
Intro
Hi, this is @prashant, from the CRE AI/ML team.
This blog post is an introductory guide to multimodal machine learning. After reading this blog, you will have an understanding of what is multimodal machine learning, the core challenges in this field, and how it is relevant to Mercari.
This blog post is adapted from the survey paper – Multimodal Machine Learning: A Survey and Taxonomy.
Let’s start with the term modality – what does it mean?
Modality and Multimodal ML
Modality refers to how something happens or is experienced.
It is often associated with the sensory modalities which represent our primary channels of communication and sensation, such as vision or touch.
In multimodal machine learning, we aim to build models that can process and relate information from multiple modalities.
Learning from multimodal sources offers the possibility of capturing correspondences between modalities and gaining an in-depth understanding of natural phenomena. Natural language (written or spoken), visual signals (images and videos), and vocal signals are the modalities that are mostly used in machine learning.
Core Challenges
The five core challenges in the field of multimodal ML are – representation, translation, alignment, fusion, and co-learning. Let’s start with the first one, representation.
Representation

task-agnostic joint representations of image content and natural language
Multimodal representation is the task of representing data from multiple modalities in the form of a vector or tensor. Since data from multiple modalities often contain both complementary and redundant information, the aim is to represent them in an efficient and meaningful way. Challenges associated with multimodal representation include dealing with different noise levels, missing data, and combining data from different modalities.
Multimodal representation can be divided into two categories: joint and coordinated.
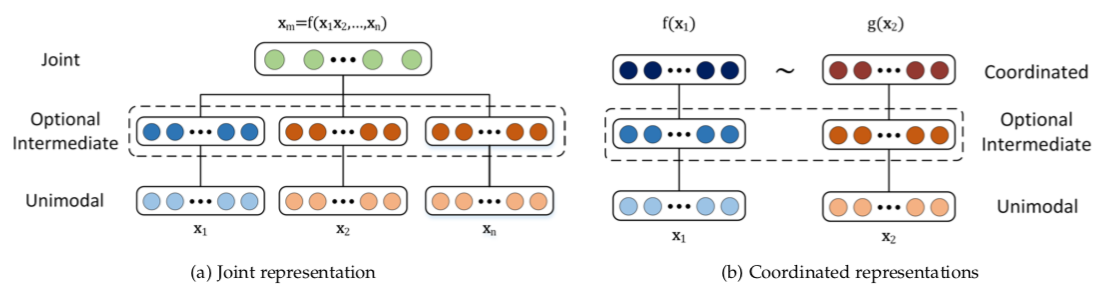
In joint representations, the data is projected from multiple modalities into a common space, and in coordinated representations, each modality is projected into a separate space but they are coordinated through a similarity (e.g. Euclidean distance) or structure constraint (e.g. partial order). For the tasks in which all of the modalities are present at the inference time, the joint representation will be more suited. On the other hand, if one of the modalities is missing, coordinated representation is well suited.
Translation
Multimodal translation addresses the challenge of translating data from one modality to another. Think of tasks like generating a description for an image like below or generating an image from a description.

A model that can generate a description for an image needs to be capable of not only understanding the visual scene but producing grammatically correct sentences describing it.
Evaluating the quality of translation is one of the major challenges in multimodal translation. Quality of results for tasks like image description, video description, speech synthesis is quite subjective and often there is no one correct translation. These challenges are overcome by conducting human evaluation but they are costly in terms of both time and money. Some alternative metrics like BLEU, ROUGE, and CIDEr are also used but they are not without issues.
Multimodal translation models can be example-based or generative.
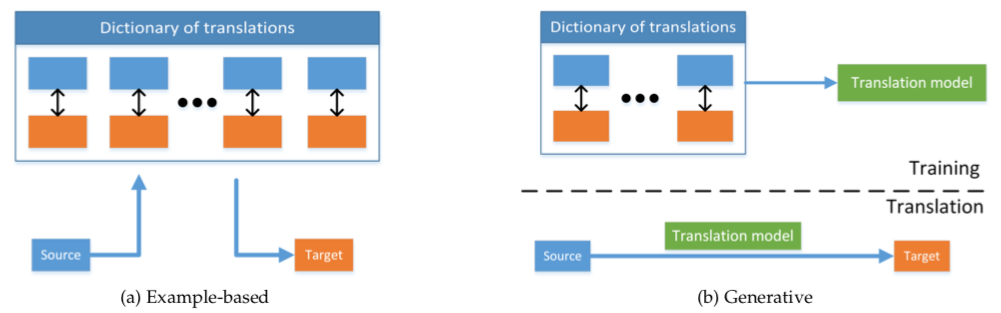
Example-based models store a dictionary that maps data from one modality to another. At the inference time, they either fetch the closest match from the dictionary or create the translation by combining several results from the dictionary based on some rules.
Since, the example-based models need to store the entire dictionary and search through them at inference time, as you can guess, it makes the model quite heavy and slow. These models also don’t provide good results if the relevant examples are not present in training data.
