*This article is a translation of the Japanese article published on March 11th, 2022.
Hello. This is Fujimoto (@jimo1001) from the Mercari Microservices SRE Team.
I’m currently working as an Embedded SRE on the Search Infrastructure Team. The Search Infrastructure Team manages a search platform that uses Elasticsearch, and provides search functionality for various microservices. This massive search platform accounts for a large proportion of Mercari’s machine resources, and is crucial for supporting Mercari search operations. My mission as an embedded SRE is to improve search platform reliability and promote automation. In this article, I will provide some operational tips on using Elasticsearch.
What is Elasticsearch?
Elasticsearch is a search engine developed by Elastic, and is based on Apache Lucene . In addition to providing fast full-text search and several analysis features, it can also be expanded using plugins. It operates by being distributed over multiple nodes, allowing search performance to be scaled. Elastic Cloud on Kubernetes (ECK) can also be used to configure it on Kubernetes for even better scalability, allowing for truly flexible operation. Broadly speaking, Elasticsearch is a piece of software corresponding to a data store, so its structural elements differ greatly from a standard RDB. Let’s start by introducing these structural elements.
Physical structural elements of Elasticsearch
Let’s start with the physical structural elements used to configure Elasticsearch. These include clusters and nodes.
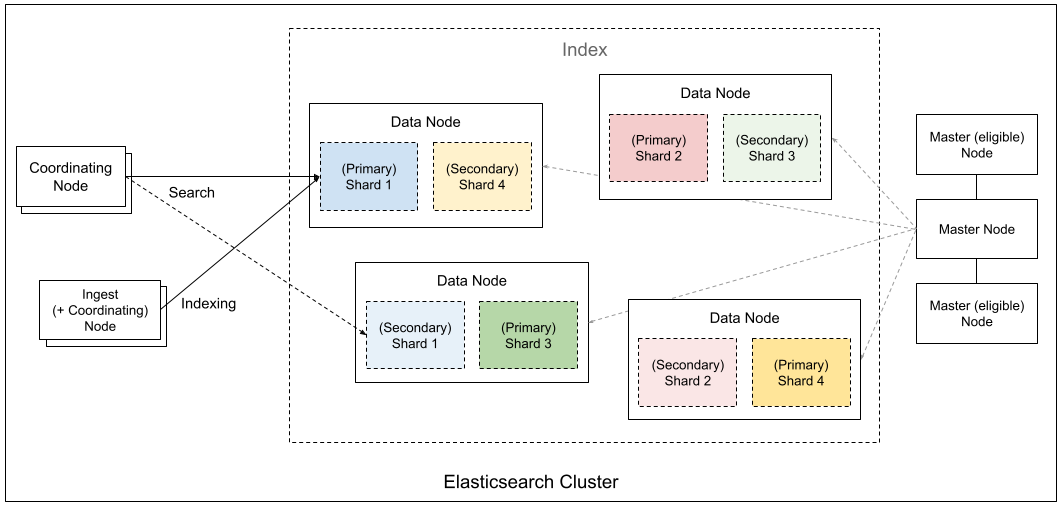
Elasticsearch Cluster
This is the largest structural element of Elasticsearch. It’s a distributed system that provides the search and management features for the program. It is composed of multiple nodes, which are described below.
Elasticsearch Node
This refers to a single server on which Elasticsearch processes run (or a "pod" for Kubernetes). In Elasticsearch, nodes are managed with multiple roles. The major roles are as follows.
Master
The master role is given to the node that controls the cluster. This master node must be composed of at least three servers[1]. One server will be the master. The others will be set as spare nodes that are "master-eligible," and can be elevated to the master role if the master node goes down.
[1]: If there are two master nodes, the other node will also be elevated to master if a network outage or other issue occurs. Each node would then form its own Elasticsearch cluster, which could result in data inconsistencies (a "split brain" situation).
Data
As suggested by the name, the data role handles data. It holds data to search at the "shard" level, and performs processes such as search and aggregation. These processes require lots of machine resources, including:
- Local storage
- An SSD or other high-speed storage is required to keep local storage permanent for search data. Elasticsearch provides replica functionality if using a RAID configuration, so in my opinion it’s best to use RAID 0 (striping) for performance.
- CPU
- Plenty of computation resources are required for the search and aggregation processes, so a sufficiently fast CPU is required.
- Memory
- When deciding how much memory to use, you need to also consider the page cache (a file system cache for accessing data at high speed) and the heap size allocated to the Elasticsearch JVM.
Ingest
This converts documents when indexing ingest search data.
Coordinating
This role is given to a node that receives requests (for search, indexing, etc.). For search, requests are sent to the data nodes in each shard, the results are merged, and then the final search results are returned as a response. For indexing, the storage shard is determined and then the request is sent to the data nodes in the primary shard.
Logical structural elements
Next, let’s take a look at the internal structure of the index that holds Elasticsearch data ("documents").

