
この記事は「連載:技術基盤強化プロジェクト「RFS」の現在と未来」として書かれたものです。
メルカリ JP の CS Tool チームにバックエンドエンジニアとして 2022 年に新卒入社した @monkukui です。現在、私たちのチームは、メルカリ CS Tool (Custmer Service Tool) を Kubernetes に移行するプロジェクトを進めています。今回の記事は、このプロジェクトを進めるうえで直面した問題を一つ取り上げ、その問題をどの様に解決したかを紹介します。
CS Tool チームの他の取り組みは、@hukurou さんによる「メルカリCSツールにおけるDBの疎結合化への取り組み」で紹介されているので、興味がある方はそちらも是非御覧ください。
「RFS」における CS Tool チームの取り組み;GKE 移行について
RFSとは「Robust Foundation for Speed」の略で、メルカリが将来に渡って力強く、素早く成長し続けるために、今あるビジネス共通基盤の複雑な技術的問題を解決していく取り組みです。以下の記事では、より詳細にプロジェクトの目的や取り組みについて説明しています。
関連記事:メルカリが今、ビジネス基盤強化に投資する理由とは?プロジェクト「Robust Foundation for Speed」の全貌
GKE 移行の概要
RFS における CS Tool チームの取り組みの一つが GKE 移行 です。GKE 移行 とは、GCE(Google Compute Engine)上で動作する CS Tool アプリケーションを、GKE(Google Kubernetes Engine)に移行するプロジェクトです。
メルカリ内の多くのマイクロサービスは、一つの Kubernetes クラスタ内に構築されています。一方で、これまでの CS Tool は GCE 上で動作する複数のインスタンスから構成されています(図 1)。この CS Tool を、他のマイクロサービスが動く GKE クラスタ内に移行することがこのプロジェクトの目標です(図 2)。

図 1: GKE 移行前のインフラ構成図(簡易版)。CS Tool モノリスは GCE 上で稼働している。CS Tool チームが開発している他のマイクロサービスはすべて GKE 上で稼働しており、CS Tool モノリスから GraphQL サーバーを経由して、他のマイクロサービスへリクエストを行う。
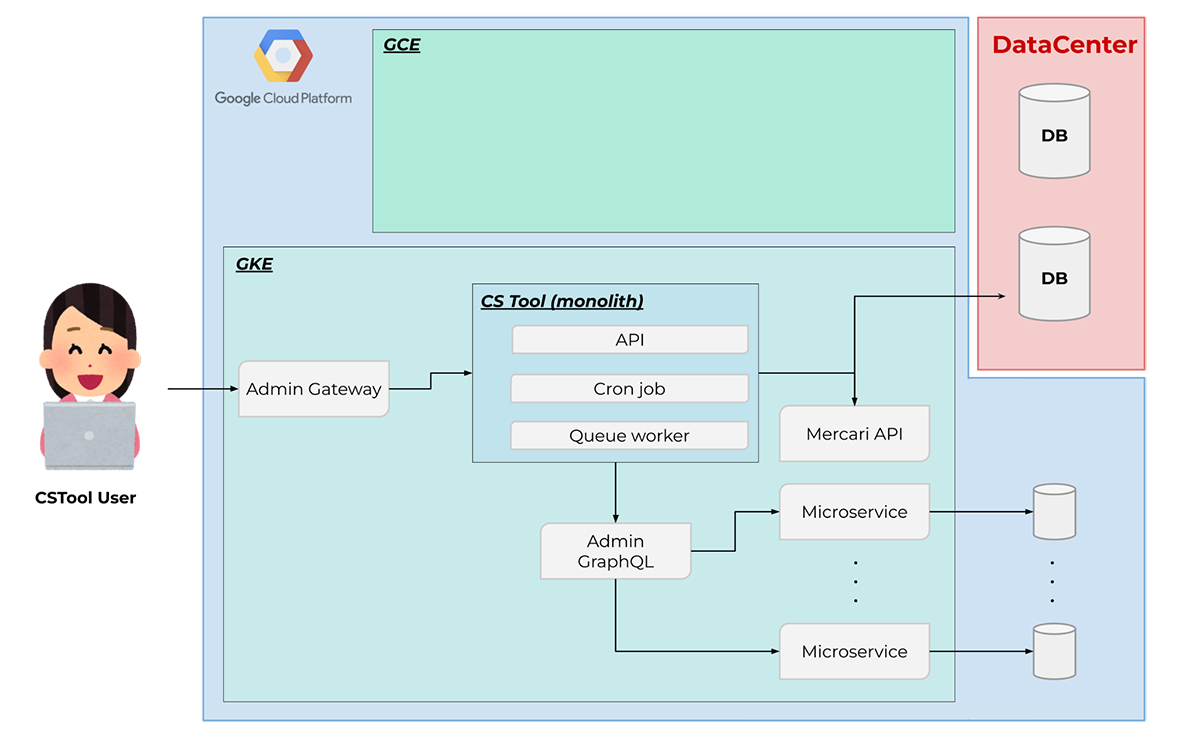
図 2: GKE 移行後のインフラ構成図(簡易版)。CS Tool モノリスをすべて GKE に移行する。
GKE 移行を行うモチベーション
メルカリでは全社的にマイクロサービスアーキテクチャおよび Kubernetes への移行に取り組んでおり、新規機能はすべて Kubernetes 上でマイクロサービスとしてデプロイされています。
一方で、現在の CS Tool は、SRE チームが GCE 上に構築したモノリス用の基盤上で動作しています。そのため、「言語のバージョンアップデートをしたい」といったときや、「アドホックなバッチ処理を実行したい」、「クレデンシャルに修正を加えたい」などのインフラに関連する変更は SRE チームに依頼をする必要がありました。周辺のツールなども Kubernetes 環境とは全く異なるものであり、開発者にとっても二重の学習コストがかかっています。
| 技術スタック | GCE | GKE |
|---|---|---|
| Deploy | Slack bot | Spinnaker |
| APM | New Relic | Data Dog |
| Monitor | Mackerel | Data Dog |
| Logging | Kibana | Data Dog |
| Operation | Ask SRE team | GitOps by ourselves |
| QA env for Pull Requests | Manual | Automated |
| Autoscaling | No | Yes |
表 1: GCE で動作している CS Tool の技術スタックと、メルカリの Kubernetes 上のマイクロサービスが持つ技術スタックの比較。
これらの問題を解決するために、現行の CS Tool モノリスをコンテナ化して Kubernetes に乗せることにしました。
