Introduction
Hello, I’m Suganprabu, a software engineer in the AI team at Mercari. I work on Content Moderation using Machine Learning. In this article, I would like to share one of the issues we had with our system’s design and the approach behind choosing a solution to the issue. Since the solutions are generic, they could be extended to any system following the same design.
Overview of system architecture
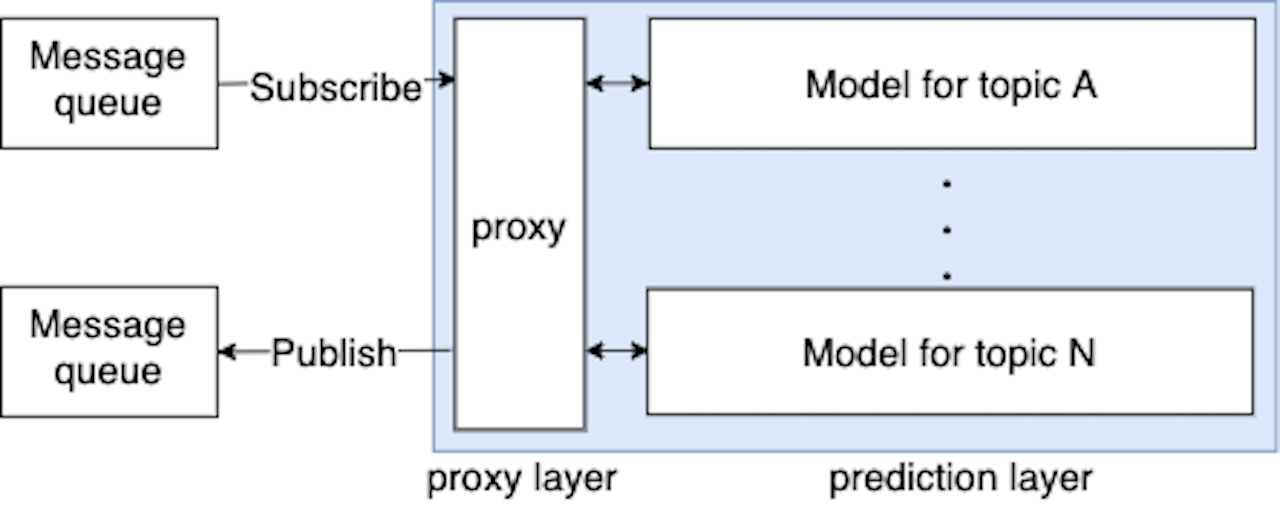
Mercari has several violation topics based on our marketplace policy, such as weapons, money and counterfeit items . A universal model for all the violation topics is difficult from a maintenance perspective as it’s not possible to improve the performance on each topic separately. So the system consists of several Machine Learning models, each handling a different violation topic. It follows the queue-based load leveling pattern using Google Cloud Pub/Sub as the message queue between the various tasks. Here, the tasks are Pub/Sub events related to items such as newly listed items, updated item details etc. The service is the set of all models, along with another layer we call proxy. The proxy layer is responsible for distributing the requests to the models based on business logic and aggregating the results. It’s also responsible for fetching any additional data from other microservices that is required by any of the models. The proxy layer picks up messages from the message queue and makes gRPC requests to each model which responds with its prediction, which is just the probability of that particular item violating the topic handled by that model. The proxy layer is required because it prevents duplicating business logic shared by the models and not available in the messages in the message queue.
Issues with the system architecture
At a high level, the behavior of the system is asynchronous communication followed by synchronous communication. The proxy layer asynchronously receives the messages from the downstream microservice (which is the microservice handling the items) and makes several synchronous requests to upstream microservices (the set of all models). Since asynchronous communication is based on acknowledgement of messages, proxy waits for the responses from all the models before acknowledging messages. During stable system operation, all the models respond successfully within the request deadline so proxy acknowledges messages smoothly. However, consider the case when some model experiences downtime. It could just be having elevated latencies for some time, or it could be returning errors. Proxy can not acknowledge the message until all the models respond successfully and neither should it hold onto the message. Since this is equivalent to a failed processing of the message, it has to be nacked so that Pub/Sub can send the message again later based on the retry configuration. An occasional error or a brief downtime from one model should be tolerable and must be expected due to the nature of microservices, but if the situation prolongs, all the other models end up with downtime either due to sudden high load due to the retrying or due to increased latencies to receive new messages. Of course, we could have circuit breakers or server concurrent requests limits that will avoid downtime due to high load, but this results in increased latencies to receive new messages. If we consider each model as a separate microservice, this is an example of cascading failures.
