
- This article is a translation of the Japanese article written on September 28, 2021.
Hello all, this is @iwata, a backend engineer at Merpay. This article is for day 18 of Merpay Tech Openness Month 2021.
All of the microservices I’ve been developing use Cloud Spanner as their data store, so I’ve been playing around with Spanner everyday. In this article, I’ll give an introduction about how to set and use the Spanner priority option to manage your workloads more efficiently.
tl;dr
- Spanner APIs allow you to specify a priority when making a request
- wrench v1.0.4 now allows you to specify a priority when executing DML
- At Merpay, we use a Spinnaker pipeline to execute DML in the production environment
Specifying a priority in Cloud Spanner
Several Cloud Spanner (“Spanner”) APIs allow you to specify a priority during a request (see Introducing Request Priorities for Cloud Spanner APIs | Google Cloud Blog). The cloud.google.com/go/spanner Go Spanner client now allows for a priority to be specified (starting with v1.17.0). For example, if using Apply(), you can use spanner.Priority() to specify the priority as the third argument (spanner.ApplyOption), as shown in the sample code below.
import (
"context"
"cloud.google.com/go/spanner"
sppb "google.golang.org/genproto/googleapis/spanner/v1"
)
func ApplyWithMedium(
ctx context.Context,
client *spanner.Client,
ms []*spanner.Mutation,
) error {
_, err := client.Apply(ctx, ms,
spanner.Priority(sppb.RequestOptions_PRIORITY_MEDIUM),
)
return err
}XxxWithOptions() methods are also provided, and these can now be used as an option to specify priority. The following sample code uses QueryWithOptions().
import (
"context"
"cloud.google.com/go/spanner"
sppb "google.golang.org/genproto/googleapis/spanner/v1"
)
func QueryWithLow(
ctx context.Context,
client *spanner.Client,
stmt spanner.Statement,
) (...) {
iter := db.QueryWithOptions(ctx, stmt, spanner.QueryOptions{
Priority: sppb.RequestOptions_PRIORITY_LOW,
})
defer iter.Stop()
...
}The default value for priority is sppb.RequestOptions_PRIORITY_UNSPECIFIED. This is equivalent to sppb.RequestOptions_PRIORITY_HIGH, and will therefore run a task at high priority if nothing is specified. The priority can be specified as either high, medium, or low. Let’s consider the kinds of situations where you might specify a different priority. The official documentation states the following.
Many data requests, such as read and executeSql, let you specify a lower priority for the request. This can be useful, for example, when you are running batch, maintenance, or analytical queries that do not have strict performance SLOs.
In other words, other priority settings would be good for running batch and analytical queries where latency is not a critical factor.
wrench –priority option
Many Merpay microservices use wrench to run DDL/DML commands for Spanner in a production environment. Up to now, there have been cases where running DML commands to manipulate a large number of records has increased Spanner latency, impacting users to some degree. For some of these operations, such as filling columns added by ALTER TABLE with default values, it is not an issue if the DML command itself takes time to execute. Rather, since these operations are not urgent, we want to run them with as little impact on high-priority workloads as possible. Therefore I decided to send a pull request that would enable the priority to be specified by wrench.
This pull request has been merged, and beginning with v1.0.4, the --priority option can now be used. The priority can be specified by using a command such as the following.
wrench apply --dml spanner-operation.sql --priority mediumDML execution using parameterized Kubernetes manifests
We use Spinnaker as our CD tool within the Mercari Group. In this section, I’ll show how to use a Spinnaker pipeline to easily execute DML using wrench. For example, we can create a form to select the priority from a menu as in the screen shown below.
