This post is for Day 13 of Mercari Advent Calendar 2021, brought to you by @Rakesh_kumar from the Mercari Edge AI team.
Machine learning has caught the attention of a lot of people in recent years and most of the companies today claim to be using ML models in their products. Traditionally the ML models are trained and then deployed on a cloud to serve the requests from users but the popularity of using ML models on mobile devices is also increasing.
Introduction
In Mercari, We have successfully released features on both native and web applications that use ML models on mobile devices. One such feature developed by our team uses deep neural networks on mobile devices to track items in real time over a streaming camera to show the sellability of the item in Mercari. Here essentially the application sends video frames to the ML model and the inference is done continuously.
The benefits of using ML model on mobile devices for our feature include
- Perform inference locally without the need to send video frames continuously to the cloud, which is saving on the user’s network resources, the server cost and ensuring privacy.
- low latency due to no network overhead for detecting items and hence better user experience.
- It is fun and easy to use without needing to click pictures and freely point to items around to sell.
Although there are many benefits, there are some challenges as well due to the limited computational resources like CPU, memory, energy constraints, varying device specifications and may affect the overall user experience. Some of the aspects that can affect UX are
- pre-process latency of the input data to ML model.
- Inference latency of model on mobile device.
- latency of post-processes update of the UX etc.
- Consistent experience across supported devices with variations in display size, OS and OS versions.
As a developer it’s very difficult to test the ML models to address aspects of UX for all the supported mobile devices manually. Hence we created a platform called the JetFire to automate the entire workflow and to improve the development velocity.
