この記事は、Developer Productivity Engineering Campブログシリーズの一環として、Platform DX Teamの@mがお届けします。
はじめに
メルカリでは社内エンジニアの多くがマイクロサービスを開発に携わっているため、Platform Developer Experience(DX)チームは、Platform Engineeringをもって、エンジニアがビジネスロジックなどのバックエンド開発に集中できるよう、さまざまな社内プロダクトを提供しています(その概要については、前回の記事「Developer Experience at Mercari」で紹介しています)
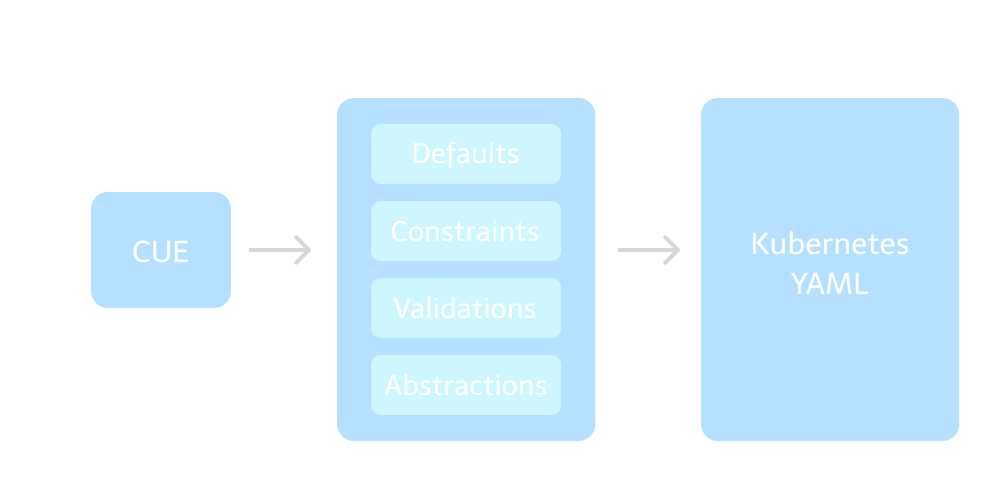
この記事では、私たちが開発してきたCUEによるKubernetesマニフェストの抽象化について紹介します。
これはKubernetesマニフェストの構成に関する多くの問題を解決するために作成されたものであり、コードの削減と設定ミスの防止を行い、多くの推奨された設定をデフォルトで提供します。またCUEを利用したサービスのコード量はYAMLベースと比べて最大90%削減されました。
Kubernetesマニフェストの抽象化
本プロジェクト名は「Kubernetes Kit(k8s-kit)」です。目的は、Kubernetesマニフェストの簡易化とコードの削減の他、Kubernetesクラスタでサービスを動かすための認知的負荷とKubernetesおよびIstioなどの周辺技術スタックの必要知識を軽減することです。また、YAMLの代わりにCUEで実装されています。
関連プロジェクトであるObservability Kitも、Datadog dashboardやmonitorなどの抽象化の実装にCUEによって実装されています。詳細については、こちらの関連記事をご覧ください。
k8s-kitを使用する理由
これまでメルカリでは、Kubernetesリソースの構成にはKustomizeとプレーンなYAMLファイルを使用していました。
そして、開発およびデプロイされるアプリケーション(主にマイクロサービス)が増えるにつれて、次のような大きな課題が見られるようになりました。
- YAML地獄:アプリケーションをデプロイするには、YAMLを使用して多くのKubernetesマニフェストを適切に構成する必要がある
- 学習曲線:Kubernetesには学ぶ必要がある知識が非常に多く、バックエンドエンジニアの負担が大きい
- コントロールの難しさ:Platformチームによる必須/推奨構成の適用が難しい
- マルチクラスタ非対応:すべてのマニフェストがシングルクラスタを前提にしている
メルカリでは、本番クラスタでは200以上のマイクロサービスが稼働されており、すべての開発者が必ずしもKubernetesに精通しているわけではないため、すべての設定の有効性を確認することは困難であり、不適当な設定がコピーアンドペーストされる可能性もあります。
また、Platformチームでは必要に応じてKubernetesリソースに対してセキュリティなど一定のコントロールを持ちたいため、自分たちの要件や推奨要件に合わせてすべてのサービスのKubernetesマニフェストを更新しなければならないこともありました。典型的な例としては、Platformチームが開発者に既存サービスで新機能を有効にするように依頼したい場合です。例えばWorkload Identityは、Kubernetesクラスタで稼働し、Google Cloudに接続するアプリケーションのセキュリティを向上させる技術で、すべてのアプリケーションに対して有効にする必要が出てきました。これにはService Accountの設定など多くのマニフェストの更新が必要とされますが、それぞれの開発者に更新を頼むか、もしくは自分たちで一つずつ更新するかの二択でした。k8s-kitの導入によりWorkload Identityも抽象化したため、開発者はWorkload Identityに低コストで移行できるようになり新規サービスに対してはデフォルトにすることも可能になります。k8s-kitにより、このような問題が開発者の負担を増やすことなく解決でき、また、複雑な設定を行いたい開発者は以前よりもスマートな方法で設定を行えるようになります。
