
I’m Tianchen Wang (@Amadeus), a new graduate engineer of the Platform Enabler team at Mercari, Inc. In this blog, I will share our new progress with creating Mercari’s Next-gen incident handling buddy by utilizing the Large Language Model (LLM).
In today’s fast-paced technological landscape, maintaining a robust on-call operation is crucial to ensuring seamless service continuity. While incidents are inevitable, the ability to swiftly respond and resolve them is essential for assuring users a safe, stable, and reliable experience. This is a shared goal among all Site Reliability Engineers (SREs) and employees at Mercari.
This article introduces IBIS (Incident Buddy & Insight System), an on-call buddy developed by the Platform Enabler Team leveraging generative AI. IBIS is designed to assist Mercari engineers in rapidly resolving incidents, thus reducing the Mean Time to Recovery (MTTR), and reducing on-call handling costs for companies and engineers.
Challenges and Motivation
At Mercari, ensuring that users can safely and securely use our product is a paramount goal and vision shared by all employees. To this end, we have established an on-call team of multiple divisions working together. Each week, on-call members receive numerous alerts, a significant number of which escalate into incidents that impact users. These incidents result in poor user experiences and an increase in Mean Time to Recovery (MTTR), which negatively affects Mercari’s business and product offerings.
Additionally, on-call members must devote considerable time to handling these incidents, indirectly reducing the time available for developing new features and impacting our ability to achieve business objectives.