SRE チームが管理する GCE 上のモノリス用の基盤を廃止することで、システムのオーナーシップを完全に自チームに移管できます。例えば、言語のアップデートがしたかったらその言語の base image を作成し、kubernetes の manifest で指定する image を変更すれば良いです。他にも、ログ集約基盤として fluentd を使いたければ、Kubernetes サイドカーとして Pod にコンテナを追加すればよいですし、各種インフラの設定も Kubernetes manifest で一元管理できます。
さらに、メルカリでは、Kubernetes へのデプロイ手法として Spinnaker が広く採用されています。また、アプリケーションログの収集やシステム監視の基盤として、DataDog が広く使用されています。周辺ツールを社内のデファクトに統一することで、メルカリ社内で蓄積されたノウハウを用いることができ、開発体験の向上やオンボーディングコストの削減などが期待できます(表 1)。
このように、GCE から GKE に移行することで、オートスケーリングや障害時のセルフヒーリングなどの Kubernetes の恩恵を授かることが期待できるだけでなく、自チームのプロダクトに対してオーナーシップを持ち、素早い開発・リリースサイクルを回すことができるようになります。
参考:SpinnakerによるContinuous Delivery
参考:Datadogを使って感じた、問題調査/対応における変化とその要因
参考:巨大モノリスをKubernetesに移行してシングルクラスタ運用にするためにどうしたか
どのように GKE 移行を進めているか
CS Tool を GCE から GKE に移行するプロジェクトの流れを紹介します。
CS Tool の移行対象のコンポーネントは、以下の 3 つです。
- Queue worker
- Cron job
- API
1. Queue worker とは、ジョブを蓄える Queue と、Queue に蓄えられたジョブを非同期に処理する Worker からなる機能のことです。
2. Cron job とは、指定された時間に(例えば、毎朝 10:00 に)ジョブを定期実行する機能のことです。
3. API は、CS Tool のフロントエンドからリクエストを受け取り、レスポンスを返します。
これら 3 つのコンポーネントのうち、Queue worker と Cron job は、CS スタッフが直接触れられる機能ではありません。さらに、Queue worker は、移行の途中で GCE と GKE の両方の環境で同時に実行しても問題がないことが事前の調査でわかっていました。移行のしやすさと、移行に失敗したときのリスクの低さを考慮して、Queue worker -> Cron job -> API の順に移行することに決めました。
ただアプリケーションを GKE に移行するだけでなく、Kubernetes で動作するシステムをどの様にモニタリングするかも重要です。CS Tool チームでは、APM の取得、ロギング、モニタリングをすべて DataDog に任せ、システムを監視していくことにしました(図 3)。
また、アプリケーションの継続的デリバリを実現するために、Spinnaker を採用しました。

図 3: Data Dog のダッシュボードの例。Kubernetes リソースを用いて、Cron job に関するメトリクスを可視化している。
2022年10月時点で、Queue worker と Cron job の 2 つのコンポーネントの移行が完了しており、Spinnaker によるデリバリーパイプラインが構築され、DataDog によるシステムを監視する仕組みが構築されています。これから、CS Tool 本体の Admin API を GKE に移行していきます。
GKE 移行を進める上で発見した問題と、その解決法
Queue worker や Cron job の GKE 移行を進める上で、システムが抱える様々な問題を発見することができました。そのなかの一つの問題を取り上げ、その問題をどのように解決したかを紹介します。
商品一括非表示 Worker の問題点
