
こんにちは、メルペイでバックエンドエンジニアをやっている@iwataです。
この記事は、Merpay Tech Openness Month 2021 の18日目の記事です。
私が開発しているマイクロサービス群ではいずれもCloud Spannerをデータストアとして使用しており、日々Spannerと戯れています。
この記事ではそのCloud Spannerに対してPriorityを指定したワークロード実行について紹介したいと思います。
tl;dr
- Spanner APIはPriorityを指定してリクエストすることができる
- wrenchのv1.0.4でPriorityを指定してDMLを実行できるようになった
- メルペイではSpinnakerパイプラインを使って本番環境へのDMLを実行している
Cloud SpannerでのPriority指定
Cloud Spanner(以下Spanner)ではいくつかのAPIについてリクエスト時にPriorityを指定することができます。
Introducing Request Priorities for Cloud Spanner APIs | Google Cloud Blog
GoのSpannerクライアントであるcloud.google.com/go/spannerにおいてもv1.17.0からPriorityを指定できるようになっています。
例えばApply()を使う場合であれば以下のサンプルコードのように第3引数のspanner.ApplyOptionとしてspanner.Priority()を使うことでPriorityを指定できます。
import (
"context"
"cloud.google.com/go/spanner"
sppb "google.golang.org/genproto/googleapis/spanner/v1"
)
func ApplyWithMedium(
ctx context.Context,
client *spanner.Client,
ms []*spanner.Mutation,
) error {
_, err := client.Apply(ctx, ms,
spanner.Priority(sppb.RequestOptions_PRIORITY_MEDIUM),
)
return err
}他にもXxxWithOptions()というメソッドがそれぞれ用意されているのでオプションとしてPriorityを指定できるようになっています。
以下はQueryWithOptions()を使ったサンプルコードです。
import (
"context"
"cloud.google.com/go/spanner"
sppb "google.golang.org/genproto/googleapis/spanner/v1"
)
func QueryWithLow(
ctx context.Context,
client *spanner.Client,
stmt spanner.Statement,
) (...) {
iter := db.QueryWithOptions(ctx, stmt, spanner.QueryOptions{
Priority: sppb.RequestOptions_PRIORITY_LOW,
})
defer iter.Stop()
...
}Priorityのデフォルト値はsppb.RequestOptions_PRIORITY_UNSPECIFIEDであり、これはsppb.RequestOptions_PRIORITY_HIGHと等価なので、何も指定しなければ今まで通りHigh Priorityで実行されることになります。
PriorityはHigh、Medium、Lowが指定できます。
デフォルトはHighなのでそれ以外のPriorityはどのような時に使うとよいのでしょうか。
オフィシャルドキュメントには以下のように書かれています。
Many data requests, such as read and executeSql, let you specify a lower priority for the request. This can be useful, for example, when you are running batch, maintenance, or analytical queries that do not have strict performance SLOs.
すなわちレイテンシがクリティカルにはならないバッチ実行や分析クエリの実行などに使うのがよさそうです。
wrenchの--priorityオプション
メルペイでは多くのマイクロサービスがwrenchを使って本番環境のSpannerに対してDDL/DMLを実行しています。
これまで大量のレコードを操作するDMLを実行するとSpannerのレイテンシが悪化し、多少なりともユーザ影響が発生することがありました。
これらの操作はALTER TABLEで追加したカラムに対してデフォルト値で埋める操作などで、DMLの実行自体は時間がかかってしまってもよいものです。
逆にゆっくりでもよいから優先度の高いワークロードになるべく影響を与えず実行したい類いのものだといえます。
そこでwrenchでPriorityを指定できるようにするプルリクエストを送ることにしました。
このプルリクエストがマージされ、v1.0.4から--priorityオプションが使えるようになりました。これで以下のようなコマンドでPriorityを指定できます。
wrench apply --dml spanner-operation.sql --priority mediumParameterize Kubernetes Manifestsを使ったDMLの実行
メルカリグループでは[CDツールとしてSpinnakerを使用しています。
ここからはこのSpinnakerパイプラインを使って、wrench経由のDMLを簡単に実行する方法を紹介します。
例えば下の画像にあるようなフォームを作ってPriorityをメニューで選択させて実行することができます。
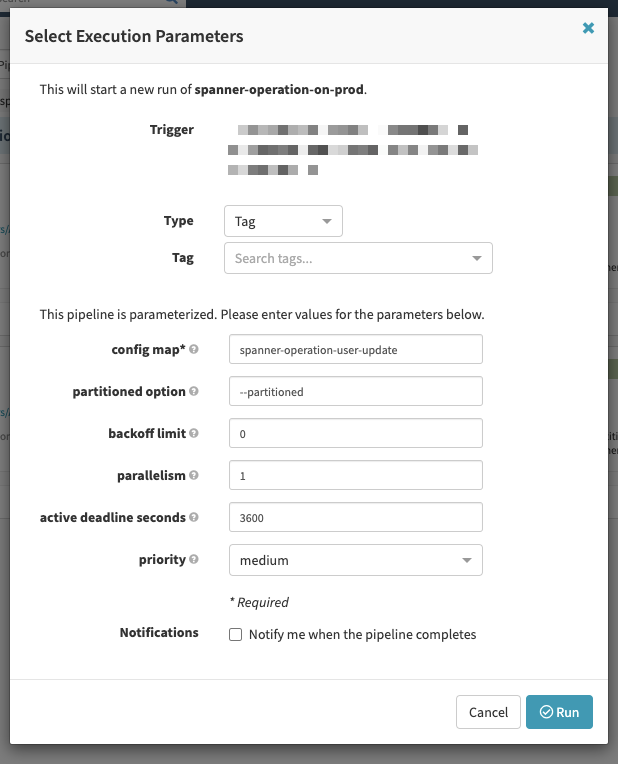