k8s-kitについて
k8s-kitは、Kubernetesリソースに加えてさまざまなレベルの抽象化を提供し、Kubernetesクラスタでアプリケーションを稼働させるためのあらゆる要件を満たすのに適したデフォルトが用意されています。わかりやすい例として、Applicationという複数のKubernetesリソースをまとめた抽象化により、一連のDeployment、Service、(Horizontal | Vertical)PodAutoscaler、PodDiruptionBudgetなどのリソースが生成されます。Istioを利用する場合は、DestinationRuleやVirtualServiceなども生成されます。
このような抽象化の実装で上がる典型的な問題は、柔軟性に欠ける点です。しかし、k8s-kitには十分な柔軟性があるため、ユーザーは必要に応じて設定を調整できるよう、任意のフィールドを追加、更新、削除できるようにするパッチの仕組みを備えています。
また、CUEの機能によって多くのフィールドにバリデーションが実行され、Kubernetesリソースの設定ミスを防ぐことでき、必要なユーザーにはKubernetesリソースに制約を提供しています。例えば、HorizontalPodAutoscaler(HPA)にはk8s-kitによって設定された制約によって、maxReplicasよりも大きいminReplicasの値を使用することはできません。非常に単純な例なので、大きな必要性や利便性を感じないかもしれません。しかし、OPAなどの他の方法よりも分かりやすいバリデーションを提供しながら、正規表現を使用したり複数タイプのリソースの構成を参照できるなど、バリデーションの柔軟さも実現されています。開発者はKubernetes設定の多くの落とし穴を回避できます。詳細については、以下のセクションで説明します。
CUEについて
CUEは、あらゆる種類のデータを定義、生成、検証するために使用されるオープンソースの言語です。CUEはJSONのスーパーセットで、Go、JSON、OpenAPI、Protocol Buffers、YAMLなどの他の多くの言語と連携できます。
また、CUEやGo APIによるスクリプト機能を備えています。私たちはこれを使用して、CUEによるマニフェストを最終的なKubernetesリソースのYAMLとして表示したり、特定クラスタにデプロイするリソースを一覧するコマンドなどを実装しています。
k8s-kitの詳細に進む前に、CUEについて次の概念について解説します。
- 設定の基礎
- データバリデーション
- スキーマ定義
CUEでは、次の例のように構成を定義します。これは、公式ドキュメントで提供されている例に若干の変更を加えたものです。
// example.cue
package example
#Spec: { // schema definition
kind: string
name: {
first: !="" // must be specified and non-empty
middle?: !="" // optional, but must be non-empty when specified
last: !=""
}
// The minimum must be strictly smaller than the maximum and vice versa.
