
This article is a part of Developer Productivity Engineering Camp blog series, brought to you by Harpratap (@harpratap) from the Platform Infra Team
Preface
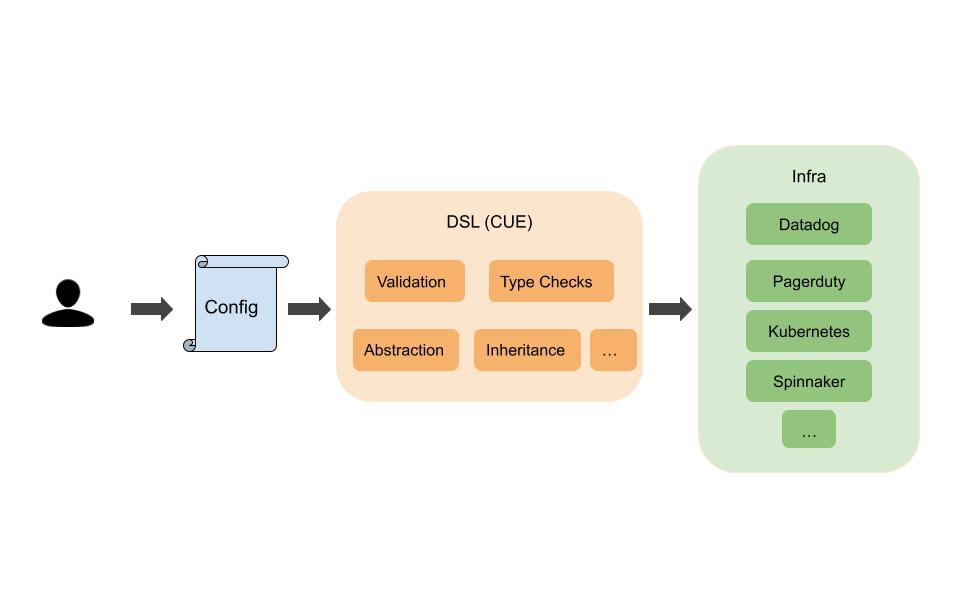
In the increasingly config driven world of infrastructure (aka Infrastructure-as-Data) the decision of which Data Configuration Language to choose is a very important one. Yaml Hell is more than just a meme, based on real frustrations people face when using such a language.
This article isn’t going to talk about the merits or philosophies of one configuration language over another. CUE was already being used in Developer Productivity Engineering Camp with great success in a project called Kubernetes Kit (k8s-kit), which was meant to reduce “Kubernetes YAML hell”. It not only covered Kubernetes specific objects such as Deployments and Services, but also our CD configurations along with some metadata about the services themselves.
Introducing Observability-kit
Parallel to k8s-kit, we had a similar initiative but for observability stack (in our case, Datadog dashboards/monitors) which used Jsonnet as the configuration language. The goal here is to provide a GitOps way to configure observability infrastructure, provide change history, ownership, sane defaults, layer of abstraction and validations where necessary, and most importantly observability into our observability stack itself – what & how our developers are using Datadog features.
We saw an opportunity to reduce the configuration languages being used for essentially the same purpose and also provide a more unified experience to our developers, so we rebased this project on CUE and hence the name observability-kit (o11y-kit from here on)
Our initial implementation focused only on Datadog Dashboard and Monitors. It allowed CRUD operations via Git and also the following features –
- Nice defaults – Sane default observability configs out-of-box
- Code reuse – Setting same configurations in both Development and Production environment with minimal changes
- Customization – Should be allowed to configure almost every part of the API
- Ease of use – Should not spend too much time learning the ropes
- Promote standardization – Encourage good practices (eg. using percentiles instead of averages)
Implementation
A bit of implementation detail is necessary to understand how we use CUE at Mercari. We have multiple repositories for managing our infrastructure configurations. These repositories have directories per microservice, then environment, region and so on.
Thanks to CUE’s Go-like module system we can implement our libraries in the root of these repositories and each microservice can simply import and use them. We implemented o11y-kit in k8s-kit repo at first (more on this later) and re-used parts of k8s-kit thus increasing re-usability and cohesion. We also make use of CUE Scripting to integrate our tooling inside our libraries.
A simple Dashboard created using o11y-kit would look like this
DefaultDashboard: kit.#Dashboard & {
metadata: Metadata
spec: widgets: {
// default widgets imported from o11y-kit
"gRPC": dashboard.GRPCGroupWidget
"Go Runtime": dashboard.GoRuntimeGroupWidget
"Kubernetes": dashboard.K8sGroupWidget
// custom widget for this microservice
“Ratings” : myCustomRatingsWidget
}
}
myCustomRatingsWidget: definition : v1.#TimeseriesWidgetDefinition & {
title: "My Receiver status"
requests: [
{
q: "(sum:datadog.trace_agent.receiver.trace{$cluster-name}.as_count()"
},
]
}Here, the first 3 Widget Groups are imported from our defaults (we provide a suite of widgets for common backends used within our company) and last one "ratings" is a custom widget for this particular microservice. Once merged, it would create a Datadog Dashboard in all of our environments.
CUE performance issues
Soon after initial implementation we noticed high export times (to the tune of hours), which is obviously unbearably slow and not worth using despite all the amazing features CUE boasts.
List Comprehensions
First one is List Comprehensions, we make use of them to convert Maps to Arrays because Maps can be appended while Arrays cannot. For example in case of Datadog Widgets this makes it easier to specify certain widgets common to all environments, some just for dev environment and some just for prod.