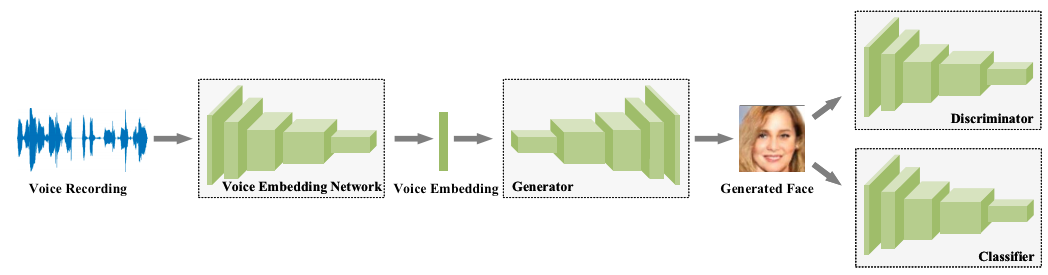
Generative models, on the other hand, can produce translations without referring to the training data at inference time. There are 3 broad categories of generative models: grammar-based, encoder-decoder, and continuous generation models but the encoder-decoder ones are the most popular right now. Encoder-decoder models are often end-to-end trained neural networks. The encoder encodes the data from the source modality into a latent representation which the decoder uses to generate the target modality. For example, check the below encoder-decoder model for generating faces from voices.
Alignment
Multimodal alignment is the task of establishing correspondence between data from two or more modalities of the same event. Given the steps to make a recipe and the video, aligning the steps to the video would be a good example of a multimodal alignment task.
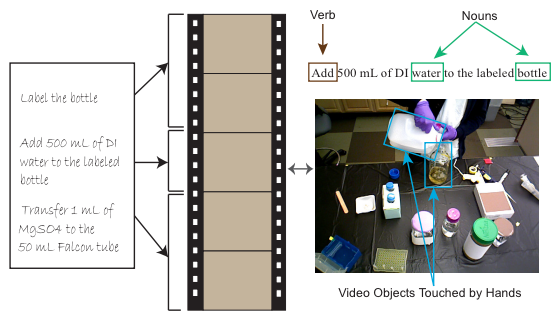
To align different modalities, a model has to measure similarities between them and has to deal with long-range dependencies. Other difficulties involved in multimodal alignment include lack of annotated datasets, designing good similarity metrics between modalities, and the existence of multiple correct alignments.
Multimodal alignment can be divided into two categories – explicit and implicit. In explicit alignment, the main objective is to align data from different modalities of the same event. Implicit alignment is a precursor to some downstream tasks like classification. For example, to perform a classification using data from multiple modalities, alignment is often required before fusion (discussed in the next section).
Fusion
Multimodal fusion is the practice of joining information from two or more modalities to perform classification or regression. Multimodal sentiment analysis is a great example of multimodal fusion where 3 modalities – acoustic, visual, and language are fused to predict the sentiment.
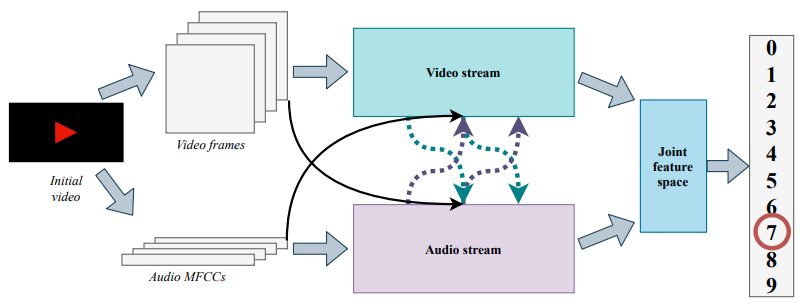
Using multiple modalities provides more robust predictions and allows us to capture complementary information. Multimodal fusion models could still be used even if one of the modalities is missing. Few more applications of multimodal fusion are in audio-visual classification, medical image analysis and multi-view classification.
Multimodal representation and fusion have become quite entwined especially for deep neural networks since learning representation is often followed by classification or regression.
There are many challenges for multimodal fusion models. Multimodal models are prone to overfitting. Different modalities generalize at different rates, so, joint training strategy isn’t always optimal. Different modalities aren’t always temporally aligned and exhibit different types and levels of noise at different points in time. Effective fusion of multiple modalities is also challenging due to the heterogeneous nature of multimodal data.
Model-agnostic and model-based approaches are two categories of multimodal fusion. Model-agnostic approaches are not directly dependent on a specific machine learning method. Model-based approaches explicitly address fusion in their construction like neural networks.
Deep neural network approaches have been very successful in data fusion due to their ability to learn from a large amount of data and end-to-end training ability. However, lack of interpretability of predictions from neural networks i.e. unsatisfactory explanation of modality or feature responsible for a particular prediction is a major challenge.