minimum: int & <maximum | *1
maximum?: int & >minimum
}
// A spec is of type #Spec
spec: #Spec & {
kind: "Homo Sapiens"
// Kind: "Homo Sapiens" // error, misspelled field
name: first: "Jane"
name: last: "Doe"
}まず、#Spec(CUEでは”definition”と呼ばれる)で、データのスキーマを定義します。ここでは、kindとnameフィールドの設定を必須とし、いくつかのフィールドに制約を定義し、minimumフィールドのデフォルト値を設定しています。
specは、#Specと組み合わせて構成されます。spec.nameではCUEのshorthandを使用しています。フィールドの値が単一のフィールドを持つ構造体である場合、:で区切られた一連のフィールド名として書き込むことができます。
またCUEは、接頭辞が#の場合はdefinitionを識別し、そうでない場合は値を識別します。値とは異なり、定義はコマンドなどによる評価時にはエクスポートされません。末尾に?が付いたフィールドはoptionalと見なされ、optional以外のフィールドが指定されていない場合、エラーが返されます。spec.kindが指定されていない場合、それが必要であるにも関わらず指定されていないことを知らせるエラーが出力されます。
$ cue export example.cue
spec.kind: incomplete value string // errorデータの出力は次のコマンドで確認できます。
$ cue export example.cue –out yaml // –out has defaulted “json”
spec:
kind: Homo Sapiens
name:
first: Jane
last: Doe
minimum: 1ここでは#Spec定義がなく、minimumの値がデフォルト値になっていることがわかります。
package識別子はファイルのパッケージを定義します。これにより、単一の構成を複数のファイルに分割できます。CUEでは、次の2つのファイルは、このセクションの最初の例と同等であると解釈されます。
// def.cue
package example
#Spec: {
/* snipped */
}// val.cue
package example
spec: #Spec & {
/* snipped */
}またCUEには、stringsパッケージなどの標準パッケージ、あるいはユーザーが作成したパッケージなど、他のパッケージをインポートする機能もあります。
なぜCUEを選んだか
一般に、Kubernetesマニフェストには、あらゆる種類のサービスで多くの定型的な構成が必要です。また、security contextやHorizontal Pod Autoscaler(HPA)のように、サービスを安全にしたり効率的に実行するための構成も必要です。
CUEには、デフォルト値を設定し、指定された値を検証するための仕組みがあります。これはKubernetesマニフェストをシンプルにするのに適しています。例えば、CUEを使うことで、柔軟性を維持しながら、minReplicasがmaxReplicasの値を超えないようにHPAマニフェストを生成できます。また、提供された設定に基づいて、Istio sidecarをinjectするために必要なlabelを追加することもできます。
またCUEは、Go言語と組み合わせることも可能です。すべての標準KubernetesリソースはGoパッケージとして提供されているため、さまざまな種類のKubernetesリソースをサポートすることができます。加えてGo APIは、CUEファイルの高度なワークフローを作成するのに役立ちます。
CUEを使用すると、外部システムに依存せずに全てをローカル環境で実行できるため、バリデーションや生成がすべてクライアントサイドで実行できます。Kubernetesエコシステムのツールやシステムはwebhookを代表とするサーバーサイドの通信を要求するものが少なくありませんが、これはフィードバックを遅くし、トライアンドエラーの制約になります。これらの特徴によって、シンプルな設定と発展的な設定、さらにはリソースのデプロイ方法といった、すべてのユースケースを満たすことができます。CUEは、KustomizeやHelmよりもはるかに表現力があるにも関わらず、中心的なパッケージは保守しやすくなっています。
また、IstioやDaggerなどの一部のプロジェクトでは、すでにCUEを導入済み、あるいは導入を検討している状態です。
k8s-kitの詳細
基本構成
前述のように、k8s-kitはCUEによって実装され、開発者にマニフェストのインターフェイスをCUEで提供します。
最も単純な構成の例は次のようになります。
package kubernetes
import (
"github.com/mercari/kubernetes-kit/pkg/kit"
)
Metadata: kit.#Metadata & {
serviceID: "reviews"
}
App: kit.#Application & {
metadata: Metadata
}
Pipeline: kit.#Pipeline & {
metadata: Metadata
}
Delivery: app: kit.Delivery & {
pipeline: Pipeline.pipeline
resources: App.resources
}Applicationで上記のように複数のKubernetesリソースを生成します。そして、このシンプルな構成は、執筆時点で200行以上のYAMLを生成します。
以下に、各フィールドと式の意味を、定義順に説明します。
kit.#Metadata: さまざまなメタデータを定義します。デフォルトを設定し、labelやannotationなどのさまざまな種類の値を検証するために使用され、かつ他の定義から参照されます。serviceID: サービスを指すメルカリの内部ID。これは、環境ごとに単一のKubernetes namespaceとGCP Project IDに対応します。このキットは、サービスIDを内部でKubernetes Namespaceに変換します。この例のNamespaceはreviews-prodとreviews-devであり、本番環境と開発環境に2つのクラスタがあると想定しています。
kit.#Application: Kubernetesクラスタ上のサービスの構成を定義します。Deployment、Service、(Horizontal)PodAutoscaler、PodDisruptionBudgetなどのKubernetesリソース構成を生成します。提供された設定に基づいて、多くの適切なデフォルトがあります。kit.#Pipeline: デリバリーパイプラインを定義します。執筆時点では、主にSpinnakerを使用してリソースをデプロイしているため、Spinnakerパイプライン構成を生成しています。kit.Delivery: デプロイするリソースとそのデプロイ方法を定義します。この例では、Spinnakerパイプラインを指定していますが、ArgoCDやkubectlコマンドなどにも対応しています。DeliveryはKubernetesリソースの最終的なアウトプットになり、カスタムCUEコマンドによって消費されます。
kit.#Applicationのスキーマは次のようになります。
package kit
#Application: {
#Base // Base configuration including #Metadata.
