Introduction
The seven day’s post of Mercari Advent Calendar 2020 is brought to you by Yu from mercari data platform team.
We have been building a data-driven culture at mercari. As you know, building a data-driven culture is not so easy, because we have to change our mindset and implement technical foundations. Especially, it is very difficult to achieve that without technical foundations. So, in this article, I want to describe how mercari has been improving data management on BigQuery with dbt (data build tool) which is an open-sourced project. The first section describes the background of the issues we wanted to address. The second section explains the basic knowledge about dbt. The third section introduces a bit of our rules and the tool to make the best of dbt.
Background
In today’s world, companies require warehouses to be data-driven. Especially, large services like mercari need a warehouse with a large amount of data. As we posted many tech blog articles, we take advantage of Google Cloud Platform. Especially, BigQuery is a must for mercari, because it is serverless, highly scalable and cost effective. I can’t imagine how to manage our structured data without BigQuery. Even non data experts take advantage of BigQuery at mercari.
Meanwhile, data management and data engineering managing BigQuery are challenging for us. Those are the main issues we have to address in order to provide reliable data to internal data customers. There are many perspectives in data management. In the article, I want to highlight the three main issues at mercari, data and data pipeline ownership, data quality and data discovery.
Data and Data pipeline ownership
We have the internal framework on top of Apache Airflow to implement data pipelines for intermediate tables on BigQuery. We also use terraform to define BigQuery views. Moreover, as we are moving toward microservices, data stores like Google Spanner and Cloud SQL are located in different instances and google cloud projects. The data platform team supports loading data from data stores to BigQuery. And the data management team supports organizing data originally distributed on BigQuery.
But, sometimes it is required to make use of data across multiple owners. Consider if we want to create a data mart created by an Airflow DAG which contains complicated dependencies by using intermediate tables in the middle of the steps of other DAGs. Then, we need a little tricky technique and alignment with stakeholders. In general, as the number of steps get complicated and deeper and the number of stakeholders gets increased, the more difficult management cost is.
Data quality
Data quality is a measure of the condition of data based on factors such as accuracy, completeness, consistency, reliability and whether it’s up to date. But, we didn’t check data quality on BigQuery very much. So, some issues as missing records and duplicates were raised, when data analytics and machine learning engineers figured out their desired data. For example, when we use Google Pub/Sub and BigQuery streaming insert to continuously load data to BigQuery, duplicated records potentially occur. To make matters worse, we were not potentially aware of bad data quality on BigQuery.
Data discovery
It takes a little long time for especially inexperienced users to figure out desired data on BiQuery for data analytics. Because we have a lot of tables and views on BigQuery across google cloud projects. Moreover, it is almost impossible to understand the characteristics of tables without asking and playing around with them due to the lack of metadata of BigQuery tables. Consider if a column setting is set to 0 or 1, we are not sure the meaning of the binary values without the description.
Actually, Google Cloud Data Catalog enables us to search data sources of Google Pub/Sub, Cloud Storage and BigQuery. However, one of the hardships is to annotate metadata of tables as table descriptions and column descriptions. Of course, we can edit them on BigQuery web UI, but it is hard to track when and who changes metadata and to have a workflow to review. So, we have to make data understandable and to make data discoverable.
What is dbt?
To solve as many issues as possible with less tools, we decided to introduce dbt (data build tool) which is an open-sourced project, because dbt broadly covers our issues.
dbt plays an important role in warehouses. It officially supports Postgres, Amazon Redshift, Snowflake and BigQuery. In our case, we use BigQuery. If we want to use other warehouses, the community packages support them.