Elasticsearch Index
The Elasticsearch index can be thought of as a collection of documents in an Elasticsearch cluster. Multiple indexes can be created in an Elasticsearch cluster to manage documents.
Shard
Shards are allocated based on the number of indexes specified. The number of shards is determined when defining indexes, and there are some constraints on changing this number after it has been set. Data is managed internally using a Lucene index (an Apache Lucene data structure).
Replica
This is a copy of a shard. The shard that directly receives updates is called the "primary shard," while its copy is called a "replica shard." The number of replicas has an impact on availability and search performance, and can be changed at any time. If a primary shard is lost for some reason, one of its replica shards will be elevated to the primary shard.
Segment
The Lucene index managed by shards manages groups of documents at the so-called "segment" level. Segments are generally immutable, so deleting a document will not actually delete it from the segment. Instead, a record indicating that the document was deleted is generated (in other words, it’s deleted logically and not physically). This would gradually increase the data size, so segments are regularly merged with any deleted documents excluded.
Document
A single document represents a single piece of data.
Structure of Elasticsearch in the Mercari search platform
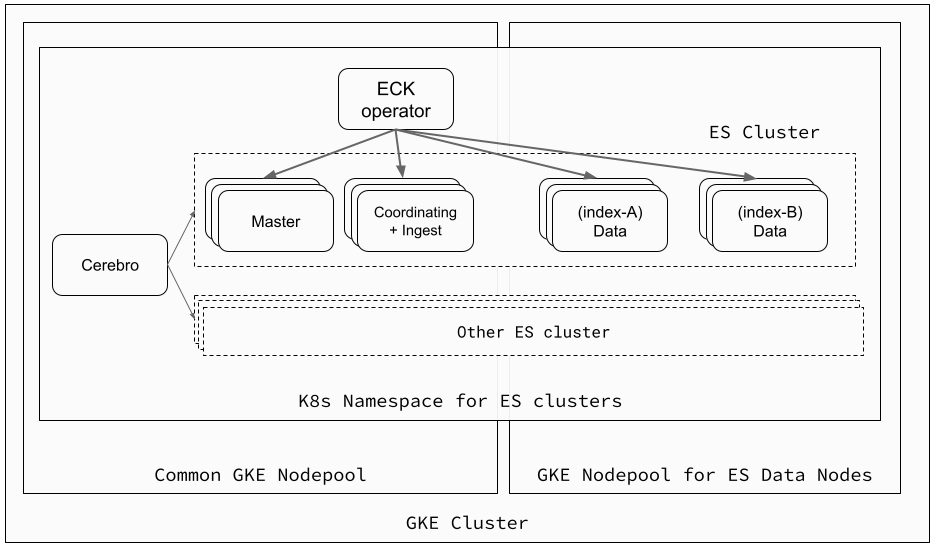
The Mercari search platform consists of multiple Elasticsearch clusters running on a common Kubernetes cluster for all microservices, and uses Elastic Cloud on Kubernetes (ECK) to manage all Elasticsearch clusters. Each Elasticsearch cluster consists mainly of a data node set containing a master node, coordinating (client) node, and data nodes for each index. Kubernetes Elasticsearch resources provided by ECK are defined in manifest files and managed via code.
The current structure of our search platform is the result of a lot of trial-and-error. You can find more information about this in the following article.
How the Mercari search platform has changed over time (Japanese only)
Machine resource optimization
Nodes from a shared node pool are used for the master and coordinating pods. However, data pods use up a lot of CPU and memory resources, so we’ve prepared an optimized machine type node pool for them. This also allows us to delete excess resources, which helps to reduce costs.
Elasticsearch cluster management
Although we use the Elasticsearch REST API to perform operations such as building an Elasticsearch cluster or changing the number of replicas, we use a web management tool called Cerebro more often for this. This tool can be used simply by deploying it anywhere with access to the Elasticsearch cluster. You can check statistical information such as the number of documents and data sizes, change cluster and index settings, relocate shards, manage snapshots, and perform restores, all using an intuitive GUI. It’s very convenient.
Determining the number of shards
The number of shards is determined when creating an index, so it can be difficult to change this number later. Our solution is to predict how much data will grow and estimate what the final size would be. We determine the number of shards by thinking backwards from how much data we can manage based on the data node machine specifications, and then calculate it from the data size above. The priority for a search platform is on search execution speed, so we adjust this so that all data can be cached to RAM.
Availability and scalability
The number of replicas is generally proportional to availability, and can be used to increase the maximum number of scalable nodes (for example, if there are five shards with one shard placed on one node, we can increase the number of configurable nodes from 10 to 15 by changing the number of replicas from one to two). At least one replica must be configured for the sake of availability. If there is no way to recover from scratch, then at least two or three replicas should be configured. As for scalability, if CPU utilization or latency indicators show that our performance requirements are not being met, we can resolve this by increasing the number of data nodes and replicas. There’s an important point to keep in mind for scaling out—adding a replica will cause a sudden spike in network traffic as its data is copied, which could place a heavy load on existing nodes or cause network congestion. Scaling out will therefore need to be handled outside of peak usage hours.
Indexing
At Mercari, we have two methods for indexing product information. They are described below.
Online Indexing

