※本記事は2022年1月21日に公開された記事の翻訳版です。
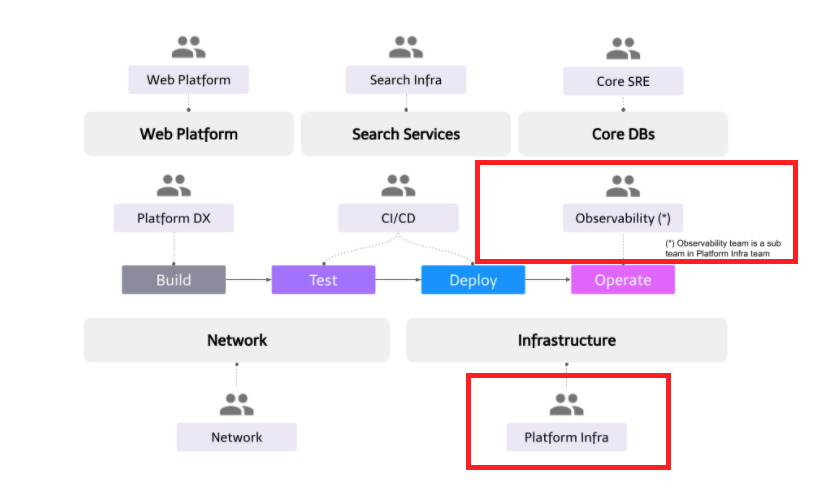
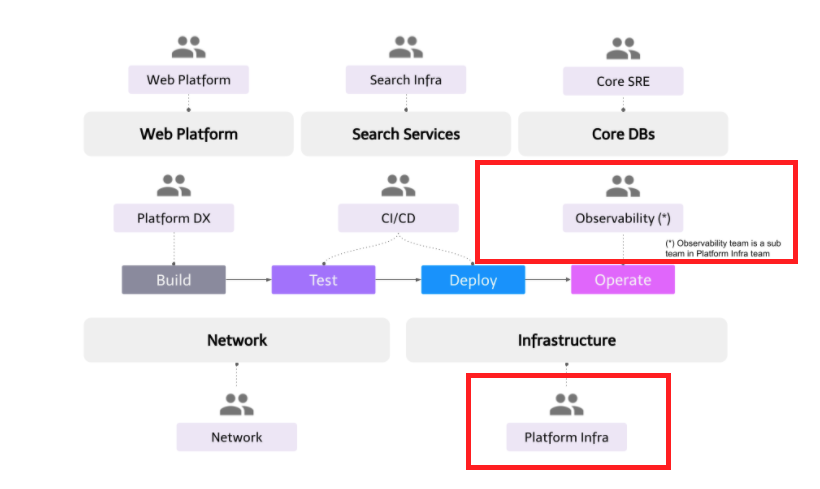
Platform Infraチームは、Developer Productivity Engineering Campの中でも、主にクラウドインフラとオブザーバビリティ(可観測性)の2つのドメインを担当しています。このブログでは、Platform Infraチームのミッション、主要な責任、そして今後の取り組みを紹介します。
ミッションおよび主な目標
Platform Infraチームは、次のキャンプミッションを共有しています。
- ツールとインフラで構成される内部開発者プラットフォーム(IDP)を提供し、開発者が安全で信頼性が高くスケーラブルな方法でバックエンドサービスを構築、テスト、デプロイ、運用できるようにする。
- チームが追加のオーバーヘッドなしで完全なエンドツーエンドのサービスのオーナーシップを得られるような、最先端の開発者体験を提供する。
このミッションを実現するために、 Platform Infraチームには次の目標があります。
- Declarative Configuration(宣言的設定)でクラウドインフラを安全に管理するためのツールとサービスを提供する。
- コンテナワークロードを安定して実行するためのスケーラブルなインフラを提供する。
- 本番サービスを運用および監視するために必要なツールを提供する。
- 開発者と管理者がデータドリブンの意思決定を行えるようにするために、ソフトウェア開発統計を時系列データで提供する。
主な責任
Infrastructure as code (IaC)
Platform InfraチームはTerraform Cloudと同様の社内サービスを提供し、さまざまなチームがDeclarative Configurationでそれぞれのインフラを安全に管理できます。すべてのTerraform構成は一元化されたGitHubモノレポに保存され、各マイクロサービスに専用のフォルダーがあります。この投稿を書いている時点で、このサービスでは1000以上のTerraform stateが管理され、1日に300以上のTerraform applyジョブが実行されています。主な機能には次が含まれます。
- Terraformワークフロー(GitOps): 新しいインフラの変更を行うために、開発者はプルリクエストを作成し、プルリクエストコメントで
terraform planの結果を確認できます。プルリクエストがCodeOwner(マイクロサービスの所有者)によって承認されると、開発者はそれらをマージできるようになり、terraform applyがリモートで実行されます。 - サンドボックス環境: 各Terraformの実行はサンドボックス環境で実行され、そのフォルダー(またはマイクロサービス)に固有のクレデンシャルにのみアクセスできます。これにより、マイクロサービスを跨いだクレデンシャルの漏えいを確実に防ぎます。詳細な実装については、@dtan4によるフォローアップ投稿で説明します。
- Terraformモジュールのサポート: モノレポ内ではさまざまなチームがそれぞれのTerraformモジュールを管理できます。モジュールのリリースとバージョン管理がサポートされています。たとえば、Platform Developer Experienceチームは、新しいマイクロサービスと開発者チームを構築するための
microservices-starter-kitモジュールとteam-kitモジュールを提供しています。これらのモジュールでは、GCP Project、GKE Namespace、Spinnakerパイプライン、ネットワークポリシー、GitHubチーム、PagerDutyスケジュールなどのリソースが作成されます。 - ガードレールとLint: ポリシーの作成にはConftestを使用します。これを使用して、マイクロサービスの許可リストとブロックリストを作成し、使用できるリソースと使用できないリソースを制限できます。また、モノレポ内のコーディングと命名の規則を保証するためのさまざまなbashベースのlint関数もあります。
Kubernetesクラスタの管理者
