This article is a translation of the Japanese article published on February 18th, 2022.
Introduction
Hello! This is @takashi-kun.
My team has been posting a series of articles on the "Blog Series of Introduction of Developer Productivity Engineering at Mercari" . As Mercari continues to grow, we are finding ourselves with many legacy technologies. In this article, I’ll discuss how we, as a Core SRE team, are dealing with these technologies based on concrete examples.
What comes to your mind when you hear the word "legacy technology"?
You might think of technology that uses older middleware, is written in older languages, or uses on-premises environments.
Our systems continue to expand every day due to the speed at which Mercari operates, which leaves us with more than a few systems without owners/maintainers. It’s a lot of work to figure these systems out without any owner or maintainer while responding to alerts or relocating them, and there are a wide range of important points to keep in mind, making it difficult to identify the scope of effect of anything we do.
In this article, I define "legacy system" as "a system without an owner/maintainer" which can be divided into two major categories of legacy systems: stateful and stateless systems. A stateless system is a server that generally does not maintain a state. Some examples include API servers and proxy servers. A stateful server, on the other hand, maintains a state (data), such as a DB. In this article, I’ll select both a stateful and stateless "legacy system," and explain how we’ve examined and improved them.
Stateless oauth-proxy
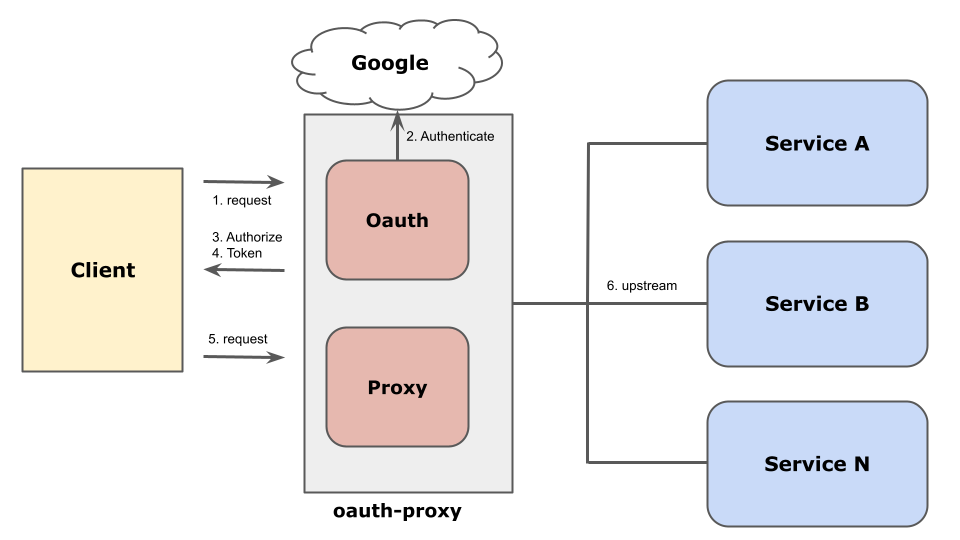
To begin with, I’ll start with a stateless system, oauth-proxy. We’re currently involved in a large data center migration project, and one of the systems being migrated is oauth-proxy, which has been in operation for a long time.
oauth-proxy, as shown above, is an authentication infrastructure system used to control access to various internal systems, at the Google account, group, and organization levels.
While planning to relocate oauth-proxy, we first looked into using Identify-Aware Proxy (IAP).
Using Identify-Aware Proxy
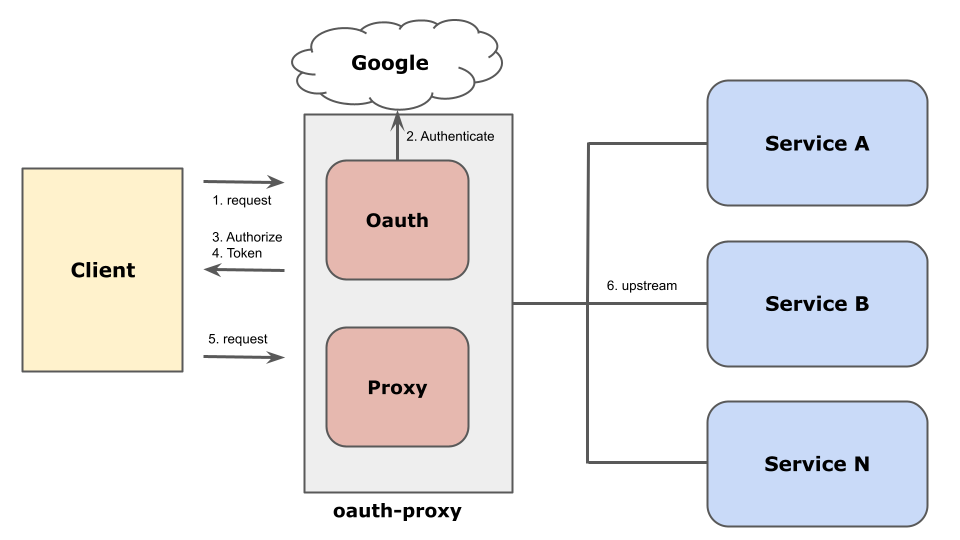
IAP is a proxy used to control access at the Google Workspace user, group, service account, and organization levels. It can be used to provide access control at the TCP level to an HTTP(S) load balancer or GCE.