Possible solutions
The issue explained above can be broken down into two smaller issues. The first is the cascading of the failure which is caused due to the fact that the models repeatedly receive the requests which they already responded successfully. The second is the message queue getting clogged due to several retries, slowing down the subscription process and receiving newer messages added to the queue. Any useful solution needs to address both these issues. In this section, I will share some of the solutions that we considered and the results of testing them by simulating incidents in our development environment.
Cache for predictions from models
The first approach we tried was caching predictions from models for each message. This way, for every message, the proxy just checks the cache in addition to the business logic to decide whether or not to request a particular model. The cache need not be a critical dependency since its purpose is just to help during incidents. Since caches are designed for low latency applications, they add negligible overhead to the system during normal operation. Cache can be implemented in two ways, internal and external. Internal cache could be inside the proxy’s memory, or since our service runs in Kubernetes, it could be a sidecar. External cache is outside the application and in Google Cloud Platform, we have Google Cloud Memorystore.
Internal cache
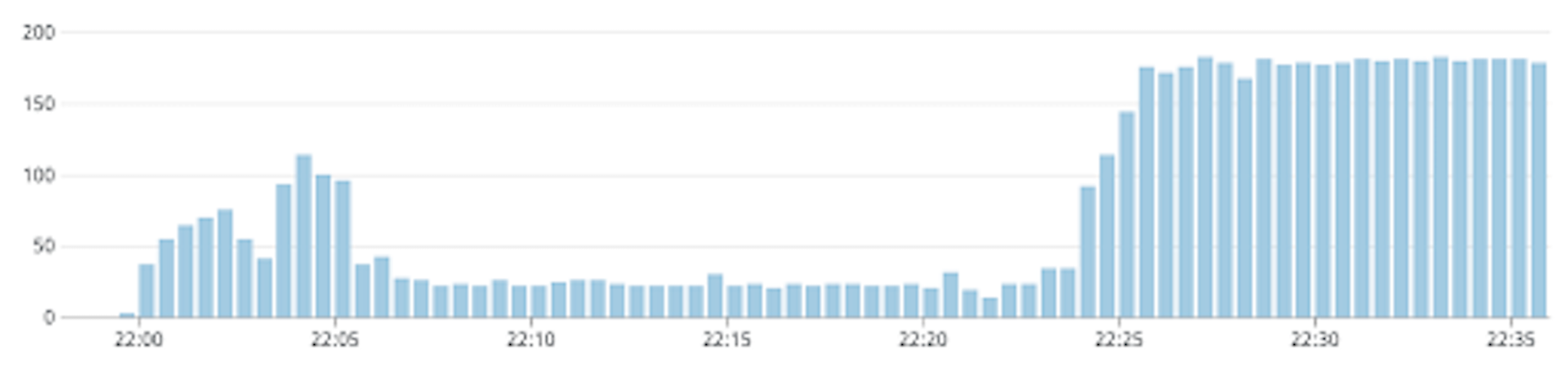
The behavior of internal cache for our use-case should be similar for both in-memory cache and sidecar cache, so I will collectively call them as internal cache in this section. In Kubernetes, applications are run as self-contained replicas which do not share memory. So the responses cached by one replica can not be accessed by the others. The messages in the message queue do not necessarily get delivered to the same replica, so cache miss rate needs to be tested. An approximation of the probability of cache hit of a message would be min(1, delivery_attempt / num_proxy_replicas). Since message delivery is random and since replicas are similar, higher order denominators can be eliminated. For the first delivery attempt, none of the replicas has the predictions in the cache, so the probability is 0. Over time, each proxy replica caches the predictions and the probability reaches 1. In reality, however, since there are newer messages entering the message queue, and we have retry configuration in the message queue with a minimum and maximum backoff, the behavior of the load itself is quite different. Below are the simulations of incidents at different num_proxy_replicas. In each case, the first graph is the load received at proxy, and the second graph is the load handled by a model under normal operation. Note that the replicas of the proxy deployment were fixed, whereas the model was allowed to autoscale during each of these experiments. Also messages were added to the queue at a constant rate of 5 per second. The vertical axis corresponds to the rps and the horizontal axis corresponds to time.
