades are usually tested in development before going to production all at once.
While Kubernetes applications use methods like gradual releases and canary deployments, operator upgrades often use an all-at-once method. We found this wasn’t ideal for our critical search infrastructure.
With our successful ECK operator upgrade using the side-by-side approach, we plan to use this strategy for other critical operator upgrades in our production system. We hope our approach helps other teams manage Kubernetes operators, especially those which handle stateful workloads.