
The last couple of years have been quite revolutionary in the Silicon industry as a whole. With the resurgence of horizontal integration, fabless companies like ARM, AMD, and Qualcomm have disrupted the status quo with the help of foundries like TSMC and Samsung. While the hype has been proven real in the consumer market, things work a bit differently in the enterprise world. This article outlines how Mercari replaced all of our GKE nodes from E2 (Intel x86) to T2D (AMD x86) and saw at least 30% savings, similar to those claimed by companies moving from AWS x86 nodes to ARM based Graviton nodes.
Quick primer on pricing
Since this is an article about FinOps, let me give a quick primer on how CPU and memory pricing works on Cloud. Memory is pretty straightforward, you are charged a public pricing of GB/hour for every second you keep the node provisioned . This memory comes pre-attached to the CPU on the node, meaning you don’t really get an option of what the speed of this memory is going to be (DDR3, DDR4). CPU is charged a public pricing of unit/hour. Notice I mentioned “unit” because what you get in terms of CPU will vary from one SKU to another. Best case scenario is you get allotted a full core, but more often than not you will simply get a shared core (aka hyperthreads). In the worst case you might not even get a thread, but will simply be allotted “bursts” of CPU time on a core. This distinction will become important later in the article.
Next up are discounts. One of the selling points of Cloud is “unlimited scaling” but providing truly unlimited scaling is going to end up being too expensive. So Cloud providers want to incentivize their customers to behave more predictably as if they are running on premises. GCP does this by offering Sustained Usage discount and Committed usage discounts (CUD). On the other hand they make “unlimited scaling” feasible by offering Spot VMs. You get a very high discount if you use Spot VMs that can be evicted at any moment as soon as it is requested by some other customer willing to pay for on-demand pricing. Obviously you also run the risk of never being allotted a node if they run out of spare capacity. The last discount is Enterprise discount, which you get only on committing high upfront payment for a certain timeframe.
If you want to estimate the future cost of running a Kubernetes cluster using a specific type of node, the calculation quickly gets very complicated. Typically your workloads would autoscale using HPA and then the nodes themselves would horizontally scale using Cluster Autoscaler. The CUD pricing would be charged every single minute, regardless of whether you provisioned 100 cores or 1000 cores. You need to estimate the core-hours you will consume every minute, discount it by the CUD and then sum it all up to get the actual cost. If you were to migrate from node type X to Y because Y gives you a 30% reduction in CPU usage, then your overall cluster cost would not simply decrease by 30%. but 30% + x% depending on how many daemonsets you run on your nodes. This happens because each kubernetes node needs some system components running as daemonsets which also take up valuable CPU away from your applications, so the less nodes you are running the less overall CPU consumed by these system components.
What makes T2D so great?
The biggest selling point of T2D is that it does not have any threads, as in 1 thread == 1 core just like all the ARM SoC in the market right now. From our real world testing, this has not only proven much faster in modern languages like Go but also older languages like PHP saw similar benefits. In reality though, the only reason this works out is because GCP is charging a T2D core like a single thread and not 2x of a thread. In fact, T2D is nothing but a rebranded N2D node from GCP but with SMT disabled and with much lower pricing. The outcome is that you actually get almost 2 threads worth of performance and it costs only slightly more than 1 thread compared to the default cheap option like the E2 series from Intel.
Since T2D is slightly more expensive than E2, we had to create some estimates based on our current cluster configuration as to how much CPU & Memory reduction it was going to take to get to breakeven cost from migrating all workloads to T2D and further savings. One needs to be careful here because in the case of T2D, while the on-demand prices for E2 and T2D are nearly the same, spot prices on T2D are actually cheaper than E2 but CUD pricing of E2 is quite low compared to T2D. So your breakeven calculation will depend on the ratios of the mix, the higher CUD you have, the more CPU reduction you will need to breakeven, but in case of spot it’s a no brainer to switch from E2 to T2D. To make these estimations a bit more complicated, T2D doesn’t support custom sizing. So if you were on an E2 cluster with specific CPU:Memory size, you will now also need to account how much more you will need to pay for memory and CPU because you no longer have the option to increase/decrease the size of your node to perfectly fit your workloads on them.