With 1 proxy replica
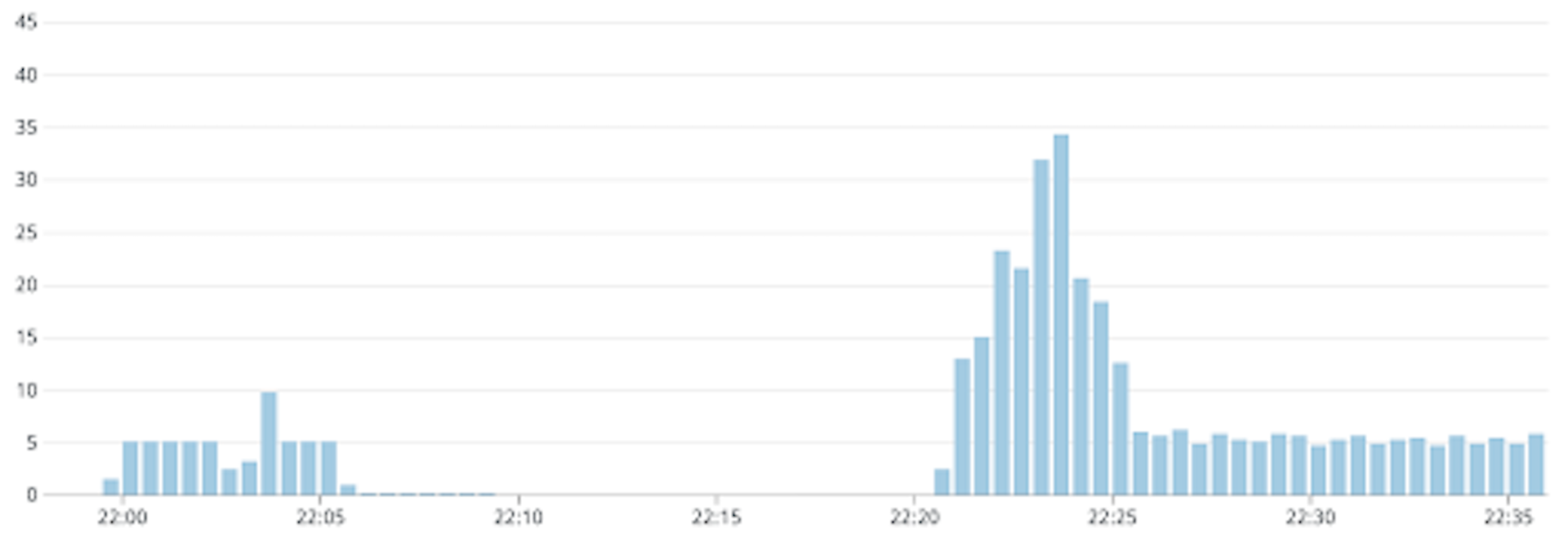
With 2 proxy replicas
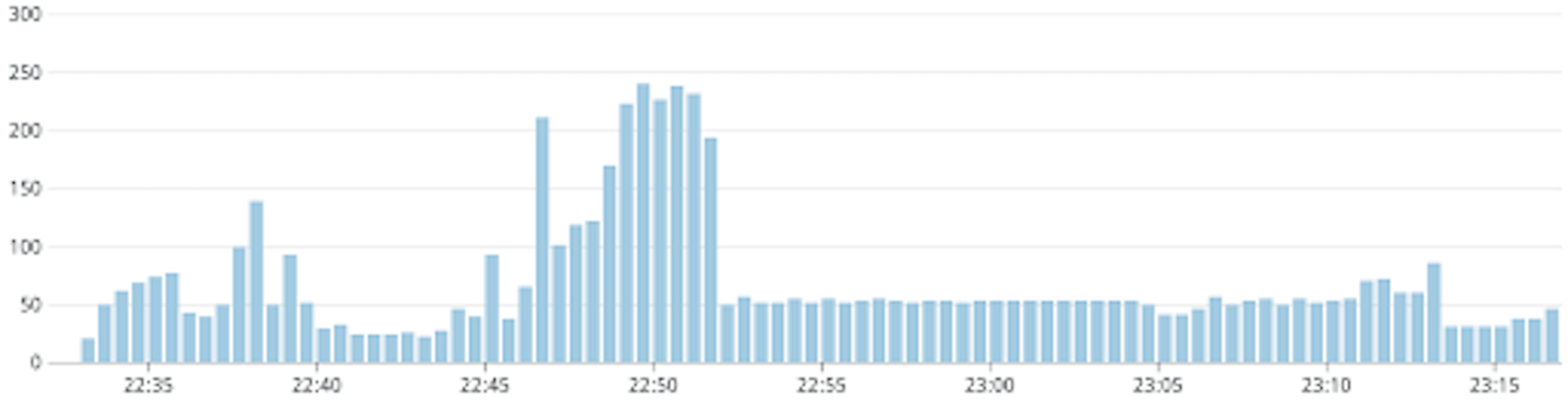
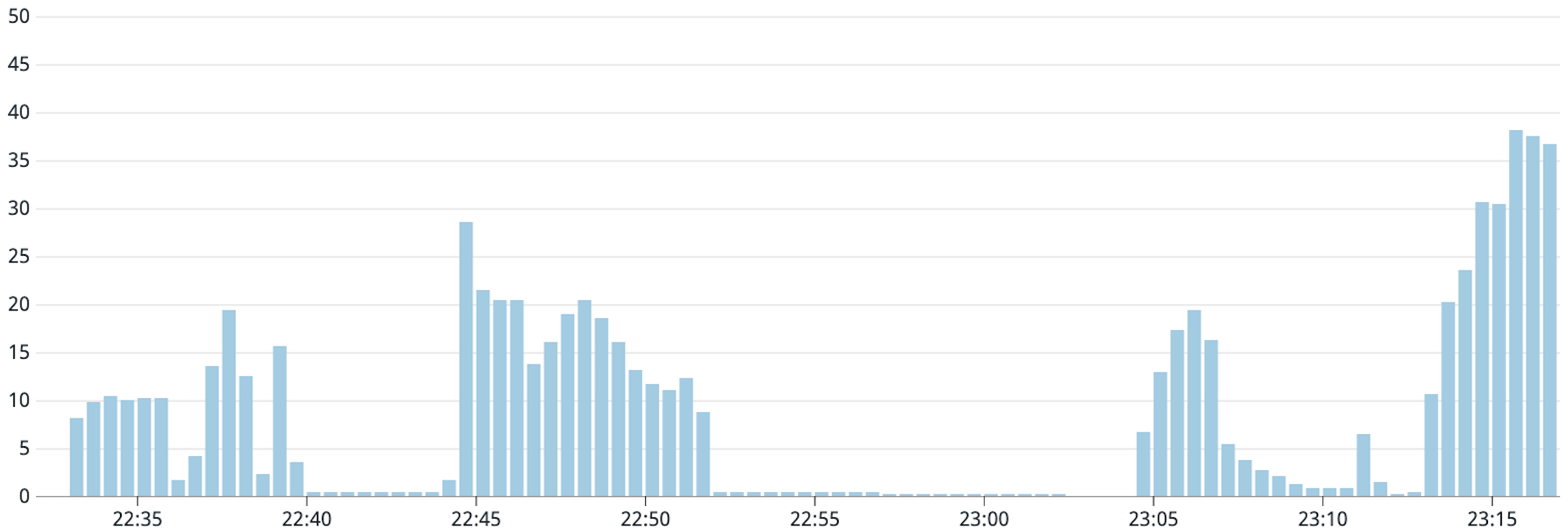
With 3 proxy replicas
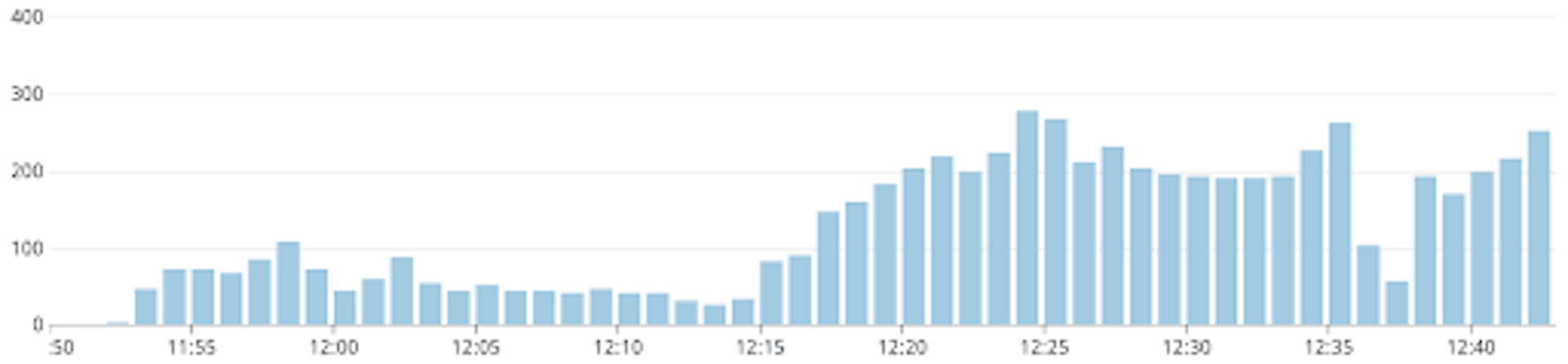
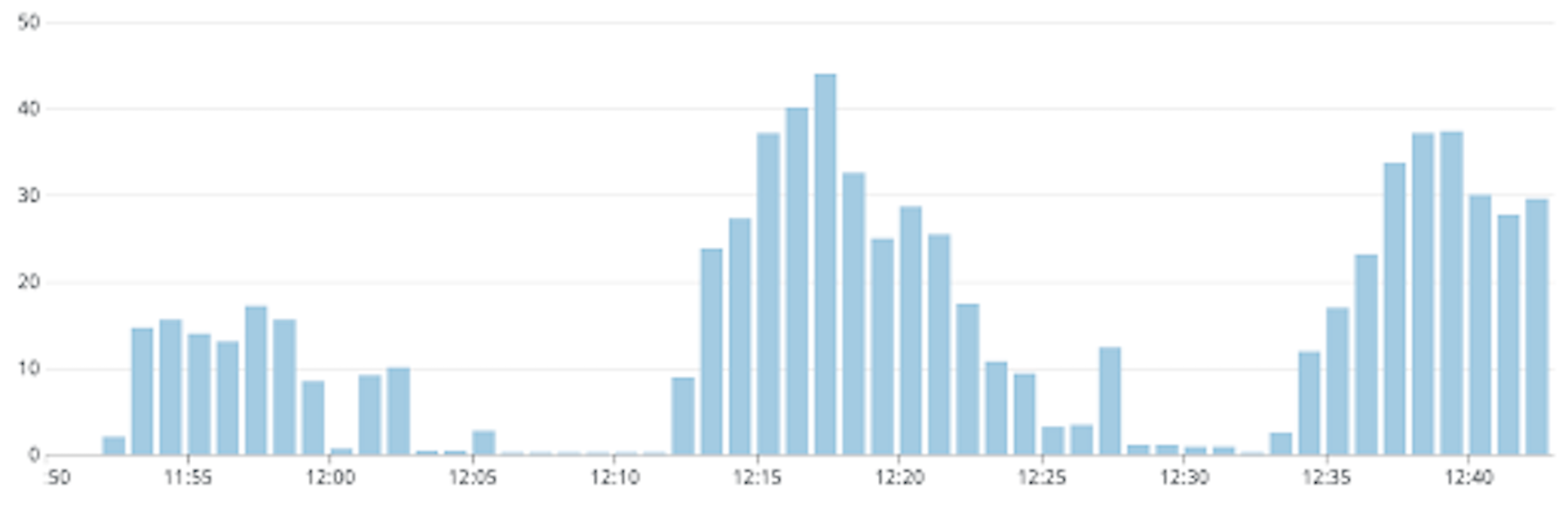
As can be seen from the graphs, the load on the model is not really reduced with higher proxy replicas. The ideal situation is when the load on the model never crosses 5 requests per second. From the graphs, we can see that we approach this situation by reducing the proxy replicas, and this strategy of caching messages is ineffective with a replica count greater than 3. With 1 proxy replica, the load is 5 requests per second for some time, then almost 0 for some time and there is a brief spike which settles down to 5 requests per second again. The duration when the load is 0 is when the cache hit rate was almost 100% and then due to the message retry configuration, there was a burst of new messages that were handled