In this article we will mainly look into the various visualizations we created for analyzing the results of tests conducted on real devices, overview of the platform and the development workflow.
Visualizations
In this section we will discuss the simple web interface we created using React to display and analyze the results of various experiments conducted in our platform. It helps us view and manage all our experiment results in one single place. The key features of this interface are
- Compare across different models for performance metrics like accuracy, precision/recall, inference latency etc.
- Simulate different test scenarios on real devices as video to evaluate visually
Simulation of real device test scenarios
One of the features which we will look into is visualizing the results of tests on real devices on the test lab or AWS device farm through simulated video.
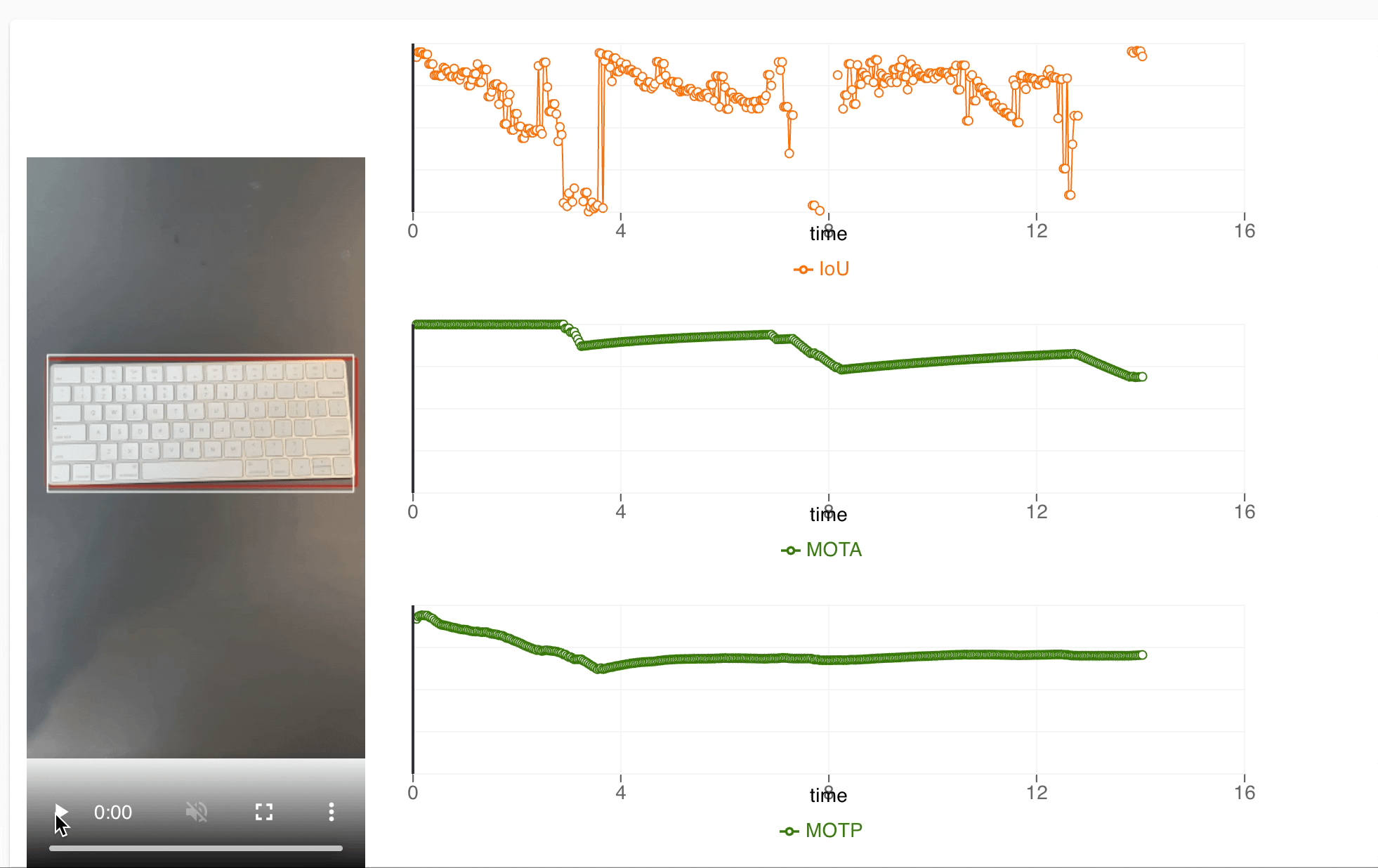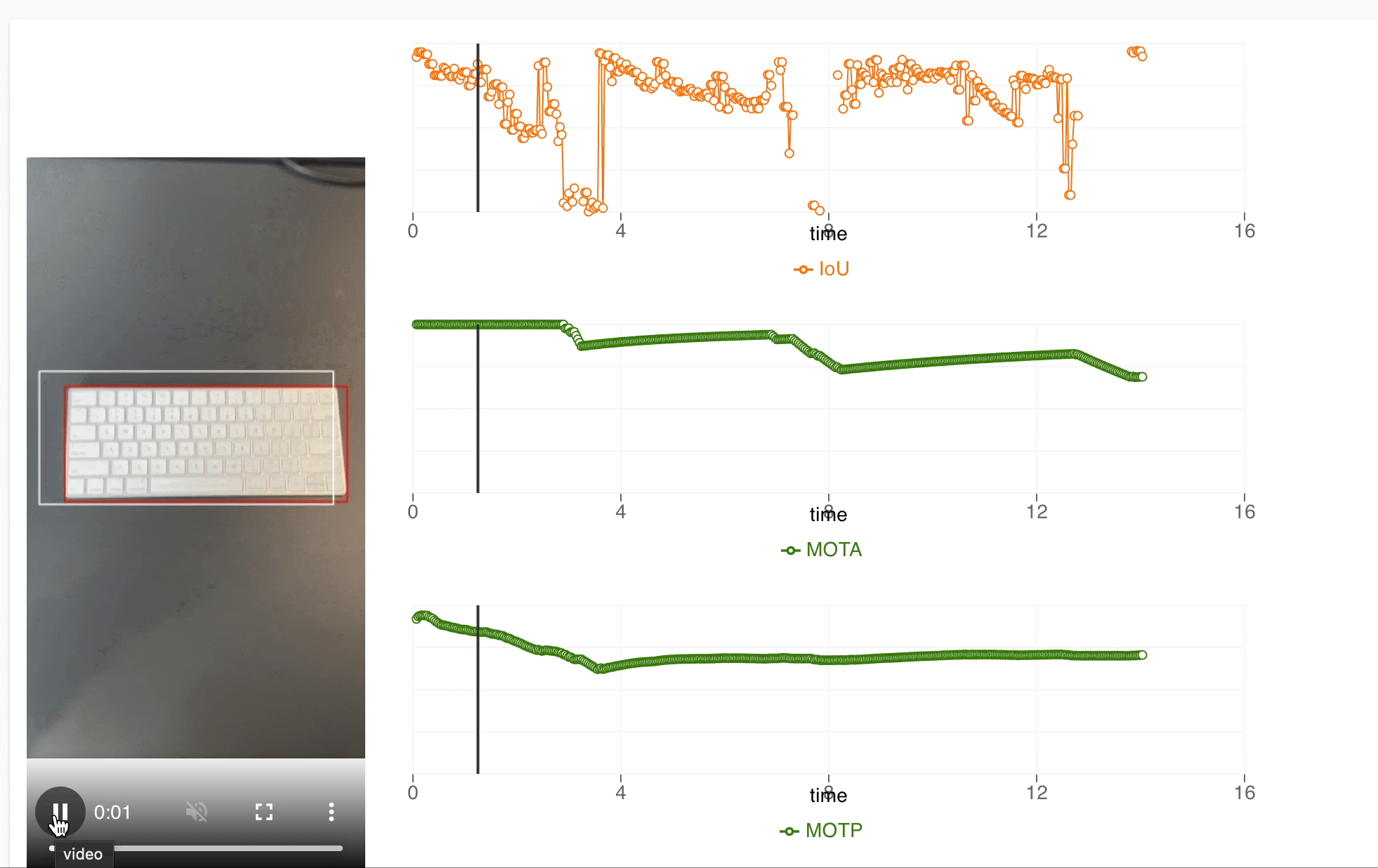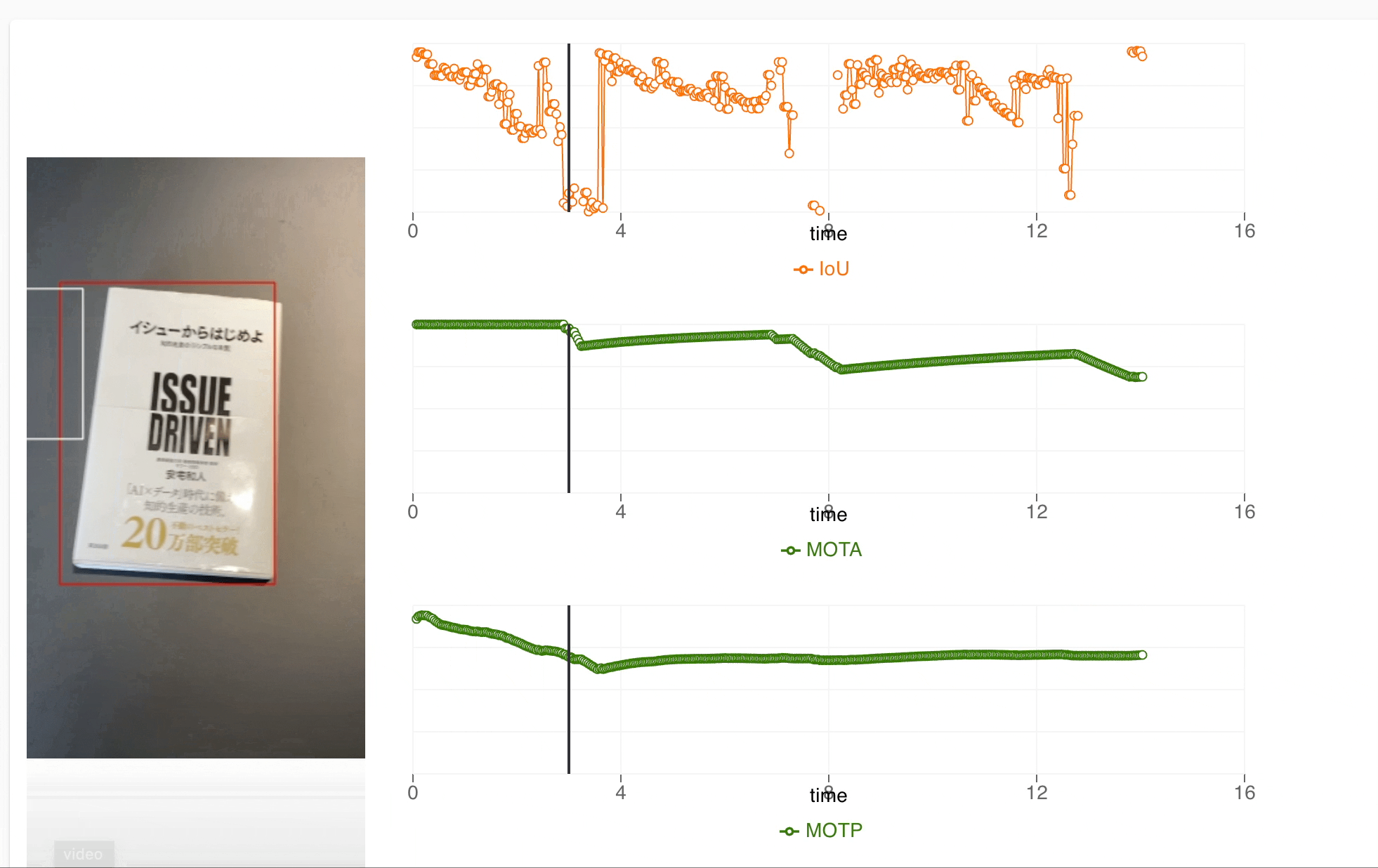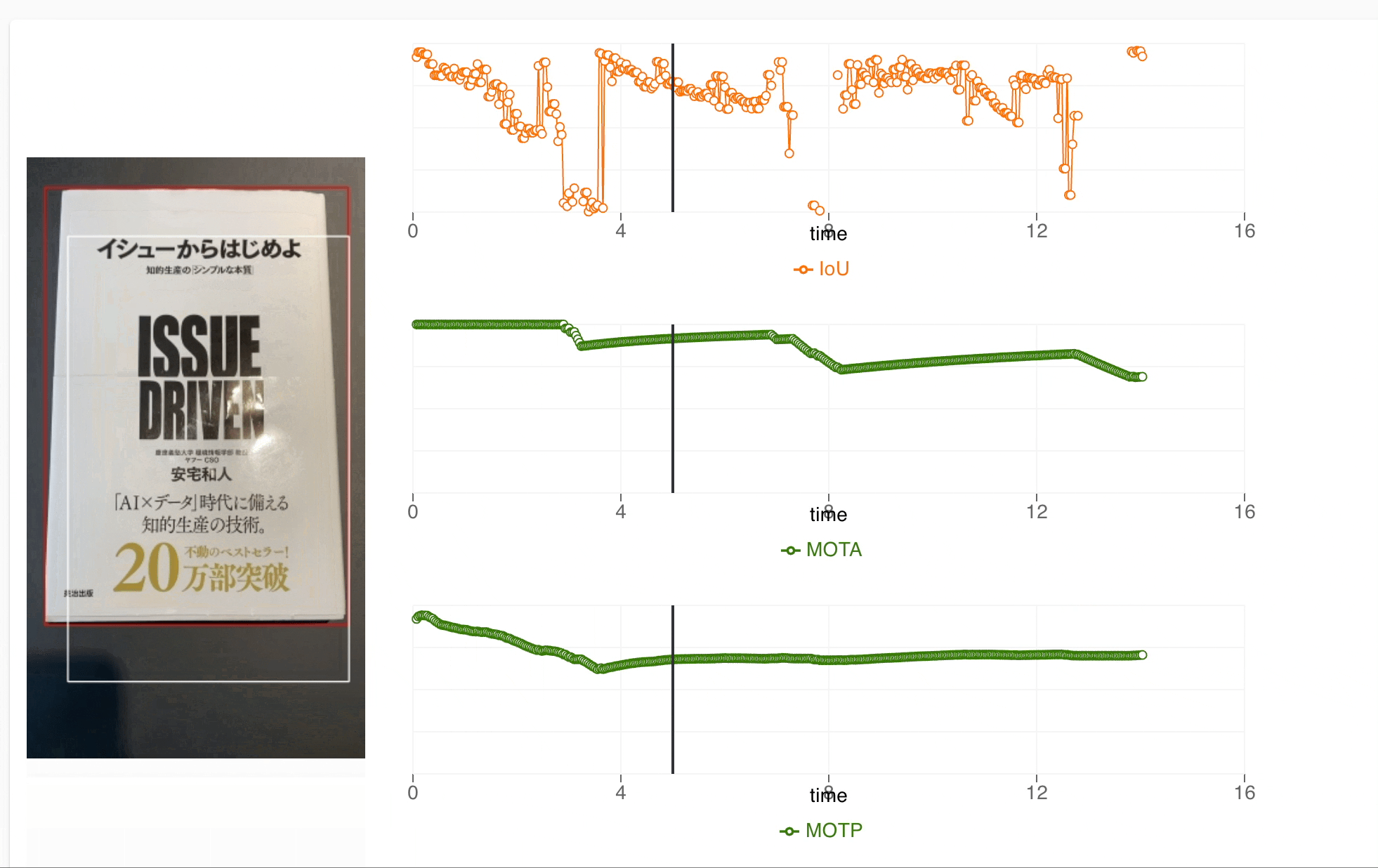
The UI consists of two sections