To measure how much CPU you will save by switching to T2D we need to start benchmarking. One thing to note is the thread vs core I spoke of earlier, which will become quite important as you start measuring performance. Mercari is mostly a Go shop, so for us the difference between core and thread doesn’t really matter (as our benchmarks below will prove) because in Go it’s really easy to maximize the CPU usage as it doesn’t rely on OS level threads for concurrency.
| Model | Cores | Threads | Pricing (OnDemand in Tokyo) | Geekbench Single core | Geekbench Multi core |
|---|---|---|---|---|---|
| E2 | 16 | 32 | $1004/month | 1002 | 8685 |
| E2 | 16 | 16 | $1004/month | 994 | 7957 |
| T2D | 32 | 32 | $1266/month | 1672 | 17323 |
| N2D | 32 | 32 | $2532/month | 1601 | 17301 |
We start off with a purely synthetic benchmark – Geekbench. Here E2 nodes with SMT on and off result in very similar performance (because the benchmark is really good at maximizing whatever threads/cores are presented to it with minimal stalling). Next we have T2D and N2D nodes with 32 physical cores which perform 50% better on single core and 100% better on multi-core. But this benchmark may or may not represent real workloads. To get a more Go web service focused benchmark I ran go-web-framework-benchmark on all of the nodes which run various kinds of web-frameworks, all responding in a similar fashion under high amounts of traffic. We wanted to measure CPU differences, so we ran a CPU bound test case first and we saw AMD perform almost 100% better than E2. But in reality we are never CPU bound, and we are stalling a lot of time for databases, network, disk etc.
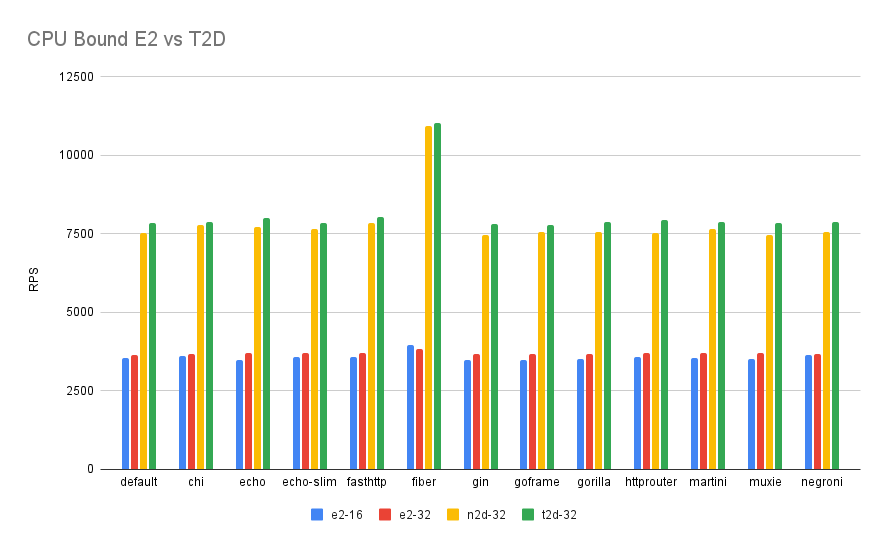
The next test was more “real world” as it had a 10ms processing time delay to simulate a real world like scenario where CPU isn’t the bottleneck. As you can see the difference between Intel and AMD depends heavily on what framework is being used, in fact fasthttp performs better on Intel with 16 cores than AMD with 32 cores!