spec: {
#PodSpec
// Application's Docker image name, excluding the image registry prefix.
image: mercari.#Name | *metadata.name
// Minimum number of replicas, as a percentage, that must be available.
minAvailable: string & =~"^([1-9]%$|^[1-9][0-9]%$|^100%)$" | *"50%"
// Scaling configuration.
scaling: #ScalingType
}
patch: {
// Patching arbitrary fields.
}
}上記のスキーマは、ここで省略している他の定義に大きく依存するため、各フィールドの意味を完全に理解する必要はありません。 #Applicationとそれに依存する定義により、デフォルトが設定されて値が検証されるため、ユーザーは要件に基づいて必要なパラメーターのみを指定することに集中できます。
マルチクラスタのサポート
他のツールとは異なり、k8s-kitは最初期からマルチクラスタ構成をサポートするようにデザインされています。アプリケーションがデプロイされるクラスタは、Metadata内で定義されます。
Metadata: region: "tokyo" // or "osaka"上記はCUEのshorthandを使用しています。この例では、"tokyo"を指定すると、Kubernetesリソースがtokyoリージョンにあるクラスタにデプロイされます。
柔軟で直感的なディレクトリ構造
同じパッケージに属するすべてのファイルは、最終的にはmergeされるため、ディレクトリ構成に制限はなく、Kustomizeのような依存先ファイル/ディレクトリを指定する必要もありません。
設定の重複をできるだけ避けるためにPlatformでは次のようなディレクトリ構成を推奨していますが、各開発者は任意のディレクトリ構成を採用できます。
apps/reviews
├── development // dev specific
│ ├── kubernetes.cue
│ ├── osaka // dev’s osaka cluster specific
│ │ └── kubernetes.cue
│ └── tokyo // dev’s tokyo cluster specific
│ └── kubernetes.cue
├── kubernetes.cue // common to all env/cluster
└── production
├── kubernetes.cue // prod specific
├── osaka // prod’s osaka cluster specific
│ └── kubernetes.cue
└── tokyo // prod’s tokyo cluster specific
└── kubernetes.cue子ディレクトリ以下のマニフェストは親ディレクトリ以下のマニフェストにmergeされます。
カスタマイズ
ここまでk8s-kitの基本について説明してきたので、次はより実践的な例を紹介します。
1. 抽象化定義を設定をする
以下の例では、各サービスに固有の設定をカスタマイズする方法を示しています。
App: kit.#Application & {
metadata: Metadata
spec: {
expose: grpc: port: 5000
scaling: horizontal: {
minReplicas: 3
maxReplicas: 10
}
}
patch: service: metadata: annotations: foo: "bar"
}この例では、DeploymentとServiceのポート番号を指定し、HPAのデフォルト構成を上書きして、annotationにパッチを適用します。k8s-kitは、開発者が設定を簡単にカスタマイズし、上記のようにほとんどの値を柔軟に変更できるように設計されています。
2.リソースの追加
この例では、リソースを追加する方法を示しています。
Ingress: kit.#Ingress & {
metadata: Metadata
spec: {
domain: "mercari.com"
hosts: reviews: "/*": {
service: App.metadata.name
port: App.spec.expose.http.port
}
}
}
Delivery: app: kit.Delivery & {
pipeline: Pipeline.pipeline
resources: App.resources + Ingress.resources
}他のオブジェクトのフィールドを参照することでフィールド値を設定できるため、重複を回避できます。
3.複雑な設定をシンプルに実現する
次の例は、Istio関連の構成を実行する方法を示しています。
App: kit.#Application & {
metadata: Metadata