We noticed the slowness adds up in 2 ways –
-
Increase in the number of elements in list comprehension – The number of elements the list comprehension has to iterate through significantly added to our export time.
v: #schema & { spec: widgetMap: "1": "test" spec: widgetMap: "2": "test" }Is slower than
v: #schema & { spec: widgetMap: "1": "test" } #schema: { spec: widgetMap: [string]: string raw: widgetArray: [for w in spec.widgetMap {w}] } -
Increase in the size of definition of elements – The number of fields inside the element also increased our export time.
#Widget: { title: string type: string id: int } #schema: { spec: widgetMap: [string]: #Widget raw: widgetArray: [for w in spec.widgetMap {w}] }is slower than
#schema: { spec: widgetMap: [string]: string raw: widgetArray: [for w in spec.widgetMap {w}] }
go test -bench=BenchmarkListComprehension -benchtime=5s
goos: darwin
goarch: amd64
pkg: github.com/harpratap/cue-perf-tests
cpu: Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
BenchmarkListComprehensionLong10-16 7579 727905 ns/op
BenchmarkListComprehensionLong1-16 78135 81278 ns/op
BenchmarkListComprehensionShort10-16 71486 98007 ns/op
BenchmarkListComprehensionShort1-16 110869 55206 ns/op
PASS
ok github.com/harpratap/cue-perf-tests 33.884sWorkaround: We simply stopped using our largest list comprehension for Dashboard Widgets and use jq to convert from map to array after the export.
Open Definitions
Definitions are closed by default, if you open them it will slow down everything. Datadog provides their definition in OpenAPI format, and when you import this OpenAPI in CUE using cue import, it will make all definitions open by default.
go test -bench=BenchmarkDefinition
goos: darwin
goarch: amd64
pkg: github.com/harpratap/cue-perf-tests
cpu: Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
BenchmarkDefinitionOpen-16 1404 800391 ns/op
BenchmarkDefinitionClosed-16 1635 770721 ns/op
PASS
ok github.com/harpratap/cue-perf-tests 3.130sWorkaround: Remove open definitions and make use of embeddings to extend definitions or create a wrapper definition of your own and then convert it to the API you want.
Conjunctions
Conjunctions allow us to specify if an object should match a certain definition. Adding too many conjunctions will slow down your export time significantly.
For example widget: [...v1.#Widget] & [mywidget] is slower than widget: [mywidget]
Benchmarks
go test -bench=BenchmarkConjunction -benchtime=5s
goos: darwin
goarch: amd64
pkg: github.com/harpratap/cue-perf-tests
cpu: Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
BenchmarkConjunctionDouble-16 17859 335044 ns/op
BenchmarkConjunctionSingle-16 19837 287302 ns/op
PASS
ok github.com/harpratap/cue-perf-tests 25.784sWorkaround: Make use of conjunction at the topmost definition, everything inside the definition will always be validated anyway. For example,
MemoryUsedByFunctionWidget: #Widget & {
definition: #WidgetDefinition & {
title: "Memory used"
type: "timeseries"
request: [...#WidgetRequest] & [{
q: "sum:gcp.cloudfunctions.function.user_memory_bytes"
}]
}And
MemoryUsedByFunctionWidget: #Widget & {
definition: {
title: "Memory used"
type: "timeseries"
request: [{
q: "sum:gcp.cloudfunctions.function.user_memory_bytes.p99{$project_id} by {function_name}"
}]
}Are equivalent CUE configurations but former is slower than latter
Scripting
CUE Scripting makes heavy use of List Comprehensions and Conjunctions as explained above. So adding more functions to our _tools.cue files made it unusably slow.
Workaround: Make use of the Go API for CUE directly to write your tooling
Multiple libraries
As explained above, we have k8s-kit in our kubernetes mono-repo and initially we placed o11y-kit in same repo under same module just like another definition inside kubernetes API. But for reasons we are still not able to isolate, the export of k8s-kit slowed down considerably while o11y-kit remained fast when CUE configs were placed in same folder path.
Workaround: We placed o11y-kit in a different repo from k8s-kit. As of writing this article CUE package management is still a WIP. But as a workaround, you can manually sync files between multiple repos and import them as modules.
Defaults
One of the main objectives of o11y-kit was to provide nice default and CUE’s Defaulting feature was exactly what we wanted.
go test -bench=BenchmarkDefault -benchtime=5s
goos: darwin
goarch: amd64
pkg: github.com/harpratap/cue-perf-tests
cpu: Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
BenchmarkDefault0-16 41304 144890 ns/op
BenchmarkDefault10-16 30867 197449 ns/op
PASS
ok github.com/harpratap/cue-perf-tests 20.813sWorkaround: Fortunately for us, the scale at which we used Defaulting didn’t actually add up to a significant amount of export time. If it did, it was too little to add up to a noticeable amount our final export times.
Decision
After finding out all the bottlenecks and all possible workarounds we still had considerably higher export times compared to Jsonnet. To make our decision we decided on a budget of 5 minutes per CI run per environment. So we went ahead and found out the P90, P95, P99 and worst case scenario export times of o11y-kit with current workarounds in place.
Our P99 case of 300 Widgets per Dashboard exported in about 75 seconds and our worst case scenario of 600 Widgets per Dashboard exported in double that amount to roughly ~3 minutes which was within our budget.
Future
Adding more APIs would increase the value proposition of using our Infrastructure-as-Data offerings. So would adding multiple solutions to the mix other than just Datadog, having a single unified interface for configuration should help with migration and reduce friction of dealing with yet another configuration language.