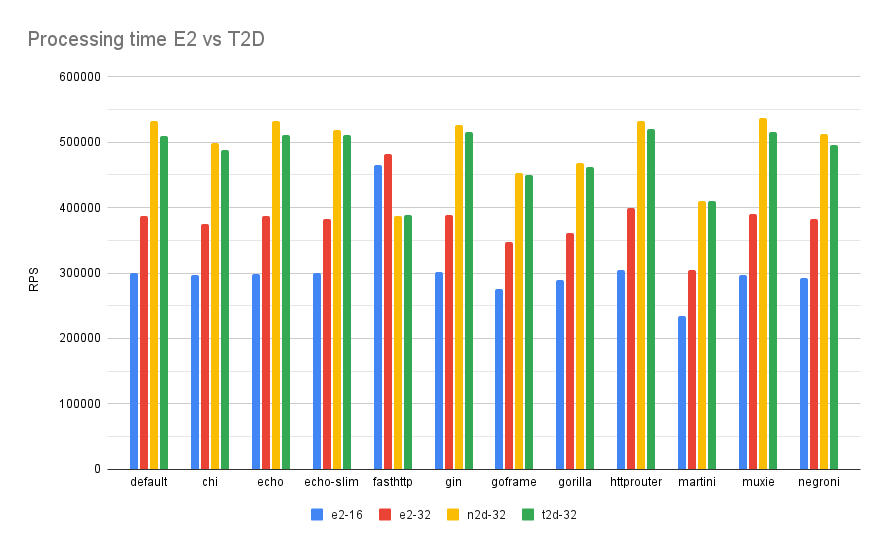
But in case of Mercari, we don’t always perfectly run a single application on a single server. It’s a time shared system based on a single huge GKE cluster with lots of over provisioned pods mixed together on nodes. So the only way to get a real benchmark was to actually run our services on T2D in production. We ran several canaries on different nodepools which included a variety of workloads like PHP monolith, Java based ElasticSearch cluster, Go services and even ML workloads. And they all saw nearly 40% reduction or more in CPU over E2 nodes which gave us the confidence to replace all of the nodes with T2D.
Another big advantage of staying on x86 architecture is since we aren’t switching CPU architectures here, there are not many changes needed in our existing infrastructure to migrate. In case of switching to ARM we will need to validate all different kinds of workloads, especially all 3rd party vendors or Open source projects, and need to make sure our CI can compile multi-arch images and our registry can store them correctly. All of this effort was saved when moving from x86 to x86!
One reason to focus so heavily on CPU is Amdahl’s Law. CPU is nearly 2x more expensive than memory on a standard 32 core-128GB node meaning, to save the same amount of money as saving 10% of CPU you would need to optimize nearly 30% of memory. Our real world benchmarks and estimations based on this showed that even with almost 2x more memory capacity per node, the CPU savings alone were enough to justify moving from E2 to T2D with significant overall savings.
Why did we not consider T2A (Ampere’s ARM servers)? GCP didn’t have them in stock in the Tokyo region, and the synthetic results seem to be slightly lower than T2D machine series, ondemand and spot instance prices are only slightly lower for T2A while there is no CUD for T2A which was a major deal breaker. And we were seeing overall savings in the same ballpark as other companies reported going from Intel to ARM based Graviton instances, so we don’t think we would have seen much difference had we chosen T2A
Migration process
The process of replacing nodes itself is quite minor and doesn’t require much effort.The difficulty lies in adjusting your workloads to make sure they are “rightsized” for these higher performance nodes. Mercari has around 350 microservices, so manually going around and adjusting these numbers is quite a task. Also, rightsizing, in it of itself is quite a challenging task. Simply reducing 50% CPU requests compared to E2 isn’t the right way to go about rightsizing because it’s possible that a service was unnecessarily over-provisioned/under-provisioned on E2.
The easiest path was simply relying on CPU based HPA autoscaling. A lot of our major services already had CPU autoscaling in place which automatically reduced the replica count once the service moved from E2 to T2D. We just needed to make sure the minReplica of HPA wasn’t too high for T2D or we may be stuck on minReplica for the majority of the time, thus seeing no savings.
