The 17 day’s post of Merpay Tech Openness Month 2020 is brought to you by @Liu from the Merpay ML team.
As today’s first post, @matchan talked about how machine learning is used in the fraudulent payment detection system (link). As the second one, I want to talk about how machine learning is used in Merpay to detect the chargeback, and its pipeline.
About Chargeback
A chargeback (CB) is a bank-initiated refund for a credit card purchase.
Typical reasons that result in a chargeback are:
- Technical: Expired authorization, non-sufficient funds, or bank processing error.
- Clerical: Duplicate billing, incorrect amount billed, or refund never issued.
- Quality: Consumer claims to have never received the goods as promised at the time of purchase.
- Fraud: Consumer claims they did not authorize the purchase or identity theft.
In this blog, we will be focusing on chargebacks in the Fraud category.
According to a survey conducted by JCA, in recent years, the rate of stolen card and card information (番号盗用) has been steadily on the rise. Hence, when we think of chargeback, we usually think it is due to a transaction paid by a stolen card or card information.
A chargeback happens in the following steps:
- The credit card (or the card information) is stolen.
- The stolen card is used to buy products on Mercari.
- The cardholder realizes the suspicious transactions and contacts the credit card company(usually a bank).
- The credit card company initiates a refund from Mercari and returns the money to the cardholder.
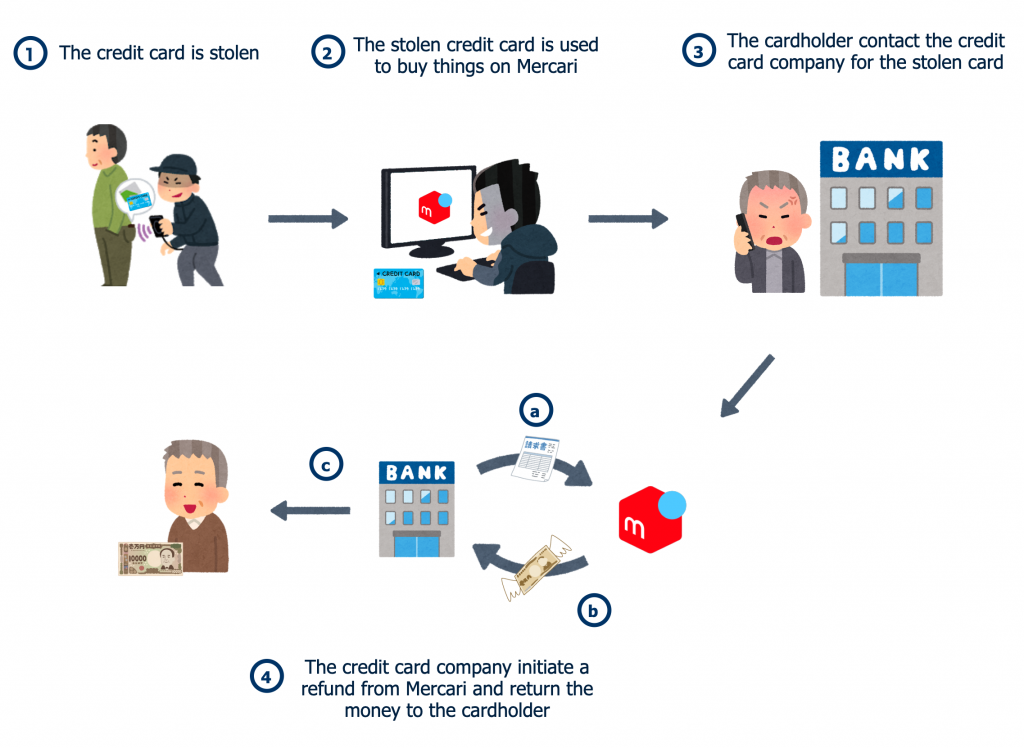
In the whole process, the best place to avoid the loss of Chargeback is to stop the transactions that are made by the stolen card immediately(step2).