本番環境へのJob実行
メルペイでは本番環境のSpannerへのアクセス権は個人には付与されていません。
(一時的に権限を付与することはあります)
従ってDMLを実行するには、本番クラスタ上にKubernetes Jobを作成し実行する必要があります。
例えば以下のようなJobを作成することになります。
apiVersion: batch/v1
kind: Job
metadata:
annotations:
strategy.spinnaker.io/recreate: "true"
name: spanner-operation
namespace: project-xxx
spec:
ttlSecondsAfterFinished: 86400
activeDeadlineSeconds: 3600
backoffLimit: 50
completions: 1
parallelism: 1
template:
metadata:
annotations:
cluster-autoscaler.kubernetes.io/safe-to-evict: "false"
spec:
containers:
- command:
- /bin/sh
- -c
- echo "$QUERIES" > /tmp/operation.sql && wrench apply --partitioned --dml /tmp/operation.sql --priority medium
env:
- name: SPANNER_PROJECT_ID
value: project-xxx
- name: SPANNER_INSTANCE_ID
value: instance-yyy
- name: SPANNER_DATABASE_ID
value: database-zzz
- name: GOOGLE_API_GO_EXPERIMENTAL_DISABLE_DEFAULT_DEADLINE
value: "true"
- name: QUERIES
value: 'UPDATE Users SET Status="accepted" WHERE Status IS NULL;'
image: gcr.io/project-xxx/wrench
imagePullPolicy: Always
name: spanner-operation
resources:
limits:
cpu: "1"
memory: 256Mi
requests:
cpu: "1"
memory: 256Mi
restartPolicy: OnFailure
securityContext:
runAsGroup: 1001
runAsNonRoot: true
runAsUser: 1001しかしながら実行するクエリ以外はそれほど変わることはないため、DMLを実行する度にこのようなJobをコピペして実行していては面倒です。
Parameterize Kubernetes Manifests
このような時に便利なのがSpinnakerのParameterize Kubernetes Manifestsです。
Parameterize Kubernetes Manifestsはマニフェストをテンプレート化し、Spinnakerによるデプロイ時にパラメータを埋め込むことができる機能です。
例として前述のJobをテンプレート化すると以下のようにできます。
apiVersion: batch/v1
kind: Job
metadata:
annotations:
strategy.spinnaker.io/recreate: "true"
name: spanner-operation
namespace: project-xxx
spec:
ttlSecondsAfterFinished: 86400
activeDeadlineSeconds: ${#toInt(parameters.activeDeadlineSeconds)}
backoffLimit: ${#toInt(parameters.backoffLimit)}
completions: ${#toInt(parameters.parallelism)}
parallelism: ${#toInt(parameters.parallelism)}
template:
metadata:
annotations:
cluster-autoscaler.kubernetes.io/safe-to-evict: "false"
spec:
containers:
- command:
- /bin/sh
- -c
- wrench apply ${parameters.partitioned} --dml /tmp/spanner-operation/spanner-operation.sql --priority ${parameters.priority}
env:
- name: SPANNER_PROJECT_ID
value: project-xxx
- name: SPANNER_INSTANCE_ID
value: instance-yyy
- name: SPANNER_DATABASE_ID
value: database-zzz
- name: GOOGLE_API_GO_EXPERIMENTAL_DISABLE_DEFAULT_DEADLINE
value: "true"
image: gcr.io/project-xxx/wrench
imagePullPolicy: Always
name: spanner-operation
resources:
limits:
cpu: "1"
memory: 256Mi
requests:
cpu: "1"
memory: 256Mi
volumeMounts:
- mountPath: /tmp/spanner-operation
name: spanner-operation
readOnly: true
restartPolicy: OnFailure
securityContext:
runAsGroup: 1001
runAsNonRoot: true
runAsUser: 1001
serviceAccountName: pod-default