As a result, reducing MTTR during incidents and mitigating the burden on on-call members have become critical challenges for the Platform team. With the advent of Large Language Models (LLMs), automating incident handling through their integration has emerged as a potential solution.
Deep dive: Architecture
Let’s take a closer look at the architecture of our incident handling system “IBIS”.
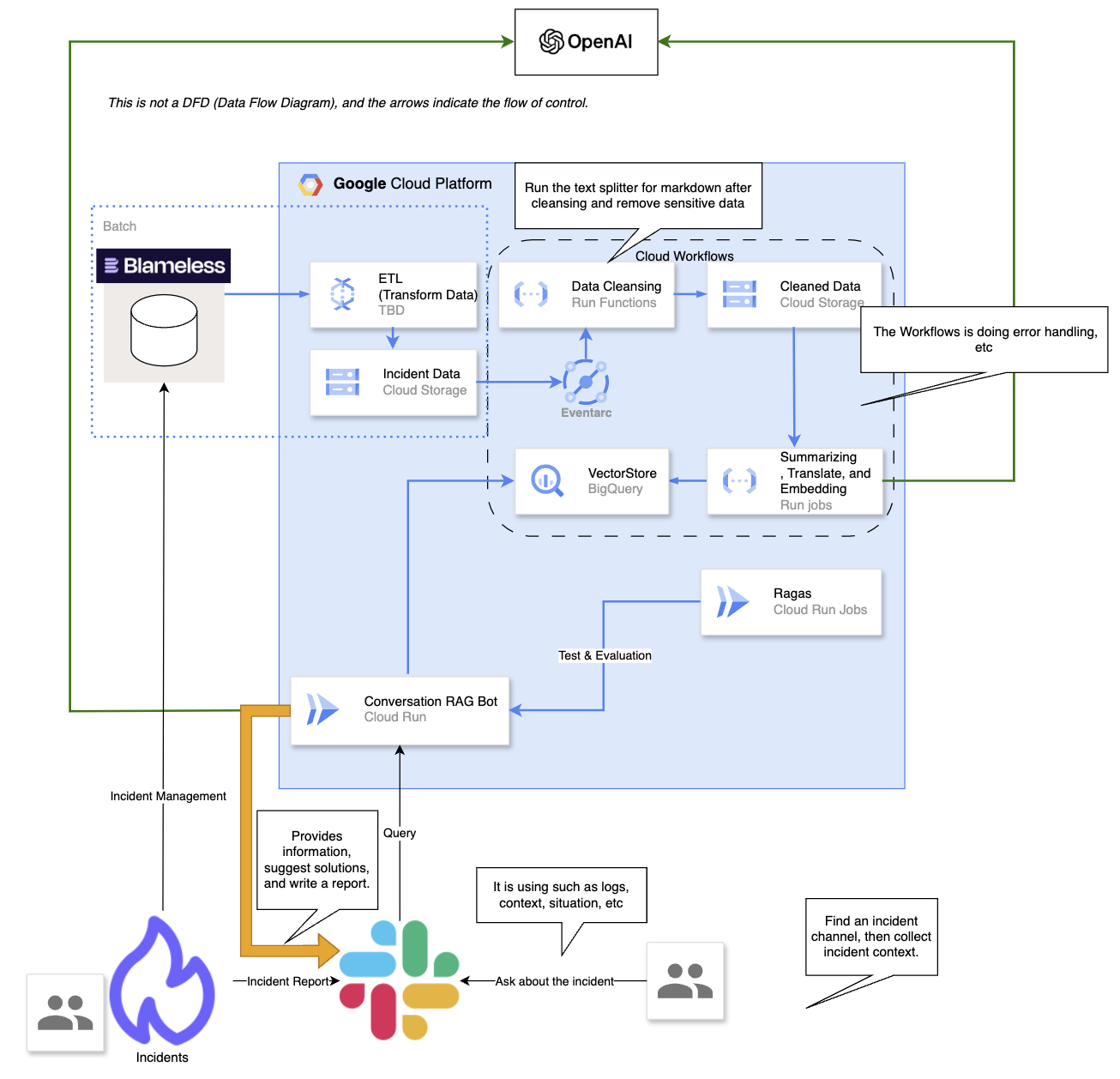
Fig 1. Architecture of IBIS
From a high-level perspective, we extract past incident retrospective report information from our incident management tool, Blameless. These reports include data such as temporary measures, root causes, and damages caused by the failures. This data undergoes cleansing, translation, and summarization processes. Subsequently, we utilize OpenAI’s embedding model to create vectors from these data sources.
When users pose questions to our Slack bot using natural language, these queries are also converted into vectors. The conversation component then searches the vector database for embeddings related to the question, and formulates a response to the user by organizing the relevant language constructs.
Let’s break down the entire architecture into two main components for detailed explanation: Data processing and Conversation.
Data processing
Below is the way how IBIS pre-process incident data.
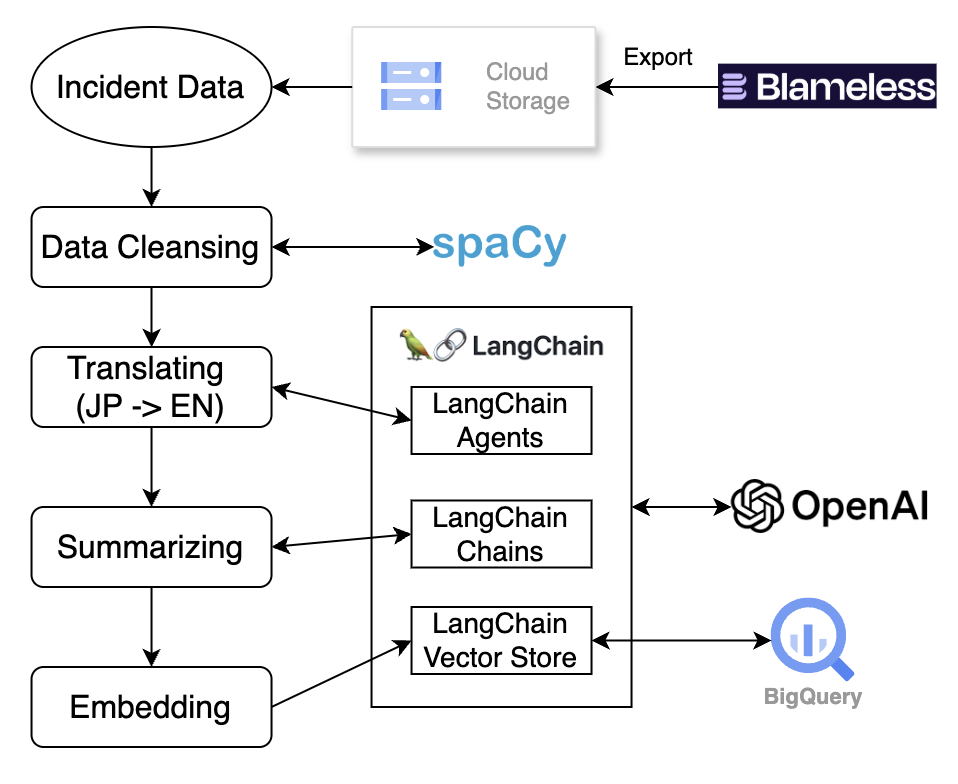
Fig 2. Data process progress of IBIS
Export data
Our incident management tool Blameless includes the process details of each incident, chat logs from incident Slack channels, retrospective reflections, and follow-up actions, among other vital pieces of information. We utilize Google Cloud Scheduler to regularly export the latest incident reports from Blameless’s external API into a Google Cloud Storage bucket. This process is designed to align with serverless principles and is executed within Google Cloud Run Jobs.
