SREの@deeeetです。
新しい機能を素早くリリースしフィードバックを得てすぐにPivotの決定を行う、もしくはリスクを抑え小さな改善を継続的に行うContinuous Deliveryはソフトウェア開発において非常に重要です。
メルカリではこのContinuous DeliveryのためのPlatformにSpinnakerを採用し始めました。現在は主にkubernetes(k8s)へのコンテナアプリケーションのDeployに利用しており、既にいくつかの本番アプリケーションがSpinnakerによりDeployされています。
本記事ではなぜSpinnakerを採用したか、Spinnakerとは何か、実際にメルカリでどのようにSpinnakerを使っているか、について簡単な紹介をします。
kubernetes上でのDeploy問題
k8sへのコンテナイメージのDeployは非常に簡単です。単純なものであればmanifestファイルを書きkubectlコマンドを使ってapplyするだけです。新しいイメージのDeployもイメージのタグを書き換えてapplyするだけです。設定によりRolling updateも可能で、問題が起こったあとのRollbackも容易に行えます。
少人数であればkubectlを直接使うというオペレーションで問題ありません。しかし規模が大きくなる、開発人数が増えると 誰がkubectlコマンドを実行するのか問題に直面します。多くの会社ではkubectlのようなコマンドの本番環境への実行権限はSREなどインフラに関わるチームに限定されていると思います。このような場合に日に何度もDeployする体制を作ろうとすると、SREへのオペレーションの依頼が集中することになります。
この問題を避けるには、CIからkubectlコマンドを実行する、もしくはkubectlコマンドをラップしたChatbotを開発するといった方法が一般的には考えられます。メルカリでは最初はChatbotを採用しました(GolangでSlack Interactive Messageを使ったBotを書く)。
単純にDeployを行う程度であれば独自のツールやBotを構築するのは容易です。より安全かつScalableなDeployを目指すとそのChatbotやツールは以下のような機能やDeploy戦略の実装も求められるようになります。
- 問題が起こったときにすぐにRollbackする
- Blue/Green Deployを行う
- Canary Deployを行う
- Integration testを実行する
- マネージャーの承認のフローを挟む
- QAチームと連携する
- …
これらを「ちゃんと」実装し、かつメンテし続けるのは非常に大変です。
また現在メルカリではmicroservices化が進められています。microservices化の利点の1つとして各チームがそれぞれ独立してDeployを行えることが挙げられますが、このDeployは基盤として自動化・統一化されているべきです。microserviceが増えるたびに独自のツールやbotを拡張し続けるのは限界があります。
これらの問題を考慮した結果kubernetesをメインにサポートしているSpinnakerの検証及び採用に至りました。
Spinnakerとは何か
SpinnakerはOSSのContinuous Delivery Platformです。もともとはNetflix内部で開発・運用されていましたが、2014年にGoogleと連携した開発が始まり2015年11月にオープンソースとして公開されました。そして、今年(2017年)の6月にバージョン1.0が公開されました。Multi-cloudに対応しておりGCEやEC2、k8sで利用することができます。
メインページで述べられているようにSpinnakerには多くの機能がありますが、特に私が素晴らしいと思うのは以下の2点です。
- 自動Deployに必要な機能が揃っている
- Immutable Infrastructureを強制する
自動Deployに必要な機能が揃っている
Spinnakerは以下のようなPipelineでDeployを管理します。

https://www.spinnaker.io/concepts/pipelines.png
PipelineはSpinnakerによって提供される各種ステージを連結することで構成します。このステージにはDeployだけでなく、Canary Deployを実行する、承認フローを入れる、JenkinsのJobを実行する、といった自動Deployに必要な多くの機能が揃っています。これらを組み合わせることで自由なDeployを実現できます。
Cloudを使ったDeployの自動化は多くのAPIリクエストで構成されることになり、失敗を完全に避けるのは不可能です。自動化で難しいのはエラーに対するハンドリングをちゃんと実装し、一貫性を担保することです。Spinnakerはこれらが丁寧に実装されています。例えば以下はSpinnakerがRed/Black DeployにおいてClusterのDisableをするときの各Operationを図にしたものです。これを「自分でちゃんと」実装するのは難しいでしょう。