spec: networking: serviceMesh: {}
}CUEのこのたった1行により、k8s-kitは sidecar.istio.io/inject: "true"ラベルの他、多数のIstio アノテーションと適切なデフォルト値、DestinationRuleやVirtualServiceなどの特定の種類のリソースの構成の生成を可能とします。Istio関連の構成は、サービスメッシュを構成するために必要ですが、正しく理解して構成するのが最も難しいものの一つです。k8s-kitを使用すると、開発者はIstioの詳しい知識がなくても簡単かつ適切にセットアップをおこなうことができます。
スクリプト機能
k8s-kitはCUEのスクリプト機能を利用することでより使いやすくなるように実装されています。私たちの実装しているカスタムコマンドは、CUEで記述された設定を読み取り、そのデータを使用して処理を実行します。
基本的に、k8s-kitによって提供されるコマンドは、Deliveryの出力を受け取り、そのデータに基づいて何をするかを決定します。例えば、dumpコマンドはマニフェストをYAML(JSONなど他フォーマットにも対応)形式で出力します。
$ cue dump ./apps/reviews/production/tokyo/…
apiVersion: apps/v1
kind: Deployment
metadata:
name: reviews
namespace: reviews-prod
labels:
app: reviews
app.mercari.in/name: reviews
app.mercari.in/part-of: reviews
topology.mercari.in/environment: production
topology.mercari.in/region: tokyo
version: main
clusterName: tokyo
// …コマンドの簡略化された実装は次のようになります。
package kubernetes
import (
"encoding/json"
"encoding/yaml"
"list"
"strings"
"tool/cli"
)
command: dump: cli.Print & {
var: {
format: "json" | *"yaml" @tag(format,type=string)
kind: string | *"" @tag(kind,type=string)
name: string | *"" @tag(name,type=string)
}
_kinds: [ for k in strings.Split(var.kind, ",") {strings.ToLower(k)}]
_resources: {
for k, v in Delivery if var.name == "" || var.name == k {
"(k)": [ for r in v.resources if var.kind == "" || list.Contains(_kinds, strings.ToLower(r.kind)) {r}]
}
}
if var.format == "json" {
text: json.MarshalStream([ for v in _resources {v}])
}
if var.format == "yaml" {
text: yaml.MarshalStream([ for v in _resources {v}])
}
}これにより、Deliveryが(json|yaml).MarshalStreamに渡され、指定された値が(JSON|YAML)の形式で出力されます。
これはほとんどのサービスでは問題ありませんでしたが、いくつかのエッジケースではパフォーマンスの問題があり、また複数のリポジトリに同じパッケージを配布するのは困難です。そのため、flowパッケージを使用してCUE用のGo APIを使用するようにCUEスクリプト機能を移行しています。詳細な仕組みはこの記事では割愛します。興味のある方は公式ドキュメントをご覧ください。
まとめ
このプロジェクトにより、開発者はアプリケーションをより速く、より確実性を持って開発できます。プロジェクトはまだ開発中ですが様々な機能を追加しながら利用サービスを増やしており、今後の記事でもプロジェクトの進捗や成果を発信していきます。
別紙
CUEについてさらに学ぶためのリソースをリストアップしたので、CUEに興味をお持ちの方はぜひご覧ください。
ドキュメント・ソースコード
ブログ投稿(英語)
ビデオ(英語)
- Hands-on Introduction to CUE
- CUE: a data constraint language and shoo-in for Go
- Better APIs with Shareable Validation Logic
採用情報
Platform DXチームは、Platform Engineeringによって開発者体験を向上させることをミッションにしています。私たちと一緒に仕事をすることに興味がある方は、ぜひ以下からご応募ください。