(https://cloud.google.com/iap/images/iap-load-balancer.png)
For the backend of the load balancer, you can use GCE or any of several Google managed services (such as GAE or Cloud Run). This means that if you can use IAP, you can also migrate it completely to a GCP managed service.
We can replace almost everything done by oauth-proxy (shown in the previous diagram) with IAP, and so we wanted to use Google managed services during the relocation.
Allow me to skip to the end conclusion of this story: we were unable to use IAP in the relocation process.
Although we were able to replace most of the sites on the backend of oauth-proxy, we discovered that one particular service would be difficult to replace.
The service is called db-proxy, and it’s structured as shown below.
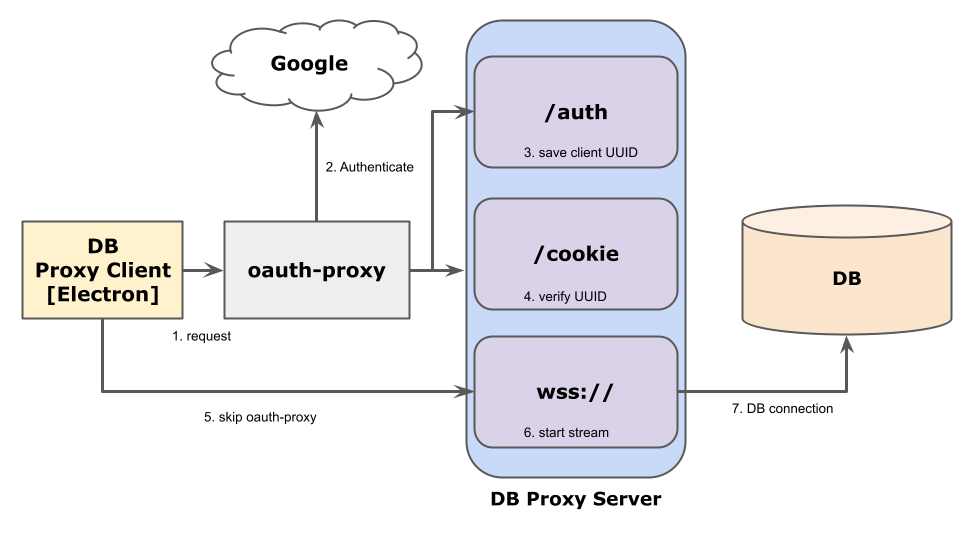
When a request is first sent to /auth, authentication/authorization is performed through oauth-proxy, and then the uuid generated on the client is saved on the DB proxy server. Next, a request is sent to /cookie, which checks to see if it matches the uuid saved by /auth. If successful, it opens a socket on wss:// and listens to the local port as a proxy to the DB. A cookie for passing Google authentication is generated during /auth by oauth-proxy, so wss:// requests are actually skipped when opening a wss socket.
At this point, we ran into the following problem when considering IAP migration:
Cookies cannot be used for authentication information to request skipping IAPThe initial endpoint (such as /auth or /cookie) can be operated on the server after passing through IAP. However, an authorization header would then be required in order to skip IAP during the wss request, and it would be impossible to implement this without making changes on the client side.
With regard to modifying clients, there were several hundred users, so I made a judgement call that it would be difficult for me to be the owner/maintainer and to notify users as well as handle updates over a period of several weeks. In addition, it would not be possible to replace services without interruption when switching the SSL certification to Google managed. It seemed difficult to resolve all the issues facing us, so we decided not to implement IAP.
But even though we weren’t able to implement IAP, we were able to learn a lot with regard to the importance of Cloud Certificate Manager,
new technologies such as building proxies using Cloud Run, Electron (which we were using with our DB proxy client), and how to structure a Google Workspace organization in order to manage permissions with IAP. This is all information we could not have touched upon using SRE alone.