For services not using HPA, we relied on VPA to give us new CPU request numbers based on their new usage pattern. VPA has been decent so far, we wouldn’t necessarily call it a silver bullet for Rightsizing our workloads, but that’s for another tech blog.
To finish off the migration you need to set up CUD. First off, you cannot start such migrations if you already have CUDs in place. GCP did recently introduce Flexible CUDs, but unfortunately it doesn’t cover T2D nodes. So you need to have a separate CUD for each machine type you want to use. Secondly, GCP doesn’t allow sharing CUDs between multiple projects, you can only do this if you have a single billing project and the rest of your projects are attached to this billing method. So we now create all CUDs under a single project and then share them using the Proportional attribution feature. This allows us to waste less of our CUDs in case we end up using less CPUs in the future. Another important point of consideration when deciding a CUD is since our traffic has very high peaks and lows, and we use ClusterAutoscaler along with HPA, our total core count is always in a flux. Creating a maximal CUD with minimal waste in such a case is difficult because if you overcommit you may end up spending more instead of saving. Your CUD should be equal to the global minimum count of cores used in a month. Which means your CUD will always be 100% utilized. Another drawback of making high CUD is you need to also consider future optimizations into consideration. For eg. if you were considering moving to Spot instances, they do not come under CUD, so you may end up in an overcommitted situation.
The bad & ugly
It’s not all rainbows and sunshine with T2D, it has its fair share of problems. Most critical one might be the risk of being out of stock in the GCP datacenter. Since it’s a new machine type, they do not have these nodes in high stock in all regions. So you need to make sure you don’t scale out too high without consulting with your GCP TAM. Waiting for T2D to be available in the required stock in the Tokyo region took us several months. The risk associated with T2D now is that we can’t simply scale out to any number of nodes we want. To reduce this risk we need to consider a fallback mechanism. Since most of our services are rightsized we can’t go back to E2 nodes, the CPU requests would be simply too small and they would thrash. And you cannot mix E2 and T2D nodes because HPA will end up misbehaving, half of your pods on E2 will be using too much CPU while the other half on T2D will be using too little. Since HPA considers average CPU utilization, it won’t accurately scale in or out the replicas. The only fallback nodes we can have are N2D nodes with SMT off. But the clusterAutoscaler isn’t smart enough to understand the difference between SMT on and off pricing, so it would randomly schedule T2D and N2D nodes even though these N2D nodes with SMT off would be almost twice as expensive for us.
The lack of custom sizing is also quite problematic, we end up wasting a lot of money on spare Memory on each node.
Future
We are quite excited about what the future holds for the Silicon industry. T2D is based on Zen3 which is already quite old in the consumer market. In the x86 camp, AMD has Zen4(c) based Bergamo and Genoa chips in the roadmap, Intel also seems to be catching up with Emerald Rapids. On the ARM side we already have some offerings from Ampere but it would be great to see some of those infamous Nuvia chips from Qualcomm.
On the scheduler side we would like see more optimizations in ClusterAutoscaler, especially if it could include the score of preferredDuringSchedulingIgnoredDuringExecution into account when provisioning a new node and consider true cost of node (which means including SMT config, CUD pricing and Enterprise discounts). Secondly, Kubernetes needs to have more support for heterogeneous node deployments. Not all cores are created equal, meaning if a deployment is scheduled on various machine types like E2, T2D, T3A etc it should consider each machine’s real CPU capacity rather than allocating equal timeshares like it currently does. We plan to workaround this limitation by making use of the long awaited in-place pod resize feature
Conclusion
From our experience the most important thing we have learned is to have a very scientific approach in such migrations, to not blindly trust the hype and to build your own hypothesis and test it before jumping the gun on such huge changes. As we saw, benchmarks do not show the entire picture, one should focus on what matters to your workloads the most.