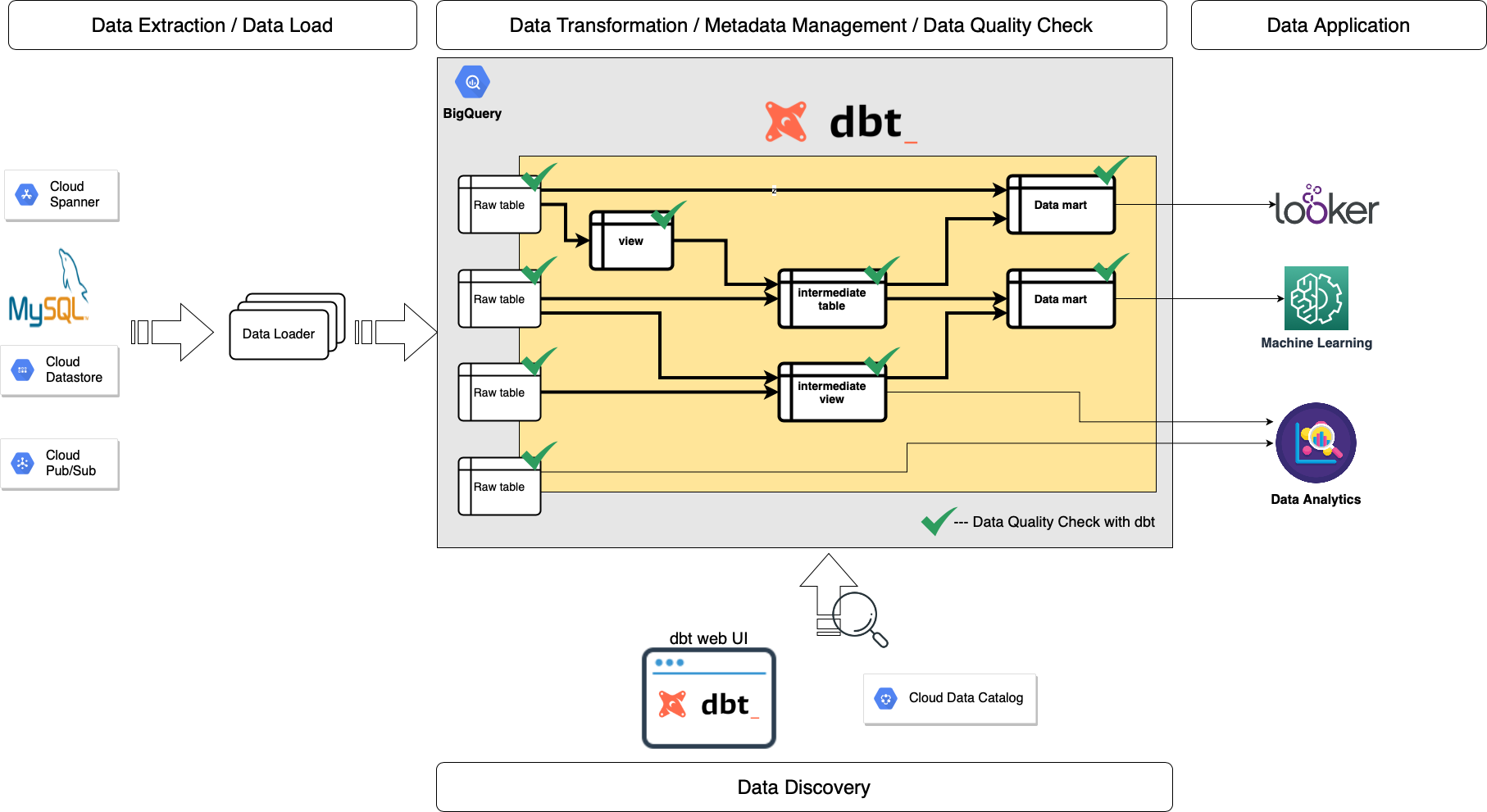
The yellow area is the main role of dbt. dbt does the T in ELT (Extract, Load, Transform) processes - it doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse. So, first of all, we have to load data from original data sources on the left of the chart with other tools. We have several types of pipelines depending on the source data, such as My SQL and Cloud Spanner, using Google Dataflow and Apache Flink. Then, we are finally ready to use dbt. dbt also enables us to:
- model BigQuery tables and views only by SQL files with dbt models,
- test data quality of BigQuery tables and views by YAML files with dbt tests,
- check data freshness of BigQuery tables and views by YAML with dbt source snapshot-freshness ,
- document metadata of BigQuery tables and views with YAML and markdown dbt docs,
- search and discover BigQuery tables and views with the dbt web UI and Cloud Data Catalog,
- visualize dependencies of tables and views on the dbt web UI,
- use community packages to leverage dbt with dbt hub,
- make incremental snapshots of BigQuery tables with dbt snapshots,
- share BigQuery queries with dbt analyses, and
- manage metadata of data consumers with dbt exposure.
There are many reasons why we choose dbt. Of course, the features resolve our issues. Moreover, dbt requires only SQL and YAML files. So, people who mainly use SQL can easily learn dbt, because only SQL and YAML files are required for dbt. Additionally, even if we no longer dbt, we can take advantage of assets created by dbt in the future, because we can persist metadata of tables and views to BigQuery andreuse SQL statements compiled by dbt.
I would love to describe them all, but let me describe dbt source, dbt models and dbt tests in the article.
dbt source
dbt sources is used to deal with existing BigQuery tables and views which are loaded by other tools. We can declare dbt sources with YAML files as below. We can refer to dbt sources with {{ source() }} macro. I will talk about how we can use macros later.
First, we can annotate description and labels to an existing table. Unfortunately, dbt doesn’t have the feature to write metadata in dbt source YAML files to BigQuery at the time of writing this article. But, we can see annotated metadata in the dbt web UI.