https://www.spinnaker.io/concepts/pipelines/pipeline-tasks.png
Pipelineは手動で起動することもできますし、Docker registryへのイメージのpushやcronなどをトリガーとすることができます。またPipelineの完了、もしくは失敗に対してEmailやSlackへ通知を行うこともできます。
San Franciscoで行われた1.0リリースパーティに参加し話を聞いた限りでは、Netflixではアプリケーションはもちろんのこと、KafkaやCassandraなどのDeployやJavaなどのLibraryのリリースにもSpinnakerを使っているそうで、あらゆるユースケースで利用できることが期待できます。
またNetflixですでに使われており今後リリースされそうな機能として期待感が高いのはAutomated Canary Analysis (ACA)です(Can I push that? Building safer, low-risk deployments with Spinnakerで紹介されています)。これはCanary Deployを行ったあと、アプリケーションのレイテンシやログのエラーレートを計測し、Canaryに点数をつけるという機能です。この点数が設定値を満たしていればそのままRolloutし、低ければRollbackすることができるようになり、Deploy後に開発者がログやメトリクスを監視して云々をなくすことができます(Test coverageを計測してPull RequestのMergeの可否を判断するのに似ています)。
Immutable Infrastructureを強制する

https://www.spinnaker.io/concepts/clusters.png
SpinnakerはデフォルトでBlue/Green (Red/Black)Deploymentを行う仕組みをサポートしています。個人的に一番興奮するのはこの点です。
Blue/Green Deploymentを行うことでImmutable Infrastructureを実現することができます。Immutable Infrastructureとは、一度Deployをしたインスタンスやコンテナには二度と手を加えず、新たにDeployを行う場合はインスタンスやコンテナを作り直すという考え方です。Immutable Infrastructureを採用することでConfiguration driftを避け、安全かつ高速なRollbackが実現できます。
実際にPipelineを作ったりしてみるとわかりますが、このImmutable Infrastructureの思想は各所に散らばっています。例えば今動いているものに変更を加えたい場合はアプリケーションの設定を編集するのではなくてPipellineを編集してそれを実行する必要があります。最初は窮屈に感じることありましたが、今では利点のほうが大きいと感じいます。
メルカリでのSpinnakerの事例
ここではメルカリにおけるSpinnakerの利用事例をいくつか紹介します。
事例1: アプリケーションのDeploy
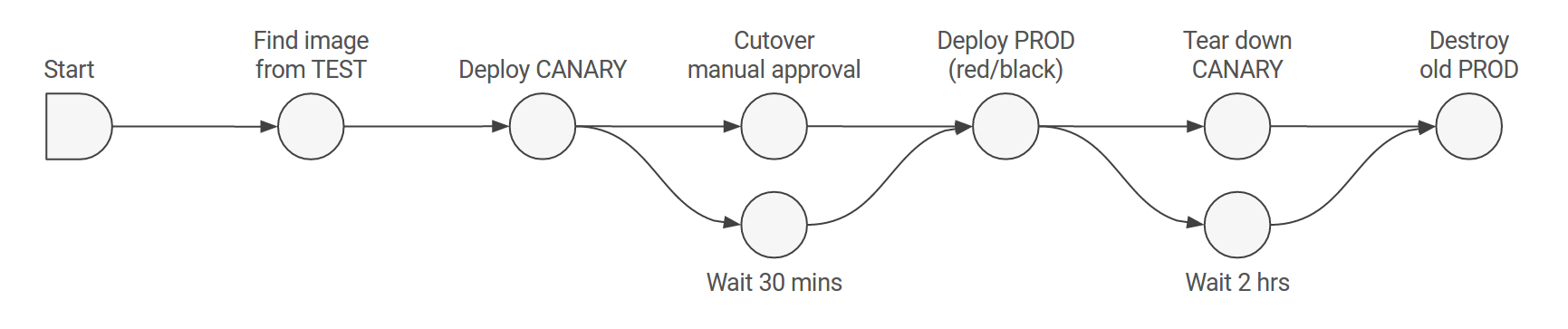
Spinnakerの主な利用はコンテナアプリケーションのDeployです。現在動いているPipelineはとてもシンプルで、新しいDockerイメージがContainer RegistryにPushされたこと(Dockerイメージの作成はCIのジョブとして自動化されています)をトリガーにし
- Pipeline1:開発環境のk8sクラスタへDockerイメージをDeployする
- Pipeline2:本番へのDeployを実行するかの承認を求める
- Pipeline3:本番環境のk8sクラスタへDockerイメージをDeployする
という3つのPipelineを使ったDeployをメインにしています。2以降のPipelineは直前のPipelineの成功をトリガーにして起動するようになっています。
以下はSpinnaker上でのそれぞれのPipelineの様子です。