- Section to show simulated test video
- Metrics at different time instances of the test
The simulation video is created and metrics are calculated in the ML pipeline itself and stored to google cloud storage and metadata respectively. The red bounding box represents the ground truth of the objects in the test and white bounding box represents the performance of our model in the actual application. We also show the metrics like Intersection over Union(IoU), accuracy and precision at various instances of a test and can map it to specific instances of the test easily. This UX helps our team to check results for all devices and identify what improvements can be done during the development.
On device ML model metrics
The other feature of our Web UI is to compare performance metrics of models for a variety of device filters. We can compare the model size and precision/recall values of models for various quantizations and also compare the model inference latency across devices for filters like device type, operating system and hardware accelerators. Different devices use different types of acceleration frameworks like GPUs, XNNPACK etc which are optimized to perform ML operations. The design of the model and compatibility with these frameworks affects the on device performance of UX. Following is a sample visualization of the metrics of Mobilenet ssd model trained by our team and tested on the real devices. It compares the inference latency across various device specifications.
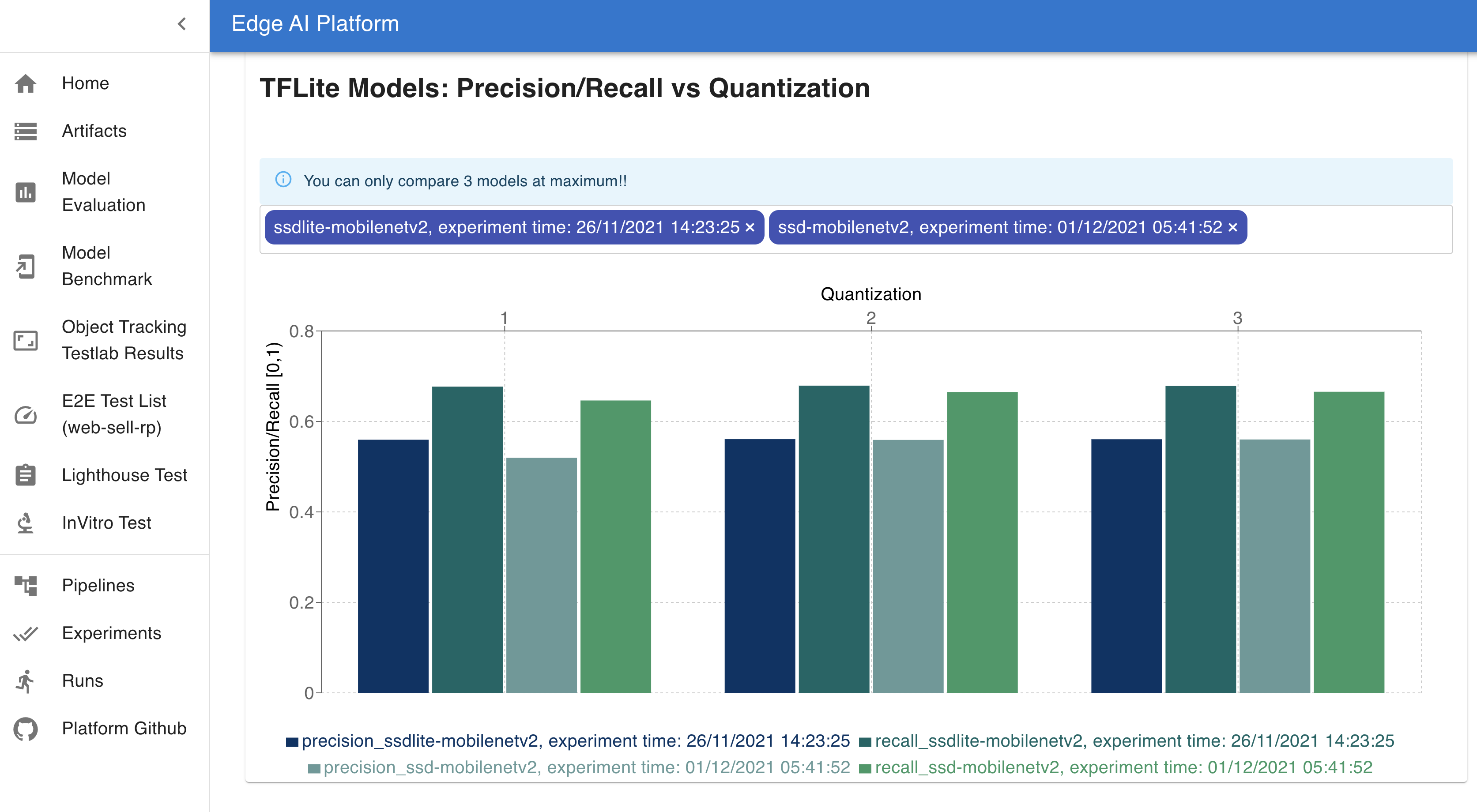
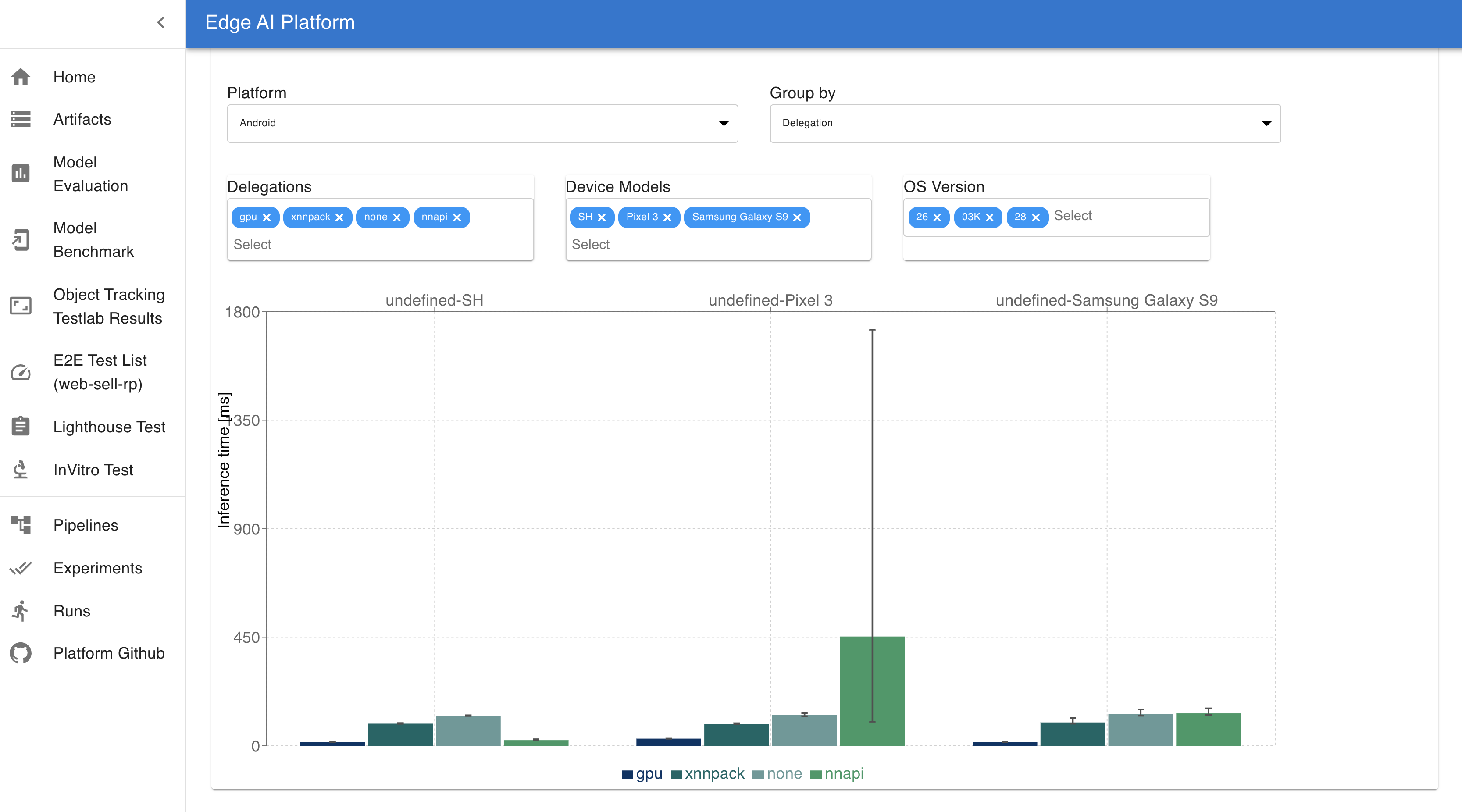
ML delegations here are the ML optimized frameworks that are provided by different devices which are used for faster calculations involved in ML model inferences. For example XNNPACK is a highly optimized library of floating-point neural network inference operators for ARM, WebAssembly, and x86 platforms. Different devices support different frameworks for optimal ML operations. In this UI, we can choose among different types of Platform, devices, OS version and ML delegations as filters to compare the inference latency of our models.
