This article was written as "Series: The Present and Future of the RFS Project for Strengthening the Technical Infrastructure".
My name is Eric, and I’m part of the Transaction Team at Mercari. In this article, I will outline the steps our team took to onboard ourselves to work on an unfamiliar codebase, and how we are progressing with our work to modernize it. It is worth noting that this process is very much ongoing, so this post is more of a progress report than a postmortem.
Background
In Mercari parlance, a "transaction" is an entity that is created whenever one user (the "buyer") purchases an item from another user (the "seller"). This transaction entity then passes through a series of state transitions before it is considered complete. Likewise, state transitions can trigger other events, such as the capturing of escrow, and updates to user ratings. They are at the core of many critical parts of the Mercari user experience:

We consider the "transaction domain" to be the set of functionalities that governs these state changes. The code related to Mercari’s transaction domain is located squarely within our PHP monolith, and it was notorious for being difficult to work with. Indeed, our organization was hesitant to add new features to it, because it was regarded as too byzantine to understand as a whole, and too brittle to risk changing in any significant way.
It was this environment that our newly formed Transaction Team was thrust into, tasked with taking over this chunk of the monolith in the autumn of 2021. When the team was first formed, only a couple of us had ever given this code more than a passing glance, and none of us had any familiarity with the business logic that it contained.
Improving familiarity
The transaction code in Mercari’s monolith includes roughly 40 REST endpoints, built up over nearly ten years of development. The application code was roughly object-oriented and nominally followed the MVC pattern, but due to its age, had become weighed down by inconsistencies. While some documentation was present, it was not being checked via automated testing, which meant it was prone to falling out-of-date.
The above problems made it difficult for us, as the new owners of the transaction domain, to understand what was happening in our code. And without thorough, reliable documentation, other stakeholders viewed the transaction code as a black box. As a result, those stakeholders were unable to reason about the feasibility of new features.
For example, if we wanted to make a change to a functionality that depended on the transaction code, we couldn’t easily say which of our endpoints would need to be updated to support that change. Even if we overcame this, there were problems when client teams attempted to integrate with our API endpoints: the process required them to reverse engineer how to call those endpoints, or ask our team directly for examples. Often this meant that our documentation was ad hoc and on-demand, pasted into Slack messages. This situation is obviously untenable for all involved, so we set about to make everyone more familiar with the transaction domain first.
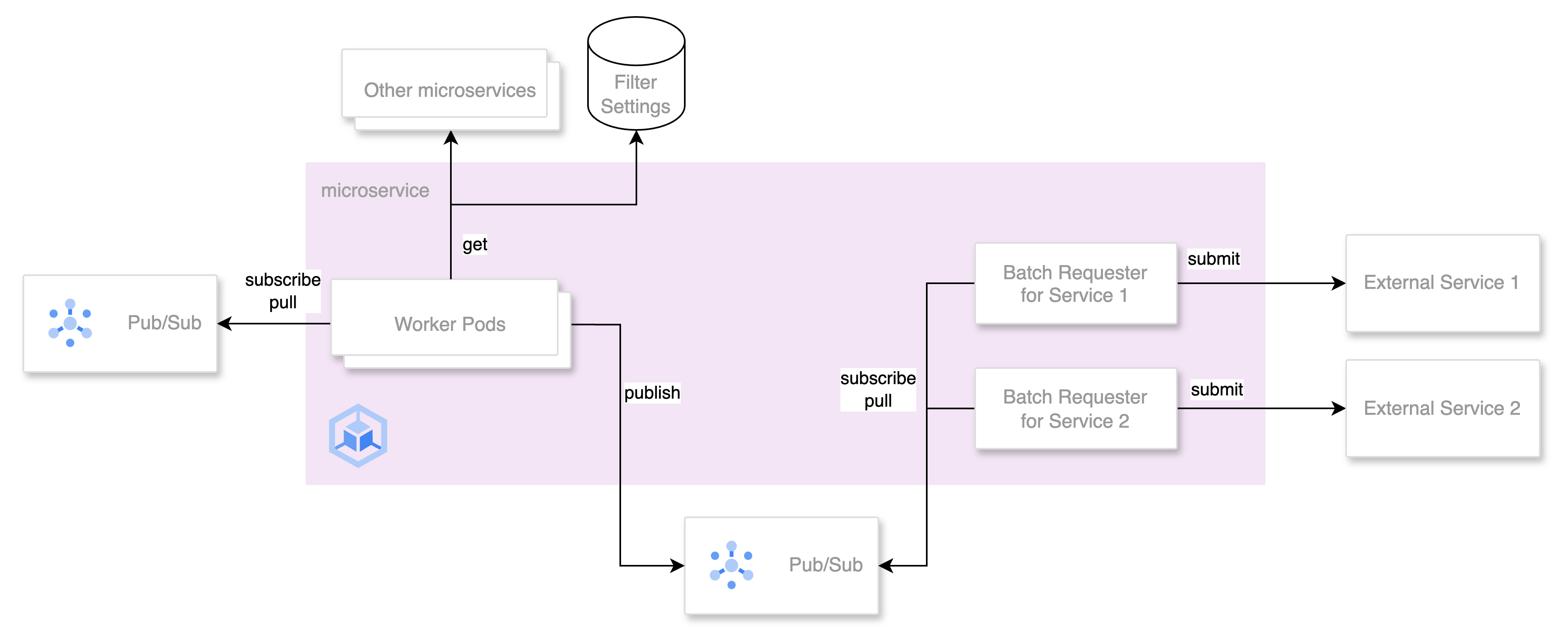