Data cleansing
We cannot indiscriminately send data obtained from Blameless into a Large Language Model (LLM). This is not only because the data contains numerous templates, which can significantly affect the precision of our vector searches (Cosine Similarity), but also because it includes a substantial amount of Personally Identifiable Information (PII). To mitigate the risk of potential information leakage and enhance the accuracy of the generated results, data cleansing is a necessary process.
To remove templates from the data, we leverage the fact that the data is in Markdown format and use the Markdown Splitter function provided by LangChain to extract relevant sections. As for PII, since it has multiple types, we opted to employ the SpaCy NLP model for tokenization and remove potentially existing PII based on word types.
The data cleansing component runs on Google Cloud Run Functions. From this stage onwards, we use Google Cloud Workflow to manage the entire system. When a new file is added to the Google Cloud Storage Bucket, Eventarc automatically triggers a new workflow. This workflow uses HTTP to initiate the data cleansing Cloud Run Function and, upon completion, proceeds to the next stage in the process, as shown in Figure 2. Introducing Cloud Workflow facilitates easier code maintenance throughout the ETL process.
Translating, summarizing & embedding
The cleansed data is then forwarded to the next stage of the process. Thanks to data cleansing, we can now confidently utilize the LLM model to process data smarter. Since both Japanese and English are used for writing incident reports at Mercari, translating these reports into English is a critical step for enhancing search accuracy. We utilize GPT-4o-based LangChain to handle the translation step. Moreover, since many reports are lengthy, summarizing the content is also crucial for improving vector search precision. GPT-4o assists us in summarizing the data as well. Finally, the translated and summarized clean data undergoes embedding and is stored in our Vector Database.
The translation, summarization, and embedding processes run on Google Cloud Run Jobs. Once data cleansing is complete, the Cloud Workflow automatically triggers a Cloud Run Job. As depicted in Figure 2, the embedded data is stored in our BigQuery Table using the BigQuery vector store package provided by LangChain.
Conversation
The Slack-based conversation feature is a core function of IBIS. In our design, users can directly engage with IBIS through natural language questions by mentioning the bot in Slack. To achieve this functionality, we need a server that continuously listens for requests from Slack and can generate responses based on our Vector Database.
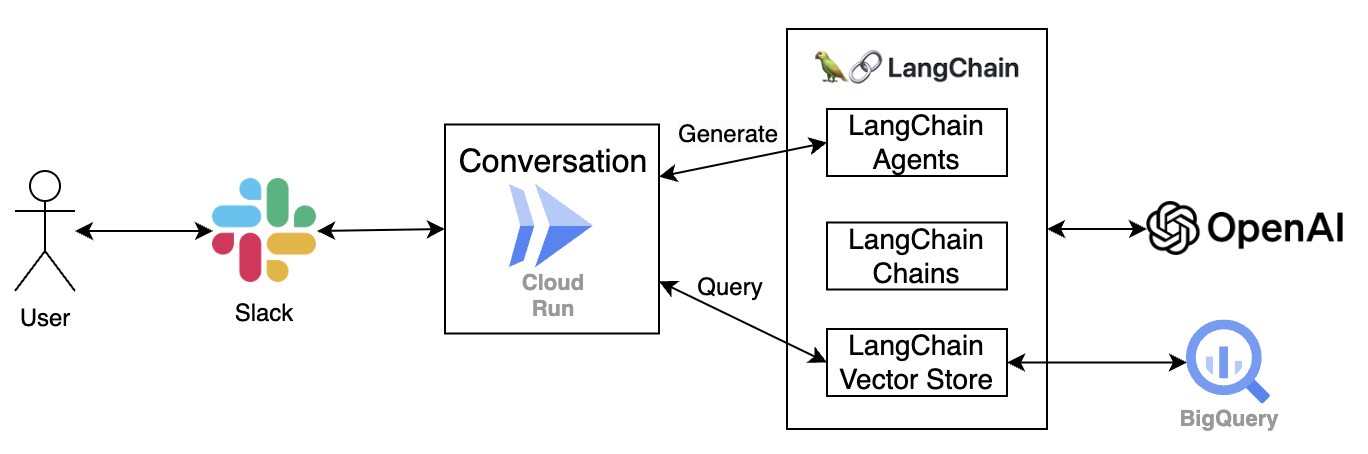
Fig 3. Conversation System for IBIS
As illustrated in Figure 3, this server is built on Google Cloud Run Service. It retrieves relevant information from BigQuery, which acts as our Vector DB, and then sends the data to an LLM model to generate responses.