volumes:
- configMap:
name: ${parameters.sql}
name: spanner-operationparameters.xxxとなっているところが実行時に置換される部分になります。
定義した主なパラメータを以下の表にまとめました。
| Parameter name | Desc. | Example |
|---|---|---|
| sql | 実行するクエリが書かれたConfigMap |
spanner-operation-user-update |
| priority | DMLのPriority | medium |
| partitioned | Partitioned DMLで実行するかどうか(insert時には空にする必要がある) | –partitioned |
| parallelism | Jobの並列度 | 1 |
Priorityもパラメータ化して実行時に指定できるようにしてあります。
また表にあるように実行するクエリはConfigMap経由で指定するため、上記のJobとは別に以下のようなConfigMapを作成します。
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-operation-user-update
namespace: project-xxx
data:
spanner-operation.sql: |
UPDATE Users SET Status="accepted" WHERE Status IS NULL;このConfigMapを指定してSpinnakerを実行することになります。
これによりDMLを実行したい場合はConfigMapのみを作成することでJob自体は使い回すことができるようになります。
あとはこのParameterize Kubernetes Manifestsを使ったパイプラインをSpinnaker上に作成します。
以下の画像にあるようにParmetersの項目でテンプレートと合致したパラメータを定義します。

パイプラインが作成されるとメニューのStart Manual Executionから前述の画像のようなモーダルが表示され、定義したパラメータを指定してJobを実行できます。
実際の実行例
最後に本番環境で実際に約2億レコードの更新作業を実施することがあったのでその結果を紹介したいと思います。
DMLは前述のSpinnakerパイプラインを使って実行しました。
このDMLは時間がかかってでもユーザトラフィックにはなるべく影響を及ぼさないで実行完了したいものだったのでpriority=mediumでかつアクセスの少ない深夜帯に実行する方針にしました。
事前に本番環境のデータをコピーした環境で同じクエリを実行したところ約30分強(レコード数約1.2億)で完了しました。
またSpannerのノード数を事前に4から6に増やすことにしました。
実行環境
- Spannerノード数: 6(
minNodes) - DML実行モード: Partitioned
- Priority: medium
Jobの並列度: 1- 時間帯: 深夜帯
実際にはコピー環境よりも8千万ほどレコード数が多かったため、実行にかかった時間は約1時間弱でした。
DML実行時による負荷
DML実行時のCPU使用率からSpannerへの負荷を考察します。
CPU使用率に関するメトリクスについては以下のリンクから参照できます。
https://cloud.google.com/spanner/docs/cpu-utilization#metrics
メトリクスについて以下の3点について留意する必要があります。
- Partitioned DMLの全ての処理が指定したPriorityで実行されるわけではない
CPU Utilization by operation typeはpriority=highのワークロードしか表示されないCPU Utilization by priorityはpriority=mediumで実行したワークロードをpriority=lowにまとめてしまう
執筆時点(2021年9月)での問題であり、GCP側で今後対応されていくと考えられます。
これらを前提に以下の方針で考察することにします。
CPU Utilization by priorityのis_system=falseのCPU使用率をHigh/Low共に確認する- 1週間前の同時刻との差分で確認する
- DML以外の負荷をできるだけ除くため同じ曜日の同じ時間の負荷と比較する
- 1週間前の同時間帯にはDMLを実行していないため
以下のグラフはgcp.spanner.instance.cpu.utilization_by_priorityの1週間前との差分をDatadog上で表示したものです。

紫がpriority=lowで青がpriority=highのグラフになります。
Priority毎の差分のおおよそ以下ような感じです。
| Priority | CPU負荷 |
|---|---|
| High | 10-15% |
| Low | 15-25% |
仮にデフォルトのPriorityであるpriority=highでDMLを実行した場合、断言はできませんが上記のpriority=low分もpriority=highに積み上がると考えられます。
ここから15-25%のCPU負荷をユーザトラフィック(priority=highで実行される)から低減できたのではないかと推測できます。
実際に実行中は設定しているモニターのいくつかでレイテンシのアラートは鳴ったものの、エラーはゼロ件でした。
またspanner-autoscalerも発動せず、ノード数6のままで実行を終えました。
正直いま確認できるメトリクスだと効果のほどが分かりづらいので、GCP側での今後の改善に期待したいところです。
まとめ
SpannerでPriorityを指定したリクエストについて紹介しました。
wrenchでもPriorityを指定できるようになっているので、ぜひ使ってみてください。
Priorityを指定したワークロード実行のベストプラクティスは正直まだ手探り状態なので、色々と他の事例もみてみたいと思っている今日この頃です。