マルチテナンシークラスタパターンに従い、開発と本番の各環境に1つのGKEクラスタがあります。マイクロサービスは「テナント」ユニットと見なされ、マイクロサービスごとに専用のKubernetes Namespaceを作成します。Namespaceのオーナーシップはマイクロサービスオーナーチームが取得します。この投稿を書いている時点で、本番環境では300以上のマイクロサービスが実行されています。Platform Infraチームは、これらのクラスタの主なオーナーおよび管理者で、クラスタの信頼性とスケーラビリティを確保する責任を持ちます。主な責任には次が含まれます。
- クラスタのアップグレード: GKEの自動アップグレード機能を使用する代わりに、クラスタのアップグレードを手動でスケジュールし、すべてのテナントが後方互換性のないアップグレードに必要な変更を加えていることを確認します。また、まず開発クラスタをアップグレードして、1週間観察してから本番環境をアップグレードします。
- ゲートキーピング:マルチテナントのKubernetesクラスタでは、テナント間のセキュリティを確保するために、必要なすべてのガードレールを設定することが非常に重要です。これにはOPA Gatekeeperを使用していますが、ポリシーについてはこのブログで説明しています。
- 信頼性: Datadogを使用してクラスタの状態を監視します。GKE監視戦略についてはこのプレゼンテーションで詳しく説明しています。
- リソースの最適化: コスト効率の確保は重要な責任の1つで、ノードプールマシンの仕様の最適化やその他の調整によって、スケジュールされていないリソース(クラスタ容量 – リクエストされたリソース)を最小限に抑えようとしています。また、クラスタのダウンスケーリングを最適化するためにdeschedulerを導入するPoCも行っています。さらに、開発者には、デプロイ時にHPAとリソースリクエストを調整することによってリソースを最適化するためのガイドラインを提供しています。
- システムコンポーネント: Sysdig、カスタムFluent Bit、Datadog、Cert-manager、HashiCorp Vault、Velero、Telepresenceなど、システムコンポーネントは他にも多数あります。コンポーネントのメンテナンスとその信頼性の確保も、Platform Infraチームの領域に含まれます。
マイクロサービスの可観測性
メルカリは、ほとんどの可観測性要件(メトリクス、ロギング、トレース)にDatadog を使用しています。プラットフォームとしての私たちの主な責任は次のとおりです。
- Datadogエージェントのメンテナンス: エージェントは各ノードにDaemonsetとしてインストールされます。安定性を保証してパフォーマンスを調整することは、主なタスクの1つです。また、パフォーマンスはノードプールマシンの仕様に基づいて大きく異なるため、Daemonsetをノードプールごとに構成します。
- コードとしてのDatadog: 現在、ほとんどのダッシュボードとモニターはUIから手動で作成されています。ダッシュボード全体の整合性が失われるため、これは大きな問題です。私たちは、開発者が最小限のコードでダッシュボードとモニターを管理できるようにする、CUE に基づく抽象化フレームワークに取り組んでいます。フォローアップの投稿で、@harpratapがこのフレームワークとCUEのパフォーマンスについて説明します。
- コスト管理: 特に何百人もの開発者が直接使用している場合、Datadogのコスト管理は非常に面倒になることがあります。単純な構成ミスが、ロギングとカスタムメトリクスでの何万もの余分な支出につながる可能性があります。これは苦い経験を通して学んだことです。Datadogの使用自体のカスタムメトリクスの作成を開始し、それらをコスト管理の監視に使用しています。
Datadogログの保持期間は7日間なので、リアルタイムのトラブルシューティングにのみ使用されます。長期的なログの保持には、GCP BigQueryを使用します。Fluent BitのカスタムDaemonsetを使用してログをGCPロギングAPIに送信し、ログシンク機能を使用してさらにログをBigQueryにディスパッチします。
ソフトウェア開発統計
これは私たちが始めたかなり新しい取り組みで、社内ではdevstatsと呼んでいます。このプロジェクトの基本的な考え方は、データドリブンの意思決定には、まずデータが必要であるということです。すべての開発活動に関連するデータを時系列形式でリレーショナルデータベースに提供し、devstatsユーザーが次のような質問に対する回答を得られるようにすることが、このプロジェクトの目標です。
- サービス、チーム、キャンプのDDD(Accelerateからの1日あたりの開発者ごとのデプロイ)とその経時的な傾向は?