Chargeback Detection based on Machine Learning Technique (CBML)

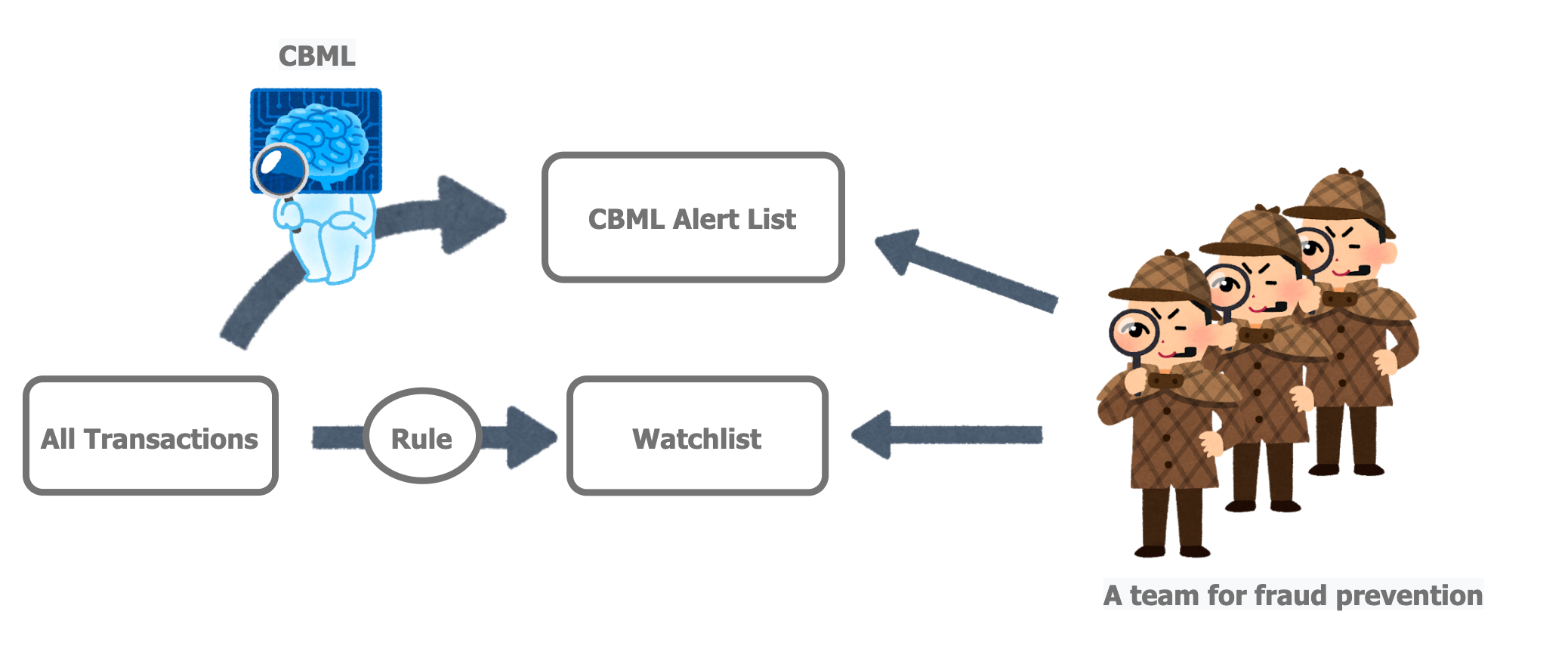
In Mercari, we have a team for fraud prevention for stopping various types of suspicious transactions, and chargeback is one of them. However, there is a problem: the team can’t look into every transaction since the amount of transactions is too large. Therefore, a rule-based model is used to create a Watchlist, a list of predicted chargeback transactions, and all the transactions in the list will be checked by the team. But another problem arises: there are still lots of transactions out of the Watchlist that turn out to be chargebacks So, our purpose is to find chargebacks out of the Watchlist using machine learning techniques.
To achieve the goal, we create a binary classification task to detect the CBs (chargebacks) from the normal transactions, and our project is called CBML.
Data Characteristics and Window
Through analyzing past data, we find out the data have strong time-series characteristics:
- If a CB happens, later transactions made by this buyer will have a high probability of being CBs
- It’s hard to tell a single transaction is CB or not even it’s made by card and has a high price
- But if a buyer buys several high-value items in a short time, it is pretty suspicious
Therefore, we present the per buyer transaction window.

For example, we use N days as our window length, then for each new transaction, we create a window to get all the transactions made by the same user in the last N days. The window is used to create several indicator features made by all the transactions in it.
By using the window, we obtained several powerful features to detect CBs.
System
The pipeline we use to implement the training-predicting process is Google AI Platform + Airflow.
AI Platform is an ML platform provided by Google, which integrates a toolchain for ML engineers to build and run the machine learning applications.