In order to improve our team’s own understanding of this legacy codebase, we planned a series of "code reading parties". Each team member was assigned several REST endpoints to analyze. They would be tasked with doing an archaeological dive into the underlying code, in the process writing a human-readable description of what it does. They would also document which database tables were read from and written to, and listed any dependencies on other services. The output for a single endpoint would look something like this:
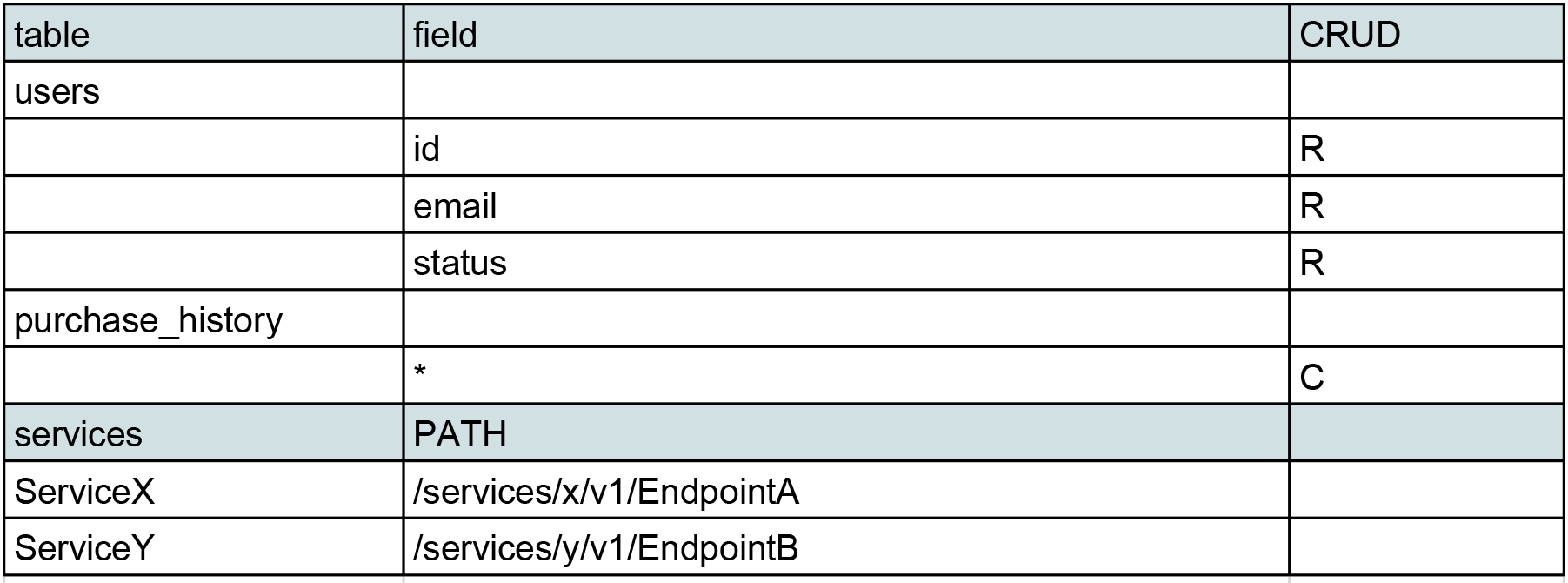
In this case, our endpoint is reading several fields from the "users" table, and creating a record in the "purchase_history" table. In addition, it’s calling both ServiceX and ServiceY as part of its processing.
Once this documentation was prepared and other team members were given a couple of days to read through it, we held an online discussion about the endpoint to allow everyone to ask questions about functionality and clarify details about the specification. Corresponding parts of the documentation were updated immediately after these meetings to include any new points that came up during the discussions. We’ve also continued to revise that documentation as our understanding of the domain improves. Additionally, these meetings were recorded so that new engineers can view them as part of their onboarding process.
These online events resulted in better understanding of the codebase among our current team members, and provided improved onboarding materials for future members. As a first pass through the code, we were satisfied with this output, but recognized that more needed to be done to make client integration even easier.
While the original documentation was written in Google Sheets and Confluence primarily for human consumption, this did not address the issue of the documentation needing some form of validation to ensure that it did not fall out of sync with implementation changes. This remains an ongoing project for us, but as a first step, we have been documenting our REST endpoints using OpenAPI. This has allowed our QA team members to write automated tests to verify that our documentation is up to date, and we are moving towards including this testing into our continuous integration process.
Our hope is that these changes will make it much easier for client teams to integrate with our REST endpoints, as this new (and newly validated) documentation includes example requests and responses, as well as a thorough list of error cases.
Moving Towards a Modular Monolith
During the investigation described above, we realized there were two problems standing in the way of the transaction code being more extensible:
- Our code was being used by lots of other code in the monolith
- The "transaction domain" encompassed a number of features, and we needed to decouple these both from a technical and from an organizational perspective
We decided to start refactoring our code based on the modular monolith pattern. We worked to define an interface that could be used by other parts of the monolith that wanted to access transaction domain functionalities. We also started to divide the code into a collection of loosely coupled subcomponents. In this way, each subcomponent could be developed, and owned, independently.
Decoupling the Monolith
As an example, let’s look at a simplified application structure:

