
This post is for Day 18 of Mercari Advent Calendar 2022, brought to you by @kaustubh from the Metadata Ecosystem team.
My team recently moved databases from local files in the codebase to an online Database. It took longer than expected but with good reason.
Wait, did you say local files?
One of the services my team maintains started as a proof-of-concept, focusing on a few e-commerce categories only. But unfortunately, we suffered from success. That meant we needed to expand our Metadata dataset to a large number of categories rather quickly.
Since serving the data had higher priority, and new data was added only once a month, data addition was not really a mission-critical feature to have. Until we struggled under the massive weight of positive results, and needed to effectively 10x our data size and 10x our traffic, at the same time.
(Cover photo by Chris Briggs on Unsplash)
Data addition as it was in the past
Mercari is a C2C marketplace, meaning there could be multiple listings of iPhones. A lot of details about these iPhones can be different (price, description) but some of the details will always have a finite set of options (like brand, color, iphone storage size), which we call metadata. My team manages & serves such finite sets and details.
You can see everything in the Mercari system that our team affects here.
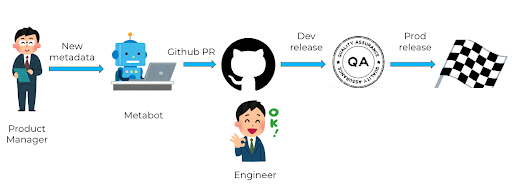
Any time a new brand or a product is launched in the market, we should have that new brand or product details available as metadata.We had a few bots and automations in place for the new data addition workflow.
- New data was aggregated manually (needs manual checks before addition)
- The product manager prepared the data in a specified sheet format.
- A slack bot first validates this spreadsheet, and then converts the spreadsheet into files to be added to the code repository as a PR.
- An engineer approves the PR, and deploys it to the dev environment.
- QA for sanity checks
- Engineer releases it to production
Why don’t we leave it at that ?
The workflow can be stopped at any of these points:
- Data validation required new rules, pretty much every time we added data.
- If data isn’t the issue, the PM is blocked by both engineer approval and dev release to start the QA the new data.
- If dev QA fails? Start over.
The first point may seem a bit odd, but in reality similar brand names exist with just the slightest of differences so that each of them can be unique. For example, there may already be a brand named “Brand” in the dataset, but if a new brand called "Brãnd" is launched, we’ll have to add an exception to our validation rules to allow this ã.
The above points would not have been a concern if we’re adding data in just two batches every quarter. But things changed. We progressed further along the adoption curve, and more teams wanted additional data. Which meant data addition was going to happen every 2-3 weeks. So the local storage solution wasn’t gonna cut it.
The task at hand
What we wanted to achieve:
- Product Manager should be able to add data
- PM should be able to roll it out to production (without engineer intervention)
- The service should work with no performance drops, latency changes within bounds.
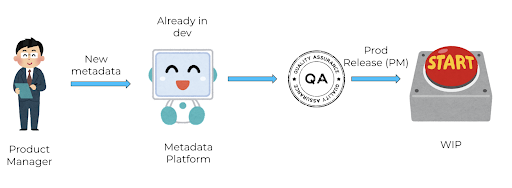
So our proposed solution was this:
- Build a bare bones UI that PMs can use to manipulate data.
- This UI could be used by external collaborators, because a permalink is better than a SQL query.
- Update the service to call an online DB, instead of local variables. (that was not a db)
We figured the UI can directly manipulate dev data, and once QA is done, there would be a big red button to sync dev and prod data. The team decided the functional requirements, and solidified the solution with a design doc. The team arrived on a consensus and the PM also seemed happy about it
On the backend, our service performs the following tasks:
- Validation
- Check whether we’re storing the right metadata for each item. This is important because certain metadata options might be disabled, or made temporarily unavailable.
- Listing
- There are multiple sources for metadata for an item: the only one from users is when sellers add it for listing.
- Worker
- Mercari uses PubSub for communicating between services / workers owned by different teams. This worker listened to listing events, and published to a few consumers.
These were the 3 tasks that we came up with: 3 tasks that 3 engineers can work on. Another engineer can work on the UI part.
Sounds straightforward, right ? Few sprints and we should be done, or at least this is what we sold to our Engineering Manager.
Hiccups before start
Anything that can go wrong will go wrong – Murphy.