In addition to handling queries, the conversation component also supports other functionalities, such as short-term memory, enhancing the interaction experience.
Short-term memory
Considering that an engineer’s understanding of an incident evolves over time, incorporating memory functionality within the same thread is vital for enhancing IBIS’s ability to resolve incidents and provide recommendations. As shown in Figure 4, we utilize LangChain’s memory feature to store both the user’s queries and the LLM’s responses from the same channel. If additional queries are posed in the same channel, the previous conversation in that thread is included as part of the input sent to the LLM.
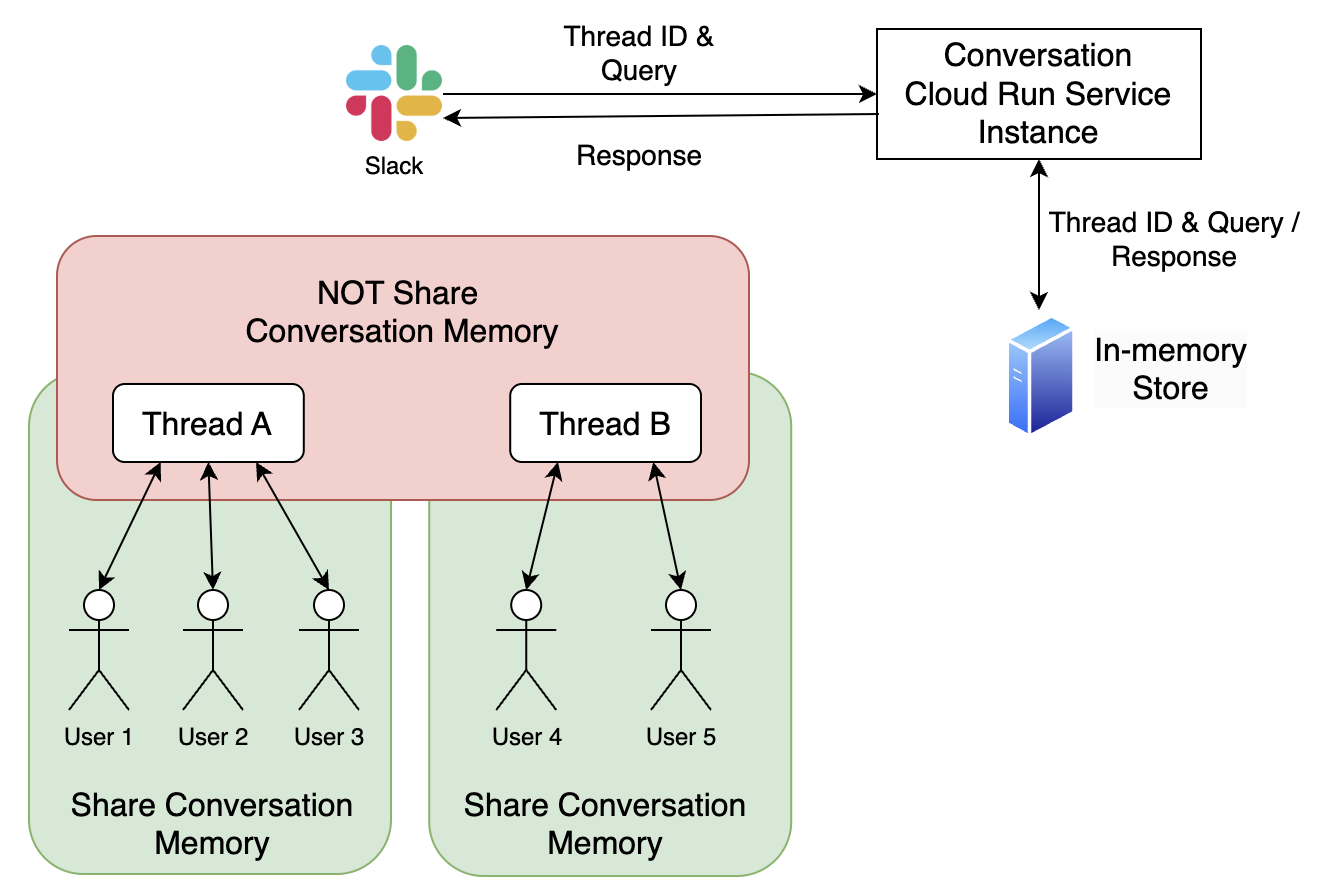
Fig 4. Short-term memory design
Given that this storage solution places the memory within the Cloud Run Service instance’s memory, any memory is lost when we release a new version of IBIS by re-deploying Cloud Run Service. For more details, you can refer to LangChain’s memory documentation.