Co-learning
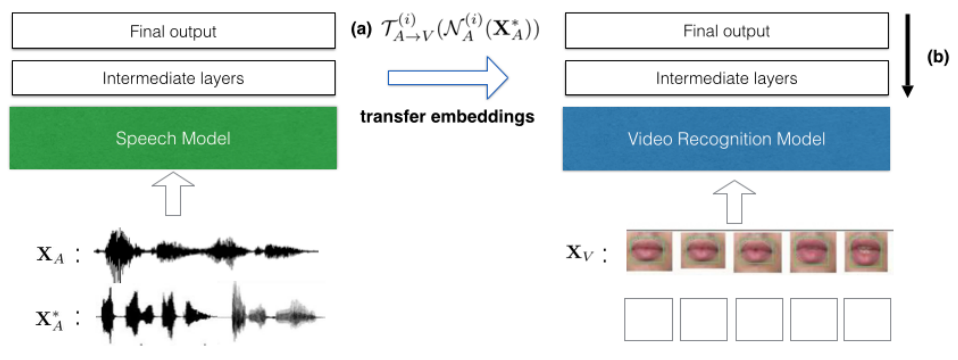
Co-learning addresses the challenge of transferring knowledge between modalities. For building a model in a modality for which resources are limited – lack of annotated data, noisy input, and unreliable labels, transferring the knowledge from a resource-rich modality are quite useful.
The 3 types of co-learning approaches based on their training resources are parallel, non-parallel, and hybrid.
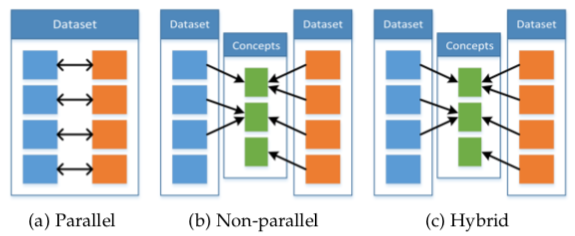
Parallel approaches require training data to have samples of the same instances in both modalities. For example, video and corresponding speech signal of a person speaking. Transfer learning has been used to create a better lip-reading model by transferring knowledge from a speech-recognition neural network.
Non-parallel data approaches do not require direct links between samples from different modalities. Action recognition has been improved by providing additional modality – 3D human-skeleton sequences – in training data.
In the hybrid approach, the modalities are bridged through a shared modality or a dataset. For example, given a parallel dataset of images and their English captions and a parallel dataset of English and French documents, a model could be built to retrieve an image from a French caption.
After getting familiar with all 5 core challenges, let’s take a look at how multimodal ML is used in Mercari.
Multimodal ML at Mercari
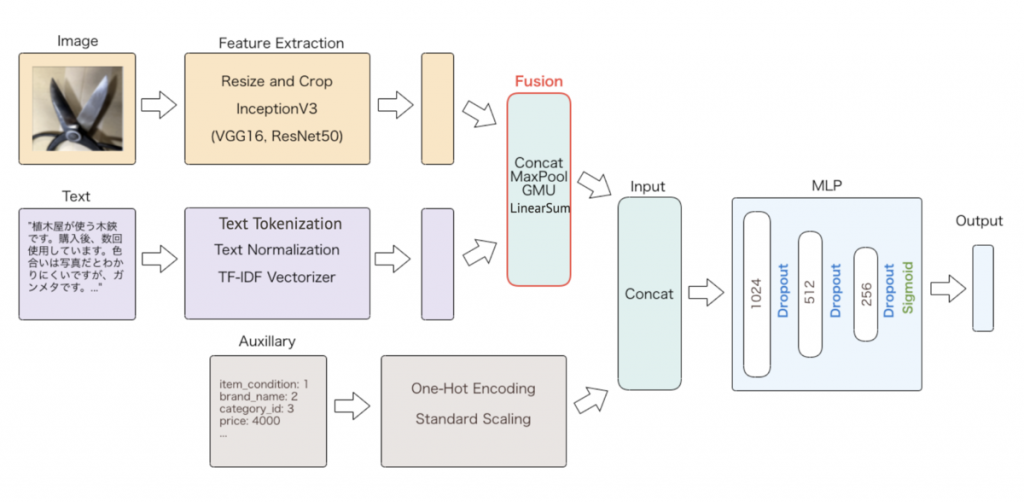
Mercari has been using multimodal models for content moderation for a long time. Last year, a paper about our moderation system, Auto Content Moderation in C2C e-Commerce, was published at OpML 2020 conference. You should also check out these blog posts about our moderation system – Multimodal Information Fusion for Prohibited Items Detection and Using neural architecture search to automate multimodal modeling for prohibited item detection. Using multiple modalities has been very important to us to build better models for detecting listings that violate our terms of service. Building better models in this case directly leads to a better customer experience.
Mercari US app uses an item’s image, title, description, category, brand, and condition to provide real-time smart pricing feature to sellers.
We have large datasets spanning multiple modalities – image, text, and categorical data from our marketplace. You are welcome to join us to build exciting features and enhance the experience of our users using these datasets.
Conclusion
In conclusion, modality refers to how something is experienced. Multimodal models can process and relate information from multiple modalities. Multimodal models allow us to capture correspondences between modalities and to extract complementary information from modalities. 5 core challenges in multimodal machine learning are representation, translation, alignment, fusion, and co-learning.
Multimodal ML is one of the key areas of research in machine learning. Check awesome-multimodal-ml GitHub repo for a deep dive into this topic.