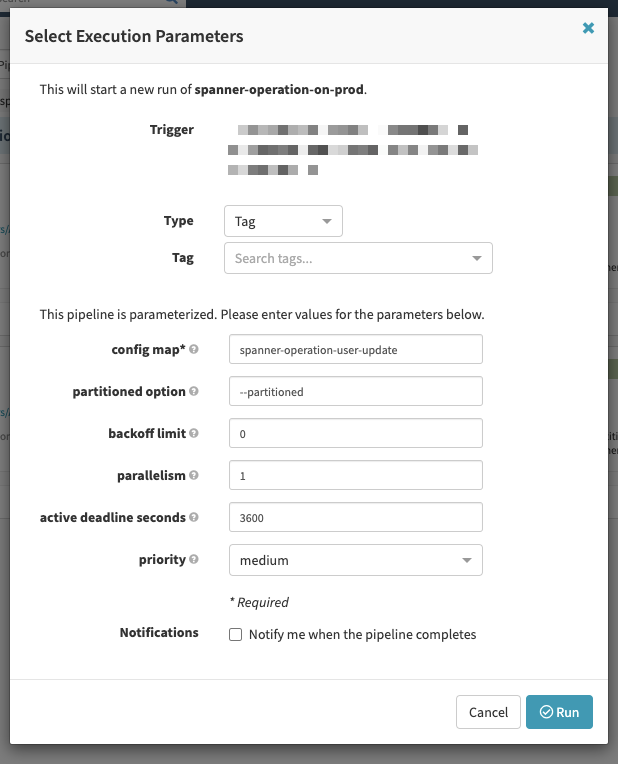
Job execution in the production environment
At Merpay, we don’t assign permissions to access Spanner in the production environment to individuals (although there are some cases where permissions are granted temporarily). We therefore need to create and execute a Kubernetes job on the production cluster. For example, we would create the following Job.
apiVersion: batch/v1
kind: Job
metadata:
annotations:
strategy.spinnaker.io/recreate: "true"
name: spanner-operation
namespace: project-xxx
spec:
ttlSecondsAfterFinished: 86400
activeDeadlineSeconds: 3600
backoffLimit: 50
completions: 1
parallelism: 1
template:
metadata:
annotations:
cluster-autoscaler.kubernetes.io/safe-to-evict: "false"
spec:
containers:
- command:
- /bin/sh
- -c
- echo "$QUERIES" > /tmp/operation.sql && wrench apply --partitioned --dml /tmp/operation.sql --priority medium
env:
- name: SPANNER_PROJECT_ID
value: project-xxx
- name: SPANNER_INSTANCE_ID
value: instance-yyy
- name: SPANNER_DATABASE_ID
value: database-zzz
- name: GOOGLE_API_GO_EXPERIMENTAL_DISABLE_DEFAULT_DEADLINE
value: "true"
- name: QUERIES
value: 'UPDATE Users SET Status="accepted" WHERE Status IS NULL;'
image: gcr.io/project-xxx/wrench
imagePullPolicy: Always
name: spanner-operation
resources:
limits:
cpu: "1"
memory: 256Mi
requests:
cpu: "1"
memory: 256Mi
restartPolicy: OnFailure
securityContext:
runAsGroup: 1001
runAsNonRoot: true
runAsUser: 1001However, other than the query to execute, not much needs to be changed, so copying and pasting this kind of Job every time we want to execute DML would be a hassle.
Parameterize Kubernetes Manifests
This is a great opportunity to use Spinnaker Parameterize Kubernetes Manifests. Parameterize Kubernetes Manifests is a feature that allows you to template manifests and embed parameters when deploying with Spinnaker.As an example, the previous Job can be converted into a template as follows.
apiVersion: batch/v1
kind: Job
metadata:
annotations:
strategy.spinnaker.io/recreate: "true"
name: spanner-operation
namespace: project-xxx
spec:
ttlSecondsAfterFinished: 86400
activeDeadlineSeconds: ${#toInt(parameters.activeDeadlineSeconds)}
backoffLimit: ${#toInt(parameters.backoffLimit)}
completions: ${#toInt(parameters.parallelism)}
parallelism: ${#toInt(parameters.parallelism)}
template:
metadata:
annotations:
cluster-autoscaler.kubernetes.io/safe-to-evict: "false"
spec:
containers:
- command:
- /bin/sh
- -c
- wrench apply ${parameters.partitioned} --dml /tmp/spanner-operation/spanner-operation.sql --priority ${parameters.priority}
env:
- name: SPANNER_PROJECT_ID
value: project-xxx
- name: SPANNER_INSTANCE_ID
value: instance-yyy
- name: SPANNER_DATABASE_ID
value: database-zzz
- name: GOOGLE_API_GO_EXPERIMENTAL_DISABLE_DEFAULT_DEADLINE
value: "true"
image: gcr.io/project-xxx/wrench
imagePullPolicy: Always
name: spanner-operation
resources:
limits:
cpu: "1"
memory: 256Mi
requests:
cpu: "1"
memory: 256Mi
volumeMounts:
- mountPath: /tmp/spanner-operation
name: spanner-operation
readOnly: true
restartPolicy: OnFailure
securityContext:
runAsGroup: 1001
runAsNonRoot: true
runAsUser: 1001
serviceAccountName: pod-default
volumes:
- configMap:
name: ${parameters.sql}
name: spanner-operationparameters.xxx will be replaced during execution. The following table lists the major defined parameters.