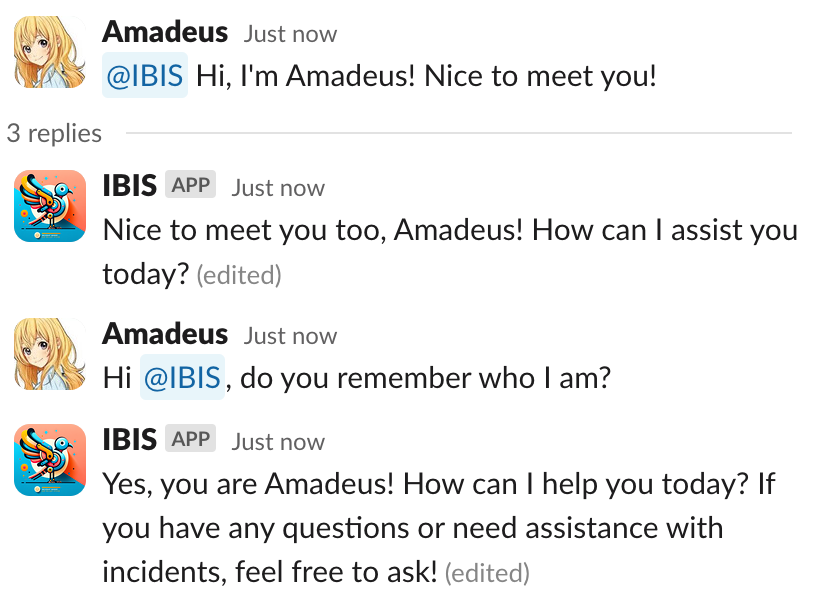
Fig 5. Case for short term memory
Keep instance active
Since our short-term memory functionality currently stores memory data in the instance, we must keep this instance active to avoid memory loss during cold starts. To achieve this, we implemented a strategy based on the guidance from this document. We regularly send uptime checks to the Cloud Run Service instance to ensure it remains active. This approach is straightforward and incurs minimal cost. Additionally, we have restricted the scale-up of this service by setting both the maximum and minimum number of instances to one.
Conclusion & Future plan
Conclusion
The first release of IBIS was completed at the end of December 2024. Until the time I wrote this blog (Jan 2025), IBIS had been integrated into several key channels for handling incidents at Mercari. The number of users leveraging this tool continues to grow. We will consistently gather user feedback and monitor its impact on Mean Time to Recovery (MTTR).
Future plan
- Accurately collecting user feedback is one of our core objectives. We plan to adopt a human-in-the-loop approach for automatic evaluations and gather user survey responses as data points to continuously enhance our product.
- Transit from the traditional mention-based querying method to a Slack form-based questioning approach. This change is intended to improve the precision of responses by refining user queries.
- Given the continuous updates to internal tools within the company, we plan to fine-tune our LLM model based on company documentation. This will ensure that the model provides the most current and relevant answers.
In Closing
Mercari, Inc. is actively seeking talented interns / new graduate Engineers, please feel free to explore our job description if you are interested.