suddenly which resulted in the spike, since they would have all missed the cache. The disadvantage of fixing proxy replicas to a lower value is that it reduces the system’s availability and removes the benefits of autoscaling. Also, if there happened to be some bug in the proxy replica which caused the incident, it would get restarted and the memory would get flushed. In such cases, the internal cache becomes useless.
External cache
External cache gives the same performance as the case where the proxy with 1 replica had an internal cache. It eliminates all the disadvantages with running 1 proxy replica that are mentioned above. External cache is extremely cheap so it doesn’t increase the system cost while at the same time gives the benefits of the 1 proxy replica case. External cache can however, only solve the failure cascading issue. This is the reason why there are periods of almost 0 load on the model. In such periods, all the messages that are processed are the ones that were already processed due to which cache hit rate is almost 100%. But messages are still added to the message queue by the downstream service and handling of these messages is still significantly delayed. Below is a flow diagram of the external cache approach.

Internal message queues
The issues explained above originate from the fact that we have asynchronous communication followed by synchronous communication and acknowledgement of the asynchronous communication. One idea would be to make the synchronous communication asynchronous so that proxy does not have to wait for responses from each model. It could just pick up messages from the queue, create a new message for each model and put them into separate queues for each model. Then each model could asynchronously respond back to proxy through another queue. This would make the communication completely asynchronous without affecting the original message queue. Although this approach seems to solve the problem (because the problem ceases to exist), there are some disadvantages of this approach. The major disadvantage being the development overhead in converting from synchronous communication from proxy to the models to asynchronous. And if we were to provide some internal endpoint in the future so that other services can call us directly due to business requirements, the whole development would have to be reverted. Another issue is that some additional information which proxy retrieves for the model, such as images, would have to be retrieved by the models instead, since we can’t send them through message queues due to server limits. This information retrieval is IO-bound whereas the models are CPU-bound, and these 2 tasks don’t go well together considering scalability. So we should have a front server for each model that does all the IO-bound work. This would result in additional maintenance overhead, which we had just finished removing. Below is a flow diagram of the internal message queues approach.