CS Tool には、お客様の出品商品を一括で非表示にする処理を行うための Queue worker があります。メルカリの規約に違反するような商品を出品しているユーザーに対して、CS Tool 上から「商品一括非表示」を行うことができます。ただ、お客様の中には、10000 件以上の大量の商品を出品しているユーザーが存在します。このようなユーザーに対しては、商品の一括非表示に時間がかかってしまうので、非同期に処理できる Queue worker を採用していました。処理の流れとしては、以下のようになります。
- CS Tool UI 上で「商品一括非表示」ボタンを押す
- user_id を Queue にエンキューする
- Worker が user_id を Queue から取得し、user_id に紐づく商品すべてに対して非表示処理を行う
この worker を GKE に移行し、Data Dog でシステムを監視していると、ある発見がありました。それは、CS Tool UI 上で商品一括非表示の処理をトリガーしてから、実際に商品がすべて非表示にされるまで 30 分以上かかっているケースが存在することがわかりました(図 4)。規約違反の商品を早く非表示にするための機能なのに、これだけ時間がかかっていることは問題です。

図 4: Queue に溜まっているメッセージが処理されるまでに 48 分もの時間がかかっている
商品一括非表示 Worker を刷新
この問題を解決するために、Kubernetes の HPA (Horizontal Pod Autoscaling) を設定して、Queue にジョブが溜まってきたら pod を増やして並列稼働させ、ジョブを処理する速度を高めることを考えました。しかし、Queue に溜まっているジョブをすべて処理するのにかかる時間は、出品商品の総和に比例します。現状のシステムだと、Queue には user_id が格納されているので、実際の出品商品の総和はわかりません。
そこで、システムデザインを刷新して、一から新しく商品一括非表示機能を作り直す決断をしました。新しいシステムの概要は以下のとおりです。
- CS Tool UI 上で「商品一括非表示」ボタンを押す
- user_id から出品商品の item_id に分解し、item_id を Queue にエンキューする
- Worker が item_id を Queue から取得し、その商品に対して非表示処理を行う
こうすることで、Queue に溜まっているジョブの数が、そのままシステム全体の負荷を表すことになります。HPA は、溜まっているジョブの数に応じて pod をスケーリングするように設定します。結果として、UI 上で一括非表示の処理をトリガーしてから実際に非表示されるまでに掛かる時間が格段に改善されました(図 5)。
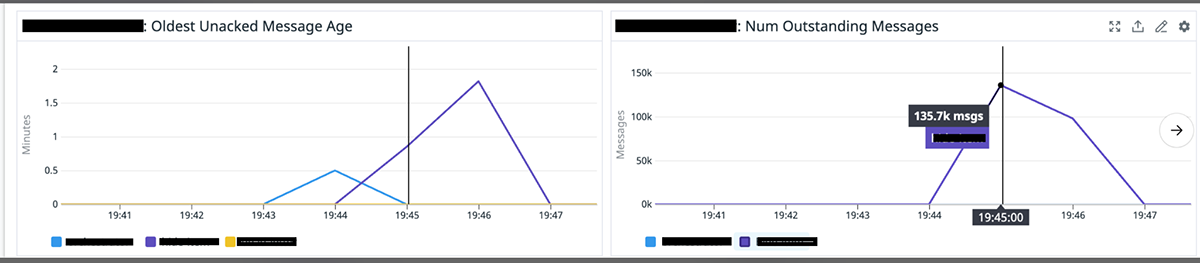
図 5: 大量のメッセージが 3 分程度で処理される様子
まとめ
この記事では、CS Tool チームが取り組んでいる CS Tool の GKE 移行や、それによって得られた恩恵について紹介しました。
GKE 移行を進める上で、CS Tool への自チームが持つオーナーシップが確かに向上していることを実感しています。モニタリングを通して、様々な潜在的な問題を発見することも多くありました。この記事で紹介した「商品一括非表示」機能の他にも、思いがけないぐらい長時間実行している Cron job や、頻繁に失敗する Cron job の存在に気がつくことができました。また、発生しているエラーに対しての改善方法やリカバリ方法をチームで考える事ができるようになったりと、以前より主体的に自チームのサービスに向き合えるようになりました。これらの点は、GKE 移行 を通して、サービスに向き合う意識が向上したことによる恩恵だと思います。
現在は、GKE 移行プロジェクトの本丸である Admin API 移行に取り組んでいます。CS Tool のすべてのコンポーネントが完全に GKE に移行された後の世界を早く見てみたいです。そのころには、きっと CS Tool チームが今よりオーナーシップを持って、素早い開発サイクルを回し、堅牢で信頼できるサービスを提供し続けることができているでしょう。
この記事で紹介した取り組みは、「RFS」というメルカリのビジネス共通基盤の技術的な課題を解決していく全社横断的なプロジェクトにおける、CS Tool チームの取り組みです。そしてメルカリではこの RFS という大きなプロジェクトに一緒に立ち向かっていく仲間を募集しています!ご興味が湧いた方は、以下のリンクをご覧ください。