In this application, we have a database table with a model to represent the resources in that table. There is also a service, which serves as an interface for parts of the monolith that wish to operate on that model, and allows for other nice bonuses like dependency injection during testing. And finally, we expose a REST endpoint, /transactions, to the outside world.
As mentioned above, we would normally expect other non-transaction parts of the monolith to interface with transaction code via the service layer:

The service would be considered the "public" interface for any transaction code within the monolith, so calling it from another endpoint would be acceptable use. However, we noticed that in many cases, other monolith code was accessing the model directly, or even reading directly from database tables:

This meant that we could not confidently modify our data models or schema to add new features, since we could potentially break some unrelated functionality elsewhere.
In order to understand where these violations were occurring, we created a script to find the usage of non-public transaction classes by other monolithic code. This script was built upon the open-source tool dephpend, and generated a report of afferent couplings (or, "incoming dependencies") for our code.
For example, given code like the following, where the SomeModule class is referencing PrivateTransactionClass:
class SomeModule {
public function run(): void
{
$transaction = new PrivateTransactionClass();
// … do something with $transaction
}
}This script would generate output like the following:
{
"from": "Mercari\MyNamespace\SomeModule",
"to": "Mercari\Transaction\PrivateTransactionClass"
}While dephpend generates a list of all afferent couplings, we were only interested in couplings that involved classes we considered to be private. So, we added annotations to each class using PHPDoc blocks to indicate which classes were public, and which were private, and filtered the output based on those rules.
Since we now had a measure of the problem, our new goal was to gradually reduce these usage violations by refactoring code to reference public classes instead, adding new methods to those classes as needed. Since the monolith’s code is owned by several teams, this required the assistance from those teams to refactor their code, or to review the pull requests created by our team.
Once we had the initial version of the script completed, we included it in the monolith’s continuous integration process, so it would run against every new pull request created in the repository. Effectively, we were looking for any new usage of transaction code that might be contrary to our expectations. In this way, we have been able to continually monitor how other code references the transaction code, and update our own interfaces when new use cases arise.
Dissecting the Transaction Domain
Despite all the effort invested in decoupling transaction code from other parts of the monolith, it was more challenging to delineate the components within the transaction domain itself.
Even a cursory investigation of the code revealed that what we had been previously referring to as the "transaction domain" was actually a collection of loosely related functionalities that required immense domain knowledge and maintenance resources for a single team to handle. It became clear to us that management of the code would be much easier if we could separate elements of the code into discrete subcomponents.
For example, each subcomponent could be owned by a different group of engineers, thus reducing the overall amount of domain knowledge required for any one person to work with the transaction domain. Additionally, while migrating the transaction code to a microservices model had stalled, it would be a different story if we were able to successfully modularize elements of our code. It would make a hypothetical move to a new microservice much easier, as we would have already done the hard work of designing the necessary interface.
Drawing domain boundaries is a tricky problem. One method we briefly explored was using a tool to examine the commit history to discern which features are closely related. We weren’t happy with the results of that investigation, however, and eventually settled on a scheme that mapped more directly to the user’s experience of the product. As such, the decision was made to try splitting the transaction domain in two:

Everything up to and including the user paying for the transaction was grouped under the "checkout" domain, and everything after that point would be part of the "transaction" domain.
This split was chosen because it neatly marks when the buyer has successfully completed all initial requirements to instantiate a transaction. Later transitions are more of a mix of buyer and seller actions, but looking from the user’s point of view, this felt like the appropriate place to make the first big split.
With this division in hand, we could better categorize functionalities based on which domain they impacted directly:

The details of how some of these subcomponents are being designed will be the subject of future posts.
Conclusion
One year into our quest to modernize the transaction code, our team is much more familiar with the domain than when we started. Both design and implementation work for the various subcomponents are still in progress, and we’re aware that the boundaries between those subcomponents, or even the split between the checkout and transaction domains, may change in the future. However, we’re confident that we’re moving towards a transaction system that can better handle the changing needs of the business.
If you found this article interesting and are interested in working together on core features of the app, see our job openings!