Online indexing is used for streaming Mercari product information additions, changes, and deletions in real-time. This product information is sent as Google Cloud Pub/Sub messages. Dataflow optimizes the data structure for search, and this is finally saved in the Elasticsearch index. There are multiple information sources for online indexing, and they run in parallel in order to perform indexing.
Offline Indexing

This is a batch process in which indexing is performed from information for all products stored in Cloud Bigtable. This is used only in certain circumstances, such as reorganizing the Elasticsearch index. There’s no need to reflect changes to search when running offline indexing, so we accelerate this by setting refresh_interval to -1 in the index settings. It’s important to remember to revert refresh_interval to its original value once indexing is complete.
PUT /myindex/_settings
{
"index" : {
"refresh_interval" : "-1"
}
}Monitoring
In order to maintain Elasticsearch search performance, we need to monitor various performance indicators and detect when problems occur. Some of these monitoring operations for Elasticsearch are covered below.
Cluster Status
We monitor cluster status to keep our Elasticsearch clusters healthy. A green status means everything is fine, a yellow status means we need to check something (only a Slack notification is sent), and a red status means that immediate action is required.
Latency

We monitor the latency of search requests (95 percentile and 99 percentile) for each Elasticsearch cluster. Notification is provided if a value exceeds its threshold.
We use these latency indicators as SLO SLIs, and we also monitor how our SLO error budget is being used.

Detection of abnormal CPU utilization

The Elasticsearch clusters we use at Mercari are composed of many data nodes. Sometimes, these nodes might become unstable and increase CPU utilization. These nodes can reduce the performance of the entire Elasticsearch cluster, so we detect any nodes with suspicious CPU utilization. However, if we just look for outliers, we would also detect data nodes not being used immediately after adding them. Therefore, we monitor this along with CPU utilization.
Operations
Below are a couple of the many operations tricks and tips we have discovered in operating our search platform.
GKE upgrades
As I mentioned above, our search platform data nodes are managed using a dedicated GKE node pool. This node pool is managed by the Search Infrastructure Team, so we need to upgrade GKE whenever we upgrade the shared node pool.
We considered upgrading either manually using the gcloud command (surge upgrades), or by creating a new node pool and migrating to it. We decided to go with the latter, as the former could result in having to forcibly shutdown pods if they were taking too long to restart.
The workflow is very simple.
- Create a new node pool with the same label as the existing pool
- Disable auto-scaling on the old node pool (so that we can reserve a GKE node required for a fallback)
- Implement a cordon so that new pods are not scheduled in the old node pool
- Restart the Elasticsearch data nodes
- Delete the old node pool
Once the data nodes have restarted, they will be scheduled in the new node pool. You can restart the data nodes one after another to migrate them.
The number of data nodes will increase temporarily during the migration process, so it’s important to prevent the number of VMs in the GCP instance group from reaching the upper limit. (If the upper limit is reached, you won’t be able to create more pods.) You can check this upper limit on the "IAM" GCP management screen (in the "Assignment" section). It’s a good idea to get into the habit of checking this regularly if you’ll be doing anything that temporarily uses a lot of resources. If there’s any possibility of reaching this upper limit, you should contact support and request that the upper limit be relaxed.
Elasticsearch upgrade
We had been using Elasticsearch version 6.x for some time for our search platform, but recently upgraded to version 7.x. This is a major version upgrade, so we couldn’t use rolling updates. Instead, we used the following procedure.
- Create a new Elasticsearch cluster using the new version
- Use offline indexing to re-index
- Migrate traffic gradually to the new Elasticsearch cluster
- Delete the old Elasticsearch cluster
You can create a cluster and migrate as described above, as long as you have some means of re-indexing. This makes it easy to perform a major version upgrade.
Conclusion
In this article, I covered how the Mercari search platform is structured, and provided some information on how we monitor and operate it. We run into all sorts of issues managing and operating Elasticsearch, and so we continue to search for solutions. I hope this article will be of help to others using Elasticsearch.
I also posted an article the other day on Benchmarking automation to maintain search response performance (Japanese only) Please give it a read if that sounds interesting.
We are currently hiring Microservice SREs and are conducting casual interviews at Mercari. Please contact us if you’re interested!