Plug and Pause: Our initial plan was to write the UI / backend for UI in Node.js, because another team had already written what we wanted in JS. The problem with that approach was:
- The UI was too tightly coupled with the other team’s architecture, making it harder to adapt.
- The UI had different use cases than what we were looking for.
- Our codebase was in go & python only, and just 1-2 members in the team were comfortable with JS.
Rations & responsibilities: Our team was a backend team, we didn’t have any web engineers in our team, which meant that the UI must be maintained by people who were not too familiar with frontend development.
At the time, Mercari was working on a major rewrite so we weren’t going to get any web-side help for some time. This becomes relevant later.
Regardless of the challenges we knew upfront, the team had a positive outlook and we were pumped to roll this out.
Engineers at work

We had a new data schema ready. Most of the code was written, reviewed, and ready to release. We expected a smooth rollout.
Put a pin in it
As mentioned above, we planned to release the 3 major chunks of rewrite as 3 tasks. The first one (validation) was already in production, working well. As our planned release date approached, a new complication showed up. The company level rewrite was to go live in the coming days. To truly assess if the rewrite was effective, all releases were put on hold for some time. That meant our plans for gradual releases had to be replaced with a one-shot release.
One-shot release
This wasn’t something we wanted to do, but numbers were crunched, traffic was estimated, and the release tag cut. To start off, the migrated release seemed to handle traffic well. But as peak traffic arrived, we were greeted by pagerduty alerts. – an increasing amount of requests were timed out.
Just sprinkle some replicas on it
For the data set we had, we predicted the db had enough computing resources to serve at peak traffic. That was not the case. During peak traffic, requests kept getting timed out by the DB. We decided to add three large replicas, and scale them down as required – but that was not sufficient either.
Cache me outside
We’d predicted we’d need a cache to improve our latency, so this was in our plan anyway – but as an improvement task. We started off with an external cache that all server and worker pods would access. We started with using an external cache, however it would turn out to be more complicated than a quick in-memory cache for each service pod. After spending an uncomfortably long period of time on implementing a single external cache, we instead implemented a rather quick in-memory cache that would get the job done.
Trust nobody – not even your own SQL code
Before we implemented the cache, the team agreed that the cache should not be a system-critical component of the architecture; it should be an enhancement. So we beefed up our DBs and replicas and did a last hail-mary release before releasing the cache. As traffic came in, so did the pagerduty alerts but the DB and replicas were not showing any problems.
After some service profiling, our Tech lead led us to glorious redemption with a few optimized SQL calls. The cause: We initially started with the simplest SQL query, and added preloading with the expectation it would speed up response time. It was doing the opposite in a few cases, so we removed preloading in a few non-service-critical queries, and that stabilized the performance. The cache further helped improve costs and performance, and we all lived happily ever after.
Conclusion: Making better mistakes

I organized a KPT retrospective for the project, to understand what we could have done better.
Under-promise, over-deliver
Communicating with the end users with just a design doc is not enough. Sometimes they don’t know what features they want unless they see actual mockups of the final product – then it’s easier for them to point out what they want or what they don’t want. As a result we had to continuously improve our data manipulation UI when PMs actually started using it, because they were not aware of some details.
Track everything
Before the release, we had 30 monitors and 6 observability dashboards. Now we have 40 monitors and 8 dashboards. For a project like this, a few metrics that we should have tracked from the beginning were:
- DB query time (the time to actually perform the query) and DB response time (the time between receiving the request and sending a response)
- Avg CPU, Memory, numbers of containers running – for the DB, not just the service
- Make better calculations – Back-of-the-envelope calculations should be restricted to non production releases, probably involving the architects and platform team to understand what metrics you need to calculate.
Granular releases
This was something we wanted to do from the start, but could not due to external factors. We should have not tried to release everything at once. We also should have questioned and reviewed our own code more, instead of having our releases reveal them to us.
Make your mistakes public
We intend to share our findings at an org-level internally so that other teams can save a lot of precious time, money, resources, ~sleep~ that we overspent.
One of the things I truly appreciate about being at Mercari is the ability to own up to your mistakes and being able to write this kind of an article. The environment is friendly, yet nurturing, lenient yet accountable. If that does not sound like your current workplace,that can change. Here’s my post from our 2021 advent calendar about career change, and here is our job portal. Come join us, we have snacks!
Tomorrow’s article will be presented by the US DRE team. Please look forward to it!