With regards to db-proxy, which is a blocker in IAP migration, we can eliminate db-proxy by migrating the connection target DB (described in a previous article, "An Example of Applying DDL to MySQL DBs with Special Structures") itself to BigQuery. We are currently working on migrating "special MySQL" so that we can implement IAP.
Stateful legacy MySQL server
In the second place, I’ll discuss stateful legacy systems. They are the core Mercari MySQL DBs, which are the most problematic systems we operate.
The problem is simple. The amount of data and the buffer pool size of MySQL have continued to grow as Mercari has grown as a business. However, the DBs have reached such large sizes that it is becoming difficult to run them reliably (such as for handling incidents, vulnerabilities, and more).
If a DB becomes too large, in many cases you can split it vertically and then horizontally in order to maintain capacity and stability.
We took the same approach at Mercari in order to ensure capacity and stability.
We started with vertical splitting. We split the table by data group, but were left with several massive tables tightly coupled together. We then reached a point where we could not split it up any further.
Next we worked on horizontal splitting. This was more than the SREs could handle alone due to various factors, including significant application changes required for horizontal splitting, the difficulty of doing this while also converting to microservices, and the complex nature of determining scopes of responsibility.
Although our team does administer the actual MySQL DBs, there were many tables where converting to microservices would have made it difficult for the owner/maintainer to extract the data, and so Mercari MySQL DBs are becoming "legacy databases."
Migrating legacy MySQL server
Instead of continuing to administer these "legacy databases," we’re currently working on a project to migrate to scalable DBs that offer better scalability and higher availability.
In order to reach a decision on migrating to scalable DBs, we assigned scores to several new SQL systems (Cloud Spanner, Vitess, and TiDB) based on certain requirements and needs.
The items in question are listed below.
| Item | Details |
|---|---|
| Configuration | DBMS stability, such as the scalability of the writer and reader, and whether a failover feature is provided |
| Query | Compatibility at the application level, such as support for AUTO INCREMENT, SELECT FOR UPDATE (compatibility with MySQL is assumed) |
| Operation | Ease-of-operation, such as whether warming up is required, durability against AZ outages, and what kinds of monitoring features are available |
| Security | Ease-of-use with regard to handling vulnerabilities, such as password rotation and software updates |
| Migration | Migration performance, such as whether replication with MySQL is possible (e.g., whether MySQL binlogs can be read) |
| Connectivity to other systems | Affinity with other currently linked systems, such as CDC |
The following table compares three different systems.
| Item | Cloud Spanner | Vitess | TiDB |
|---|---|---|---|
| Configuration | Yes | Yes | Yes |
| Query | No (*1) | Conditional (*2) | Yes |
| Operation | Yes | Conditional (*3) | Conditional (*3) |
| Security | Yes | No (*4) | No (*4) |
| Migration | No (*5) | Yes | Yes |
| Connectivity to other systems | Yes (*6) | Yes (*6) | Yes (*6) |
(1) Not compatible with AUTO INCREMENT; monotonously increasing primary key not recommended
(2) Queries not supported by Vitess https://github.com/vitessio/vitess/blob/main/go/vt/vtgate/planbuilder/testdata/unsupported_cases.txt
(3) Warm-up required
(4) Does not support password rotation, IAM authentication, or audit logs (TiDB Enterprise does support audit logs)
(5) Currently cannot read MySQL binlogs without modification, and would require changes to table structure, such as interleaving
(6) Cloud Spanner can stream to BigQuery, while Vitess/TiDB can stream to Kafka
In summary, TiDB would be the most promising candidate when combined with the current Mercari operations that have a wide range support for our Migration and Query . Some examples of Mercari migration and query requirements covered by TiDB include interfaces (especially interfaces compatible with MySQL 5.7) to support the wide range of data users (such as data for microservices, monolithic PHP, and CDC), and the ability to replicate (not only from MySQL to the scalable DB, but also from the scalable DB to MySQL) and then migrate and roll back reliably.
TiDB also makes more sense than Vitess for the Mercari operations organization, as TiDB uses a cluster configuration that supports failover, supports many queries, and allows clusters to be configured in vertical units similar to the ones now configured with our DBs that have not been horizontally split.
We’re currently verifying TiDB for service implementation. I plan on discussing the results of this in a future article.
Conclusion
In this article, I discussed how we deal with some of the legacy systems we work with on a daily basis. I think any service that expands quickly will often result in black box systems and the generation of a large amount of data that needs to be dealt with.
Our team will continue to research whether these legacy systems can be replaced with open technologies or cloud services that didn’t exist when these systems were built, as we continue to maintain compatibility for current users and clarify scopes of responsibility, in order to build highly reliable systems that will make our users (and us) happy.
Are you interested in coming up with technical solutions to interesting problems? Then consider working with us!





{kind=link}