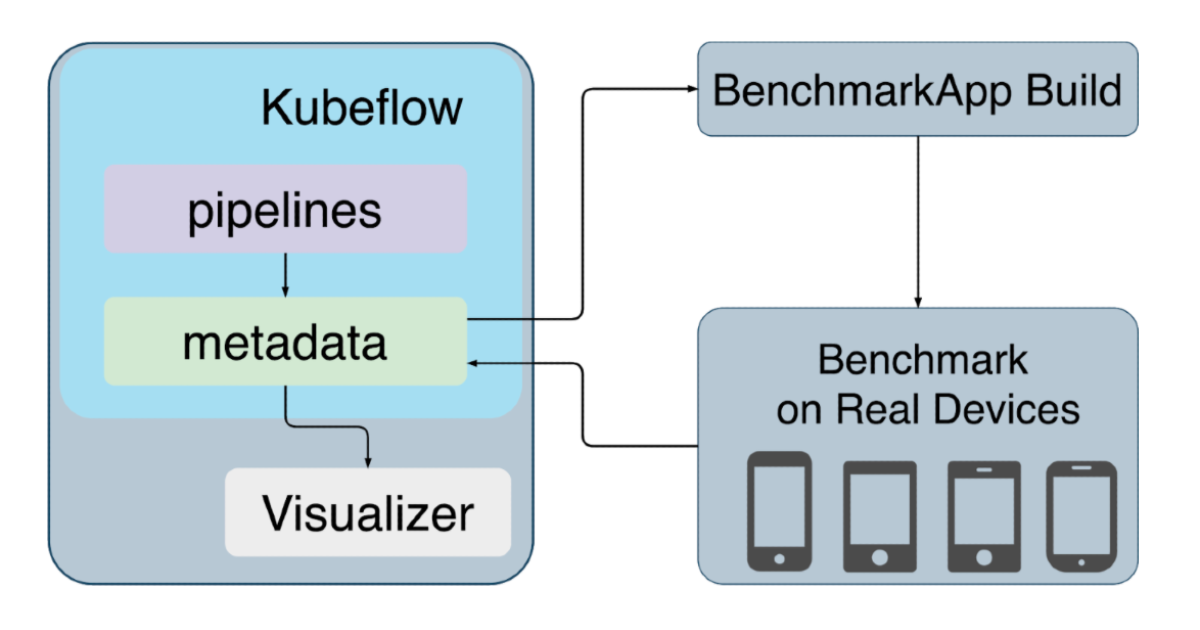
System Overview
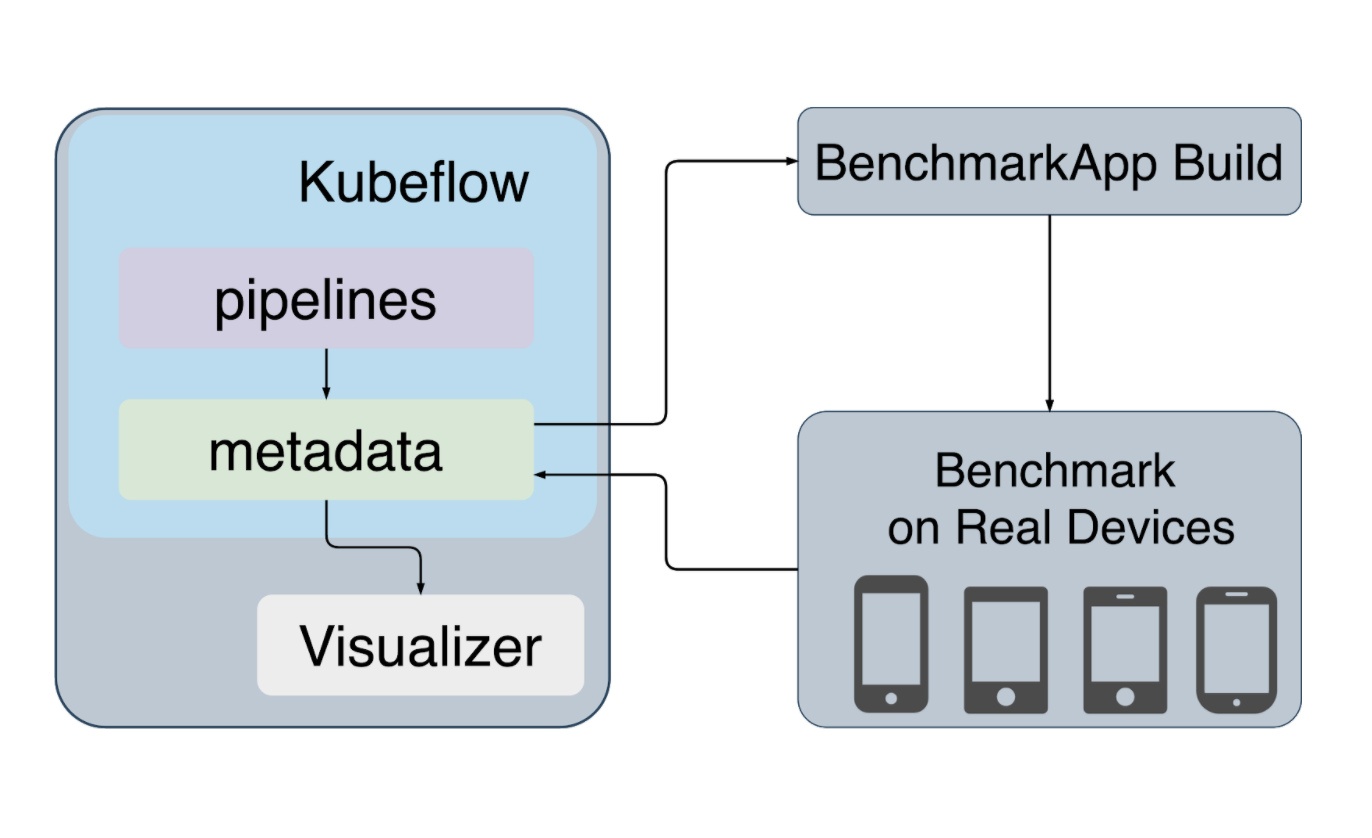
This is the higher level architecture of JetFire. The diagram represents the most important components of our platform and we will look into each of these components in brief.
Kubeflow Pipelines
ML teams in Mercari use kubeflow to create their ML pipelines. Kubeflow is an open source project to run ML workflows on kubernetes easily. We have created the entire workflow to design ML models for mobile in kubeflow and the following figure describes the various stages of the pipeline.
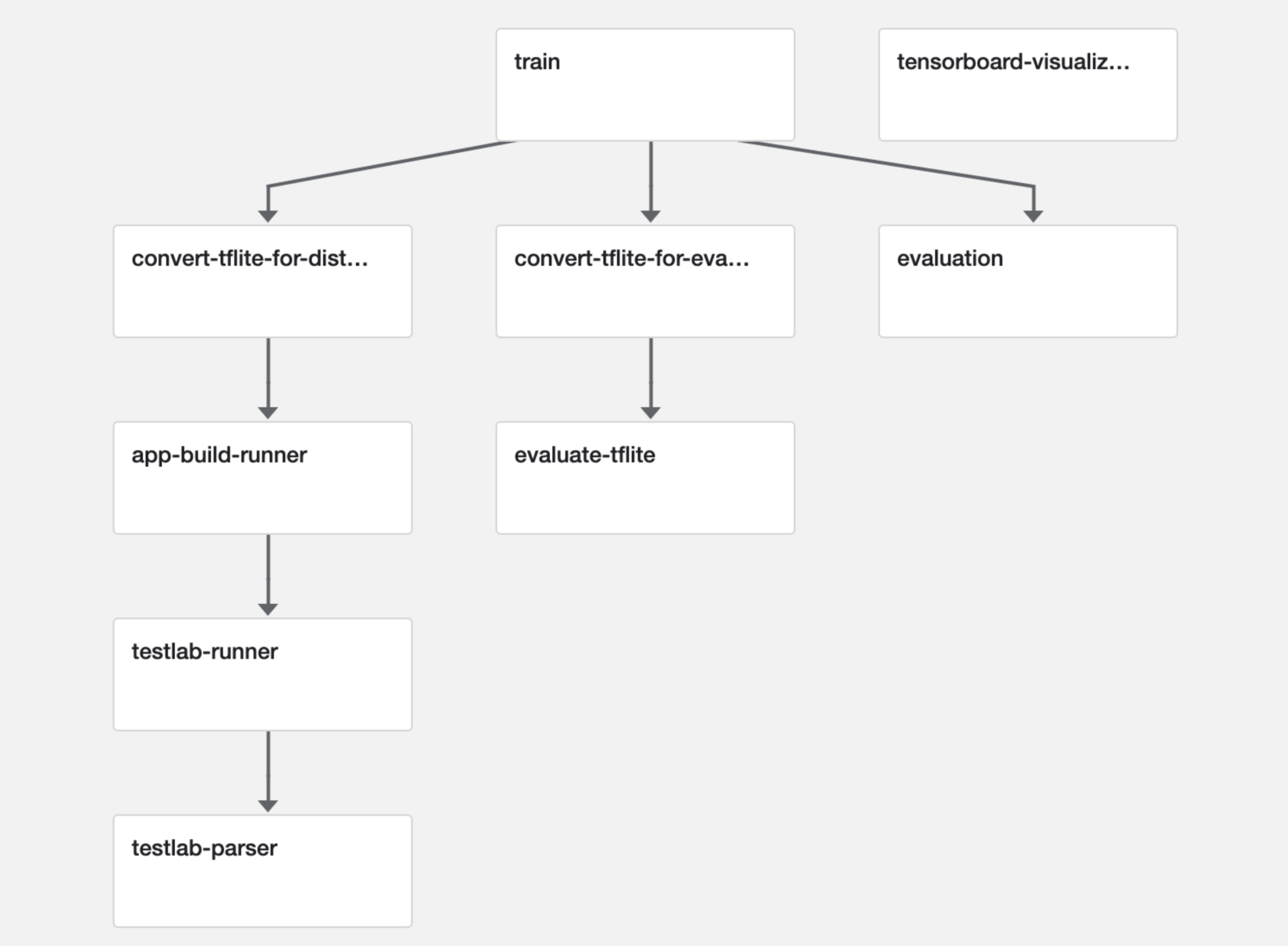
Train
This component is responsible for training our ML models. We usually use Tensorflow or PyTorch as a framework to train and create our models. The input to this component is the training dataset and the output is the trained ML model graph and weights.
Evaluation
This component is used for evaluating the performance of trained models against the test dataset for various metrics like loss, accuracy, precision, recall etc. These evaluation metrics are logged using the metadata framework provided by the kubeflow to visualize and analyze.
Convert to tflite
In order to run models created by Tensorflow or PyTorch on mobile devices, it is necessary to convert or compile the model format to support on mobile devices. TFLite format is the popular format for ML models on mobile. TensorFlow Lite and the TensorFlow Model Optimization Toolkit provide tools to minimize the complexity of the model and also reduce latency. One of the optimization techniques we follow is quantization. Quantization is the process of reducing the precision of the numbers used to represent a model’s weights, which by default are 32-bit floating point numbers and we can reduce the precision to 16-bit floating point numbers or 8-bit integer numbers.
Evaluate tflite