- ネットワークポリシーを使用しているサービスの数は?
- アクティブなマイクロサービスと開発者の比率が最も高いキャンプ/チームは?
- サービス/チーム/キャンプあたりの計算と可観測性のコストは?
このレベルの可視性を獲得できると、経営陣はデータドリブンのアプローチに基づいて、組織的および技術的により適切な意思決定を行うことができます。
実装に関しては、devstatsではさまざまなデータコレクターがmicroservice-starter-kit、team-kit、Spinnaker、Terraform-ci、Kubernetes-ci、PagerDuty、GitHubなどのさまざまなソースから定期的にデータを収集し、BigQueryテーブルにダンプします。その後、devstatsのアグリゲーターがこれらすべてのデータを定期的に(現在は1日1回)集約し、マイクロサービスのservice_idでマッピングして、「service_stats」テーブルに保存します。このテーブルの各行には、所有者リスト、チーム、キャンプ、インシデント、デプロイメントなど、特定の日付のサービスに関する完全な情報が含まれています。このdevstatsを使用すると、時間の経過に伴う傾向を分析できます。
ほとんどの分析では「service_stats」テーブルを使用するだけで済みます。DataStudioまたは他の同様のサービスを使用してカスタムダッシュボードを作成することもできます。
今後の取り組み
私たちのバックログには、新しくやりたいことがいっぱい詰まっています。Devstatsの他に、私が非常にエキサイティングだと思う新しい主要な取り組みをを2つ紹介します。
マルチクラスタ
以前に述べたように、本番環境では単一のGKEクラスタを使用しています。これは過去4年間うまく動作しているのですが、スケーラビリティのハードリミットに達する前に、それに備えておこうと思います。現在のマルチクラスタの優先事項は次のとおりです。
- シングルリージョン/均質 (Homogeneous) クラスタ: 均質とは、すべてのクラスタが同一であって、同じワークロードを実行するということです。これにより、クラスタの操作の信頼性と全体的なスケーラビリティが向上します。Platformチームは、Istioなどのクラスタ全体のコンポーネントに対してカナリアリリースを行うことができるようになります。クラスタのマイグレーションは、はるかに簡単になります。 前回のマイグレーションは完了するのに6か月かかりました。
- シングルリージョン/異種 (Heterogeneous) クラスタ: 異種とは、クラスタが異なるワークロードを実行し、Namespaceが異なるということです。これらのクラスタは、セキュリティとコンプライアンスの理由によって厳格な隔離が必要なサービスに役立ちます。
- マルチリージョン/均質クラスタ: 主に災害復旧シナリオをサポートするためのものです。ほとんどのお客さまは国内にいらっしゃるので 、私たちにとって地理的遅延は大きな問題ではありません。
GKEは最近マルチクラスタイングレスやマルチクラスタサービスなどの新機能を導入したので、これらを活用して、マルチクラスタの要件を満たしたいと考えています。このプロジェクトの主な目標は、マルチクラスタの詳細を開発者から隠し、 開発者がマルチクラスタ環境をサポートするためだけに作業を複製する必要をなくすことです。これはすべて、プラットフォームツールで対応できるはずです。
これは、ネットワーク、CI/CD、プラットフォームDX、SREなどのさまざまなチームからの協力を必要とする大きなプロジェクトになります。マルチクラスタ環境をサポートするには、 各チームがそれぞれのツールを強化する必要があります。
可観測性v2.0
お気づきかもしれませんが、すべての可観測性要件がDatadogに大きく依存していました。最初はうまくいっていたのですが、マイクロサービスがDatadogを直接使用し、緊密に結合されているため、時間の経過とともにいくつかの中核的な問題が見えてきました。マイクロサービスとバックエンドツール(DataDog、Prometheusなど)の間にOpenTelemetryなどのコントロールレイヤーを導入して、プラットフォームとして、使用率をより適切に制御し、提供されたツールを使用して簡単に構成と変更を行えるバックエンドオプションを開発者に提供できるようにしたいと思っています。
求人情報
かつての小さなPlatformチームはPlatform Groupになり、今ではほぼ50人以上のエンジニアのキャンプ(部門)になっています。私たちは急速に成長しており、メルカリとそのすべての子会社に好影響を与えています。ワークフローの自動化を通じて開発者の生産性を加速するという私たちの基本的なミッションは、常に変わることはありません。私たちについてもっと知りたいと思われた方は、下記キャリアサイトから詳細を御覧ください。