| Parameter name | Desc. | Example |
|---|---|---|
| sql | ConfigMap where the query to execute is written |
spanner-operation-user-update |
| priority | DML priority | medium |
| partitioned | Whether to execute using Partitioned DML (must be blank during insert) | –partitioned |
| parallelism | Job parallelism | 1 |
The priority can also be parameterized to enable it to be specified during execution. As shown in the table, the query to execute is specified using ConfigMap, so we should create the following ConfigMap separate from the above Job.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-operation-user-update
namespace: project-xxx
data:
spanner-operation.sql: |
UPDATE Users SET Status="accepted" WHERE Status IS NULL;The pipeline will be executed with this/the specified ConfigMap. By doing so, when we want to execute DML, we are now able to reuse the Job itself by creating only the ConfigMap. All that’s left is to create a pipeline on Spinnaker using this parameterized Kubernetes manifest. As shown in the screen below, parameters matching those in the template are defined in the Parmeters section.

Once the pipeline is created and Start Manual Execution is run from the menu, a modal like the one shown in the screen above is displayed. The Job can then be executed by specifying the defined parameters.
Actual example
Finally, I’ll discuss the results of updating approximately 200,000,000 records in an actual production environment. DML execution was performed using the Spinnaker pipeline discussed above. We wanted to execute DML with as little impact on user traffic as possible, even if it meant that execution would take some time to complete. It was therefore decided to take the approach of setting priority=medium and running the task late at night. We used the clone environment where data had been copied over from the production environment in advance. The same query took around just over 30 minutes to complete (approximately 120,000,000 records). We also increased the number of Spanner nodes from four to six prior to execution.
Execution environment
- Spanner nodes: 6 (
minNodes)- Using spanner-autoscaler
- DML execution mode: partitioned
- Priority: medium
Jobparallelism: 1- Time: late night
There were actually around 80,000,000 more records than in the clone environment, so execution took just under one hour.
Load during DML execution
We can infer the load on Spanner from CPU utilization during DML execution. The following link provides information on CPU utilization metrics: https://cloud.google.com/spanner/docs/cpu-utilization#metrics
There are three things we need to keep in mind with regard to these metrics.
- Not all partitioned DML processes will be executed at the specified priority
- For
CPU Utilization by operation type, only workloads set topriority=highare displayed - For
CPU Utilization by priority, workloads executed atpriority=mediumare consolidated with priority=low
These issues are still present as of writing (September 2021), and will likely be addressed by GCP in future. With this in mind, we will consider the following approach.
- Check both High/Low CPU utilization of
is_system=falseforCPU Utilization by priority - Check for differences with the same time period a week prior
- Compare with the load during the same time on the same day of the week to exclude loads other than DML as much as possible
- This is because DML was not executed during the same time period one week prior
The following graph shows the difference of gcp.spanner.instance.cpu.utilization_by_priority with that of one week prior, displayed on Datadog.

The purple line is priority=low, while the blue line is priority=high. The difference between each priority is roughly as follows.
| Priority | CPU load |
|---|---|
| High | 10-15% |
| Low | 15-25% |
If we were to execute DML at the default priority of priority=high, it seems likely that priority=low traffic would be added to the priority=high traffic. It can be inferred from this that the CPU load of 15% to 25% could be reduced to lower than that of user traffic (executed at priority=high). While this was actually executed, several of the monitors that were set triggered latency alerts, however there were no errors. Execution also completed using all six nodes without spanner-autoscaler being triggered. To be honest, it’s difficult to determine how effective this is with the current metrics. I hope GCP will make some improvements here.
Summary
In this article, I talked about making a request to specify priority in Spanner. You can now also specify priority with wrench. Give it a try if you’re interested. The best practices for executing workloads with a specified priority have not yet been established, so I’d like to take a look at some more cases. However, I will finish here for today.