The performance of the actual model and the converted model vary. It’s important to test and analyze the performance of converted models to use in real devices. If the model is converted to use 8-bit integer quantization weights, there is a slight drop in accuracy with 75% reduction of model size. It’s important to evaluate all tflite conversions for such metrics, log them to kubeflow metadata for analysis and to choose the best model fit for our product feature.
App Build Runner
This component is the benchmark application builder. It is used to integrate the ML model into the iOS or Android tensorflow benchmark application and build the application automatically to distribute for testing on real devices.
TestLab Runner
This component is responsible for running the actual tests on real devices. It distributes the benchmarking application to Firebase Testlab which is a testing architecture to run on actual mobile devices hosted on google cloud datacenter. We also use AWS device farm to run our on device test which also provides a variety of mobile devices to test on. After the tests are run successfully, the logs related to test runs are saved to metadata to analyze.
TestLab Parser
This component is used for parsing the logs of on device test runs for a variety of devices and organizing them to log into metadata. This helps in building rich visualizations of performance metrics and also simulates the test scenarios with visual representations so that it’s easy to study the performance of the model.
Tensorboard
Tensorboard is a toolkit provided by the tensorflow community which is used for visualizing the tensorflow experimentation. It helps to visualize the model graph and also metrics like loss and accuracy during the training.
Metadata