Pipeline1は開発環境のk8sクラスタへDockerイメージをDeployします。Deployが成功したら直前まで動いていたイメージは削除します。

Pipeline2は本番へのDeployのPipeline(pipeline3)を実行するかの承認を求めます。この間はDeployが止まるので動作確認などのテストを実行します。
将来的にはここでIntegrationテストなどを実行し人手による確認をなくして完全自動化する、もしくはQAチームと連携する、マネージャー等の承認を得るようにしてより慎重なDeployを実現するといったことも考えられます。

Pipeline3は本番環境のk8sクラスタへDockerイメージをDeployします。ここのDeployは少し特殊で、開発用のk8sクラスタから最新のイメージを見つけ出してそれをDeployします。つまりテストされたもののみを本番に出すことができます(この方式はSpinnakerがImmutableを強制するからこそ実現できます)。DeployはRed/Blackにより行われ、問題があれば古いイメージにすぐRollbackすることができます。
将来的には他にもCanaryを設定して数%のみを新しいイメージに切り替えて本番リクエストでテストをしてDeployを見極めるといったことも考えられます。
事例2: cronによるBatch jobの実行
SpinnakerはcronによるトリガーでPipelineを起動することができます。この機能を使いBatch jobをk8s上で実行しています。

k8sにはcron jobの機能がありますが、現在(2017年8月)はAlpha機能です。メルカリでは主にGoogle Container Engine(GKE)を利用しており、GKEではプロダクションにAlpha機能を使うことができません(Alpha機能を試すことはできます)。GKEでcron jobを実行する方法として愚直にcrontabコンテナで頑張る、もしくはGAE+PubSubを使う方法を試みましたが、Spinnakerでやるのが一番楽でした。
またBatch jobだけではなくアプリケーションのDeployにもcronトリガーは使われ始めています。
SpinnakerのDeploy
Spinnaker自体のDeployはhalyardという専用のツールを使います。基本的には公式ドキュメントHalyard on GKE Quickstartに従った以下の構成でGKE上で動かしています。halyardを動かす専用のインスタンスを準備しそこからGKE上の各コンポーネントを操作しています。

https://www.spinnaker.io/setup/quickstart/halyard-gke/deployment.png
基本的には1つのSpinnakerで全拠点(JP・US・UK)のGKEクラスタへのDeployを担っています(現在13のGKEクラスタにDeployを実行しています)。この1つSpinnakerで全てを管理する方式はNetflixの方式と同様の方式です。
監視にはPrometheus + Grafanaを利用し、HalyardのデータのBackupにはGoogle Cloud Storageを利用しています。
Spinnakerの課題
Spinnakerは非常に便利ですが以下のような課題があると感じています。
- ドキュメントが十分でない
- PipelineをGUIで設定しないといけない
まずドキュメントが十分ではありません。ドキュメントが古いこともありいくつかの設定でハマりました。ただしSlackコミュニティがありそこで質問すれば大抵のことは解決するのでそこまで大きな問題ではないでしょう。
次にPipelineの設定が大きな問題です。現状全ての設定をGUIで行わないといけません。そのため設定変更のレビューができず、また多くのPipelineは似たものになるのにもかかわらず共通化が難しいです。
ただしこれについてはコミュニティも課題に感じているらしくPipelineをTemplate化するためのプロジェクトが進んでいます(Codifying your Spinnaker Pipelines またOSSでつくられた Foremastというツールも存在します)。このプロジェクトが進めばDeclarative Continuous Delivery(DCD)という未来が見え期待感は非常に高いです。
まとめ
本記事ではSpinnakerの紹介を行いました。Spinnakerを使い最高のDeployを実現し開発をどんどん加速させていきましょう。
メルカリでは自動化が好き・k8sやコンテナをゴリゴリやっていきたいSREを募集しています。興味がある方は是非連絡を下さい。
Software Engineer, Site Reliability
参考文献
- Halyard on GKE Quickstart
- Public Spinnaker on GKE
- Kubernetes Source To Prod
- Scaling Spinnaker at Netflix — The Basics
- Can I push that? Building safer, low-risk deployments with Spinnaker
- Guest post: Multi-Cloud continuous delivery using Spinnaker at Waze
- Spinnaker: continuous delivery from first principles to production (Google Cloud Next ’17)