Second, we can check data quality of even existing tables and views with tests. dbt supports built-in tests which are unique, not_null, accepted_values and relationship. In addition to the built-in tests, we can create custom tests using SQL and 3rd party packages as fishtown-analytics/dbt-utils is very convenient. In the case below, unique and not_null of the id column enables us to check if the values are unique and not null respectively. We don’t have to write SQL queries as airflow’s check operators require ones.
Third, dbt has a feature to check data freshness. The freshness block is the definition of how to monitor the data freshness of the user table. If the data loader to update the table was unsuccessful, the scheduled job to monitor data freshness raises alerts in our case.
version: 2
sources:
- name: production
tables:
- name: users
loaded_at_field: updated
freshness:
warn_after:
count: 12
period: hour
error_after:
count: 24
period: hour
description: |
## Overview
The table contains users data.
labels:
owner: "customer_data_team"
data_source: "MySQL"
columns:
- name: id
description: "user ID"
tests:
- unique:
- not_nulldbt models
dbt models are crucial too so that we build data pipelines for intermediate tables and views using only SQL. Consider if we create an intermediate table about user attributes. The table should contain denormalized user information, such as the time the user first purchased. Technically, we can build a large, complicated SQL statement. However, it is hard to maintain complicated queries.
Rather than that, dbt enables us to take control of complicated dependencies by dividing intermediate tables. Let’s consider the situation where we want to create a table about only when each user first purchased. When transactions, which is an existing table, contains purchase information, we can get the first purchases by user with the query below.
Because dbt uses jinja2 template engine, we can use jinja2 features and the macros provided by dbt. config, a macro provided by dbt, enables us to control dbt model’s features. For example, materialized is a strategy to persist dbt models in a warehouse, whereas {{ source('product'', 'transactions') }} is a macro to refer to the transactions table as a dbt source.
-- first_purchases.sql
{{
config(
materialized="table",
alias="first_purchases",
owner="data_analytics_team",
persist_docs={"relation": true, "columns": true},
tags=["daily"],
)
}}
SELECT
buyer_id AS user_id
, MIN(created_at) AS first_purchases
FROM {{ source('product', 'transactions') }}
WHERE
status = "done"
GROUP BY 1We can test intermediate tables and views with dbt with YAML files. In the case of the first_purchases table, the user_id column should be unique and have correct foreign keys to the users table. So, the more we add tests, the better the data quality gets.
In addition, we can persist table descriptions, column descriptions and labels of dbt models to BigQuery. By doing that, we can reuse assets created by dbt. Take Google Cloud Data Catalog, for instance. It is a fully managed and highly scalable data discovery and metadata management service. It enables us to search and discover BigQuery tables and views with the rich syntax. Since the dbt web UI at dbt==0.18.1 doesn’t support search by labels, we can take advantage of Cloud Data Catalog in addition to dbt for data discovery.
version: 2
models:
- name: first_purchase
labels:
owner: data_analytics_team
interval: daily
status: experimental
description: |
## Overview
The table contains the first purchase timestamp by user.
columns:
- name: user_id
description: "user ID"
tests:
- unique
- relationships:
to: source('product', 'users')
field: id
- name: first_purchase
description: "first purchase timestamp"
tests:
- not_nullThen, assume we have created many intermediate tables related to user attributes. Now, we can join them together and save the results to an intermediate table whose name is user_attributes. Here, {{ ref() }} is a macro to refer to intermediate tables modeled by dbt.
-- user_attributes.sql
{{
config(
materialized="table",
alias="user_attributes",
persist_docs={"relation": true, "columns": true},
tags=["daily", "only_prod"],
)
}}
SELECT
u.*
, first_purchase.* EXCEPT (user_id)
, first_listing.* EXCEPT (user_id)
FROM {{ source('product', 'users') }} AS u
LEFT OUTER JOIN {{ ref('first_purchase') }} AS first_purchase
ON u.id = first_purchase.user_id
LEFT OUTER JOIN {{ ref('first_listing') }} AS first_listing
ON u.id = first_listing.user_iddbt CLI
The open-sourced dbt offers the CLI. We can execute the queries modeled by dbt with the CLI. The CLI has some sub commands.
dbt runenables us to execute all dbt models defined in SQL files.dbt testenables us to execute all tests defined in YAML files.dbt source snapshot-freshnessenables us to check data freshness in YAML files.
Now, you might wonder how we run the queries and think we have to run queries one by one manually. But, dbt enables us to run queries with the right order by interpreting dependencies with the {{ source() }} and {{ ref() }} macros. For instance, when dbt model B depends on dbt model A, dbt automatically run dbt model A and then dbt model B. So, as long as dependencies are not cyclic, dbt is able to deal with any complicated dependencies. All we have to do is to execute dbt run.