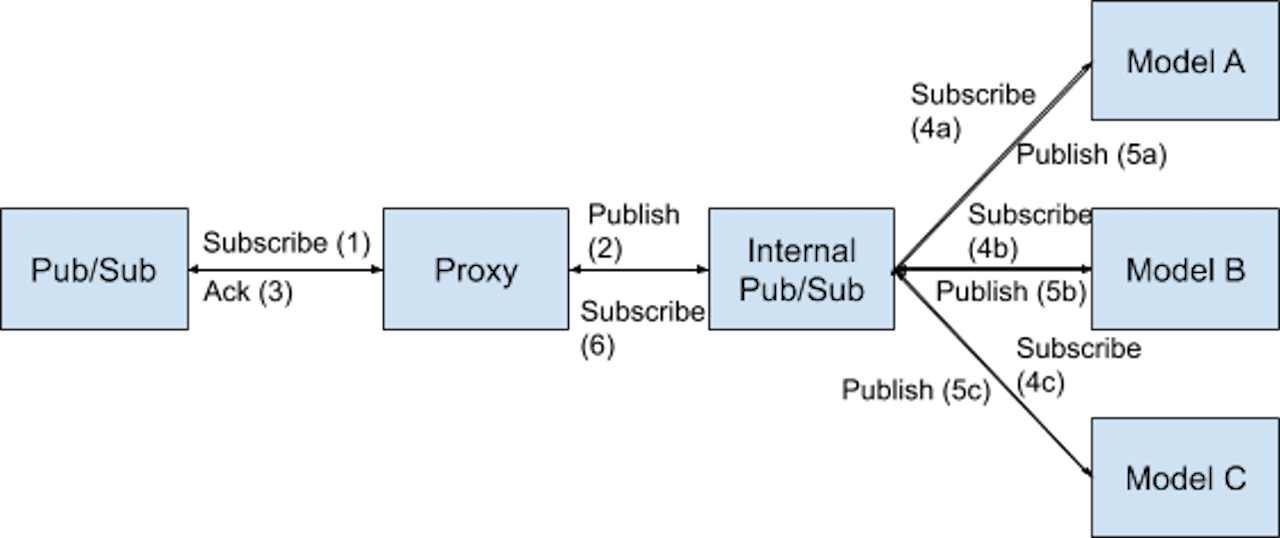
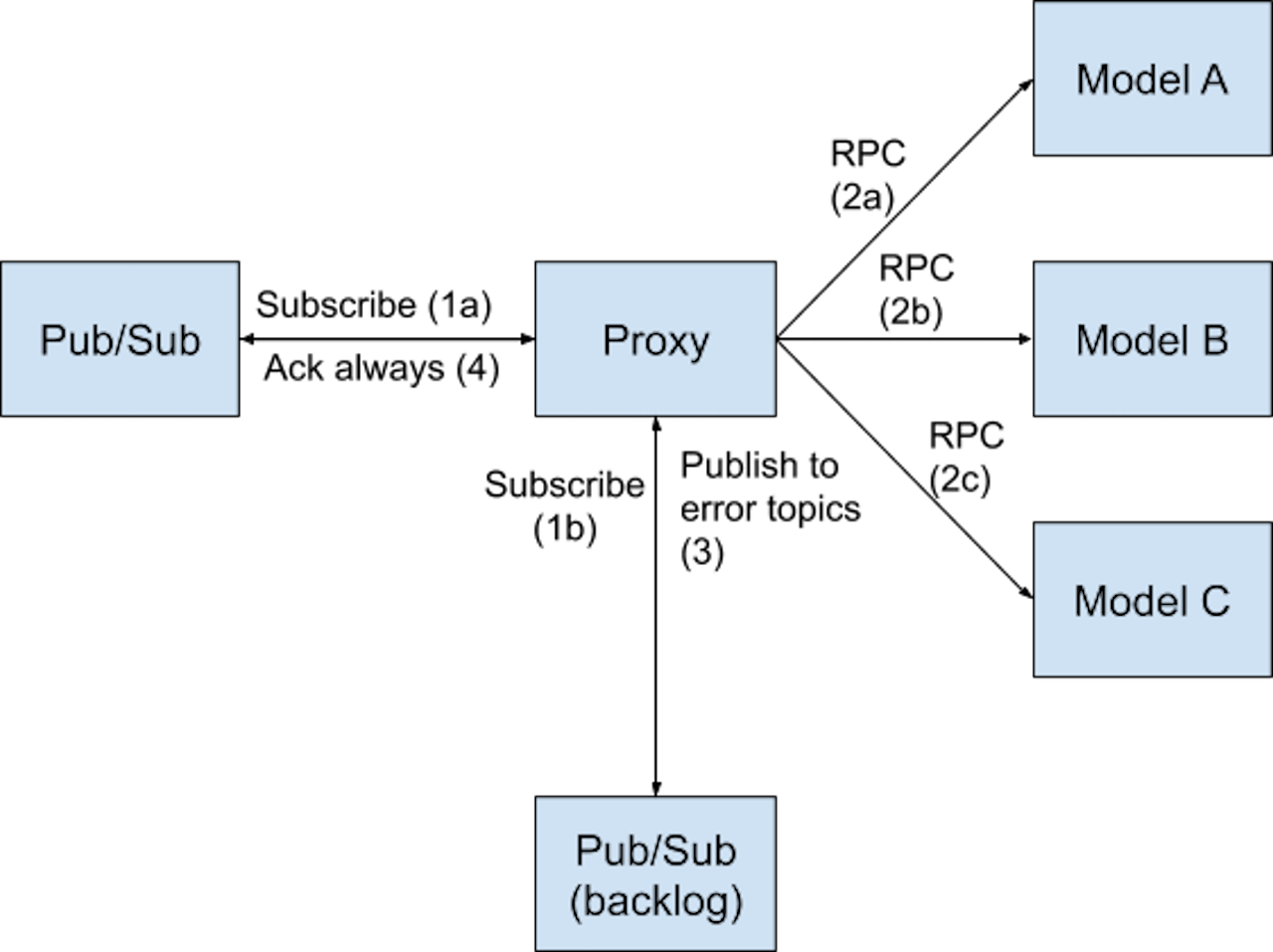
Backlog message queue
This approach is in a way complementary to the caching approach. Instead of caching the responses from all the models for every message, whenever there are errors from any model, we push a copy of the message along with the details about the models that returned errors (such as server address or a unique identifier) into a backlog message queue, which is just an internal message queue. Proxy will be the only publisher to this queue, and it will also be the only consumer of this queue. The advantage of this approach is that when there are errors from some models, the messages from the original message queue can be acknowledged and the proxy can move on to receiving new messages. So the other models will continue processing the new messages. This, of course, places an added load on proxy because it needs to publish and subscribe from an extra queue, but since it’s lightweight, it can scale much easily compared to the computationally heavy ML models.
The process of publishing to the backlog queue could be of two types: publish one message per model that returned error, or publish one message for all the models together. With one message per model, the load on the dependencies increases linearly with the number of models that return errors. On the other hand, with one message for all the models, the message can not be acknowledged till all the models respond successfully. We could, however, iteratively do the same processing, i.e., acknowledgement of the message in the backlog queue, and add another message whenever some models manage to respond successfully and some others fail. This makes it harder to monitor end-to-end latencies though. The decision in this case should be based on what is important, perfect monitoring of the end-to-end latencies, or minimizing the load on dependencies during downtime. Either way, this approach reduces downtime to partial downtime since the other models and the original message queue are completely unaffected.
This approach had a disadvantage as well, based on our tests. To reduce the impact due to high latencies from some model, the request timeout has to be small enough to avoid cascading failure. In most cases, there are no issues with this, however, more requests fail due to timeout and even during normal operations, there could be a few messages that end up in the backlog. This should be acceptable though, because the motivation of asynchronous communication is not minimizing latency, but to provide an acceptable latency at a higher availability. Unlike the internal message queue approach, the backlog queue is only an additional feature, so any future requirement to provide synchronous endpoints are not impacted by this. Below is a flow diagram of the backlog message queue approach.
Conclusion
This was a very interesting problem that I worked on, where the problem statement was driven by technical debt rather than business requirements. We have implemented the backlog message queue in production already, and it has been stable. We have also had no incident due to the issues mentioned above since the implementation. To conclude, there could be several solutions for any given system design problem and it might not always be possible to choose the ideal one. Factors such as development overhead and scalability need to be considered so that we don’t have to revert/abandon the work done due to business changes in the future.
We have published more articles and a paper about this system in the past. Please have a look at them if you are interested in knowing more about it.
- Paper at the 2020 USENIX Conference on Operational Machine Learning
- Human in the loop system
- Neural architecture search for multimodal modeling
- Multimodal Information Fusion