Metadata component is a feature provided by kubeflow to help users manage and track metadata of their ML workflows. It uses a persistent database to store all the artifacts generated in the workflow and provides a simple kubernetes service through which different workflow components can communicate to store and read their metadata.
Workflow components can use the MLMD API to handle requests to this service and help in metadata logging. The artifacts here mean information related to training or evaluation metrics, saved model weights, train or test configurations etc. For the web UI as well, we fetch log data using the MLMD API to create different visualizations.
The metadata also helps us define data schemas for different types of artifacts that can be created in a ML workflow. These can be used across different workflows under a single kubeflow project. Our team has created a framework on top of this library to be able to easily design new data schemas for different experiments and integrate to kubeflow metadata easily. Our team extensively uses the metadata for managing the data related to all types of experiments we conduct.
Summary
Creating features using ML with on-device inference is not easy. There are a lot of factors related to designing such a model that could impact the user experience. So, it’s important for a developer to be mindful of these factors and it’s not easy to test the ML model manually for all supported device specifications.
I have explained how we leverage the features of kubeflow, metadata logging and web interfaces to build a custom platform called JetFire which makes testing ML models on device easy. I have also introduced various tools we use and types of visualizations we created that help us evaluate the performance of ML models in mobile devices. Going forward we are looking to improve the platform to integrate more insights about UX and for rich evaluation of our features.
Tomorrow’s article will be by @tettan. Look forward to it!