This is a part of the real data lineage (dependencies) graph at mercari. The image was visualized by dbt. Thanks to the {{ source() }} and {{ ref() }} macros, we are able to automatically manage the complicated dependencies. We don’t have to manually consider how to manage the dependencies.

When we want to select some of dbt models, model selection syntax is convenient. The model selection syntax can be used by passing conditions to the --models option. The + prefix syntax enables us to create all intermediate tables which are required to create user_attributes. Other than that, we can declare the condition in a YAML file selectors.yml.
$ dbt run --models +models/user_attributes.sqlHow we use dbt at mercari?
dbt is awesome! But to make it even better, we made custom coding rules and a custom command line tool for productivity.
Custom coding rules: tags property
As I described a little bit about the model selection syntax, we are able to select desired dbt models and sources with tags. First, we created custom tags to specify running environments that are only_prod, only_dev and WIP. For instance, when some tables that a dbt model refers to only exist in production environment and we want it to be run only on the production environment, all we have to do is to tag only_prod. Here is the relationship between the tags and scheduled environments.
| environment | only_dev |
only_prod |
WIP |
no only_dev/only_prod/WIP |
|---|---|---|---|---|
| development | O | X | X | O |
| production | X | O | X | O |
Second, we have custom tags to schedule dbt models and tests. The commercial dbt cloud product supports the scheduling feature. On the flip side, the open-sourced dbt doesn’t have one. So, we have to schedule dbt jobs with other tools such as using Apache Airflow. The tags below are used to control intervals of dbt models. When we want to schedule a dbt model as a daily job, all we have to do is to tag daily.
| tag | description |
|---|---|
hourly |
tagged resources are scheduled hourly |
daily |
tagged resources are scheduled daily |
weekly |
tagged resources are scheduled weekly |
monthly |
tagged resources are scheduled monthly |
Custom command line tool
We are creating a python-based custom command line tool. The main objectives are to be more productive and to fill in the missing pieces of dbt. The name is dbt-helper, but it is different from dbt-helper on github.
As you can imagine, it is a bit of a hassle to implement YAML files for dbt sources from scratch. That can potentially be a high entry barrier. So, the command line tool is able to generate YAML files from existing BigQuery tables. A generated YAML file contains information about an existing BigQuery table. The information is a table description, columns and those descriptions and labels. Of course, we need to add necessary tests and metadata to the generated YAML files. But, we don’t have to implement dbt sources from scratch. For instance, we can generate a dbt source for users table with the command below.
$ dbt-helper source importing \
--models_dir ./models \
--project product-project-prod \
--project_alias product-project \
--dataset product \
--table "^users$"One more thing I want to describe the command line tool is to write metadata of existing BigQuery tables from dbt source. dbt==0.18.1 doesn’t have a feature to write metadata of BigQuery tables due to the design concept. If other tools to load existing BigQuery tables can automatically annotate metadata, we don’t have to worry. But if not, we have to think of how to manage metadata of existing tables. So, it would be great to centralize the metadata managing place in dbt. For instance, if we update the table description, column descriptions and labels of the users table in the YAML file, the command enables us to write the updated metadata to the table on BigQuery.
$ dbt-helper source update-from-source \
--models_dir ./models \
--source_path ./models/users.ymlSummary
There were a lot of issues on data management. Especially, we had to improve data/data pipeline ownership, data quality and data discovery. dbt can solve most areas of our issues.
I described dbt source and dbt models with data quality tests and data freshness tests. We can implement even complicated data pipelines only using SQL with dbt. We don’t need further implementation. The built-in tests and 3rd party packages enable us to check data quality only using YAML files. We also can check data freshness of existing tables with YAML files too. {{ source() }} and {{ ref() }} enables us to automatically resolve dependencies among tables. We are free from manually managing complicated jobs. We don’t have to tune data pipelines by hand.
Finally, I explained the custom tags and the command line tool. dbt has the model selection syntax. So, we can select parts of dbt models and sources with the syntax. By making the rules of custom tags, dbt developers can control the running environments and intervals with only tags.
The custom command line tool makes us more productive by generating dbt sources from existing BigQuery tables. And another main objective is to fill in the missing piece of dbt such as writing metadata of BigQuery tables.
Actually, dbt can solve issues on data management of warehouses. It doesn’t cover other data sources as Apache Kafka, Google Pub/Sub, S3, Google Cloud Storage and so on. But, since we use BigQuery as a primary data warehouse, dbt covers the majority of our issues. I am sure we are moving toward better data management with dbt.