Training process
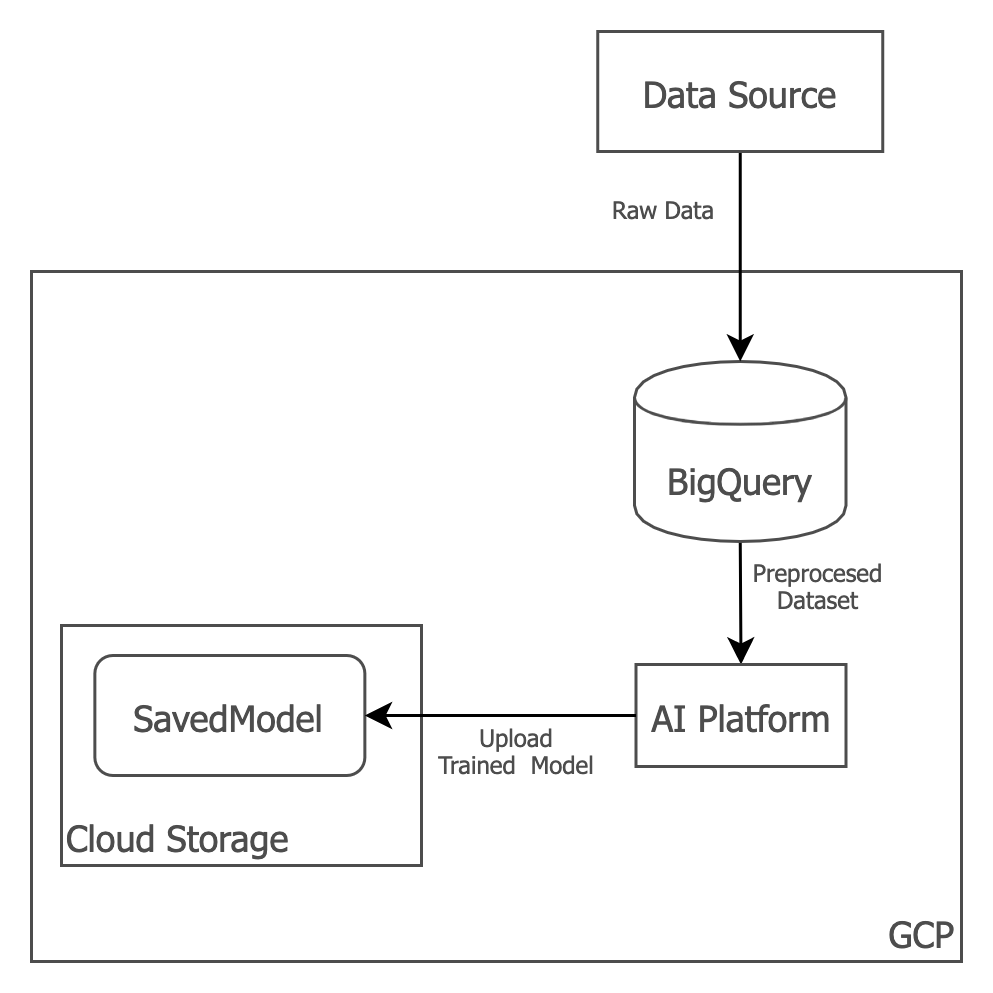
Process
- [BigQuery] preprocess data (Raw data → Preprocessed dataset)
- (This is where we create the window features)
- [AI platform] read the preprocessed dataset from BigQuery
- [AI platform] train model
- [AI platform] upload trained model to Cloud Storage
Here is the command we use to start a training job:
gcloud ai-platform jobs submit training ${JOB_NAME} \
--job-dir ${JOB_DIR} \
--package-path ${TRAINING_PACKAGE_PATH} \
--module-name ${MAIN_TRAINER_MODULE} \
--region ${REGION} \
--runtime-version ${RUNTIME_VERSION} \
--python-version ${PYTHON_VERSION} \
--scale-tier ${SCALE_TIER} \
--master-machine-type ${MASTER_MACHINE_TYPE}With AI Platform, it’s convenient to train the model. The packages are preinstalled by the platform, and the machine type can be changed whenever we need.
Predicting process

Process
- (Deploy trained model to AI Platform, only when deploy or update model)
- [Airflow] Read raw data from BigQuery
- [Airflow] Preprocess data (Raw data → Preprocessed dataset)
- [Airflow + AI Platform] Send an HTTP request with the preprocessed data to the AI Platform model’s API to get predictions for the messages.
- [Airflow] Save predictions to BigQuery
- [Airflow] Save results to the check system.
Future
The CBML has a long working interval now, but in the near future, we will have it work near-real time for a more timely detection.
As one of our final goals, we want to use CBML stop transactions that are suspicious not only for protecting our company from chargebacks, but also for protecting our society from credit card fraud.



