
This is @aymeric from Cross Border Engineering.
This article is part of the blog series Behind the Scenes of Developing Mercari’s First Global App, “Mercari Global App”
Introduction
The Mercari Global App represents the latest significant milestone in Mercari’s ongoing global expansion strategy. However, the translation of user-generated content, such as product listings on Mercari, predates this, commencing in October 2023.
Implementing translation capabilities led to a measurable increase in transactions by several percentage points, as demonstrated by A/B tests. This improvement occurred despite the availability of native browser translation features, highlighting the significance of integrated translation for user experience.
Over two years, the cost of translation dropped by 100x. Translation now costs Mercari 1% of what it cost two years ago, thanks to sharp decreases in Large Language Model (LLM) pricing.
This initiative initially aimed to boost sales of Mercari products through proxy partners exporting from Japan. It later evolved to support Mercari’s direct expansion into Taiwan in August 2024, eventually integrating with the Mercari Global Product.
DeepL and Google Translate offer classic translation services with pay-as-you-go APIs, high rate limits, low latency, and pricing based on the number of input characters. These services support a wide array of languages, covering all countries Mercari aims to expand into, and provide glossary support. This ensures consistent translation of specific terms, such as "メルカリ" to "Mercari" or "カビゴン" to "Snorlax," preventing phonetic translations like "Kabigon".
In contrast, LLM API pricing is based on input and output tokens, with differing costs and stricter rate limits for pay-as-you-go APIs, and higher response times. The input prompt significantly influences results and contributes to the overall input token cost. Language support is often vaguely documented, leading to occasional confusion between similar languages like Traditional and Simplified Chinese. Furthermore, LLMs currently lack glossary support and new models are released regularly while other models get deprecated.
This article recounts the trials and tribulations of this journey, from using a classic translation model to leveraging LLMs, the problems that we faced, and includes translation-related non-AI features.
Static content vs. user-generated content
To understand the complexities of item translation, it’s crucial to distinguish between static and user-generated content.

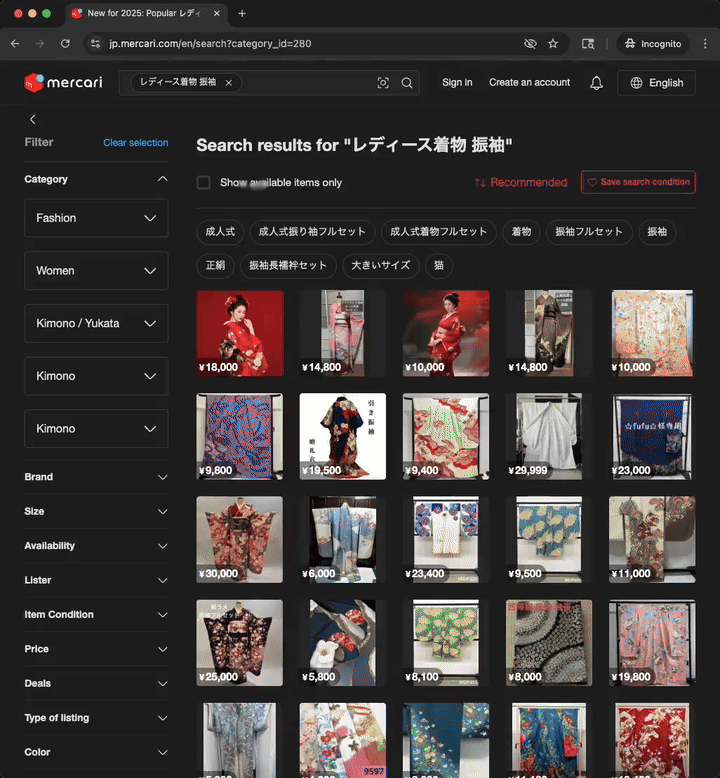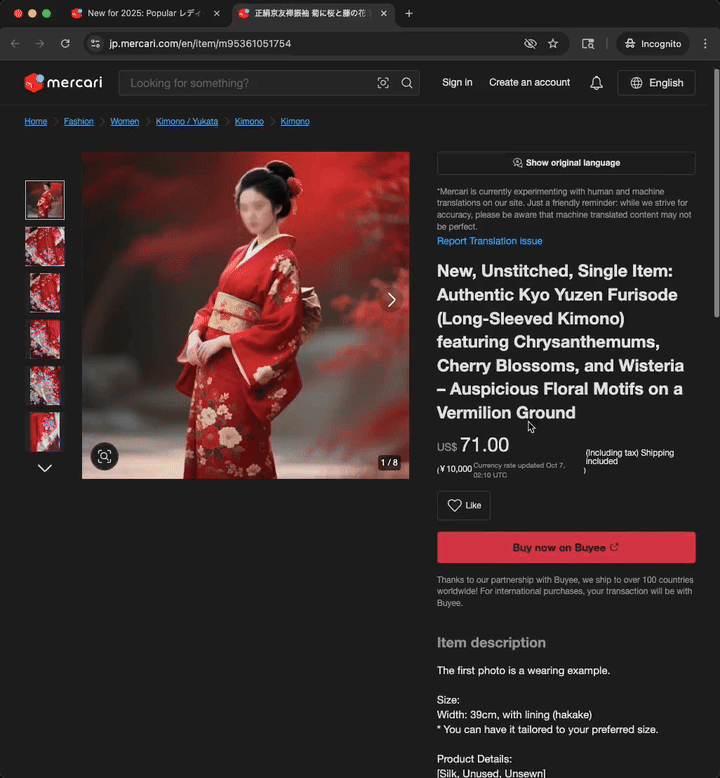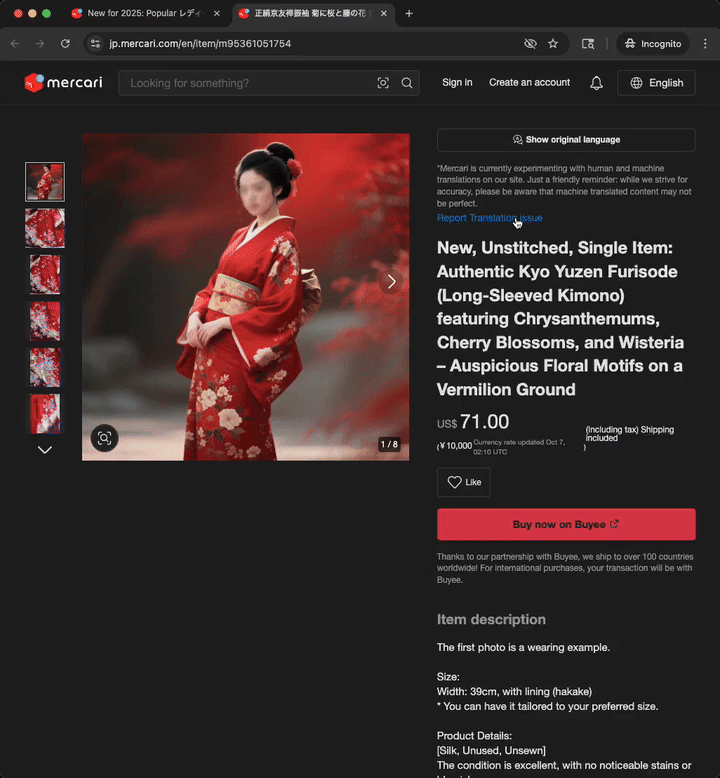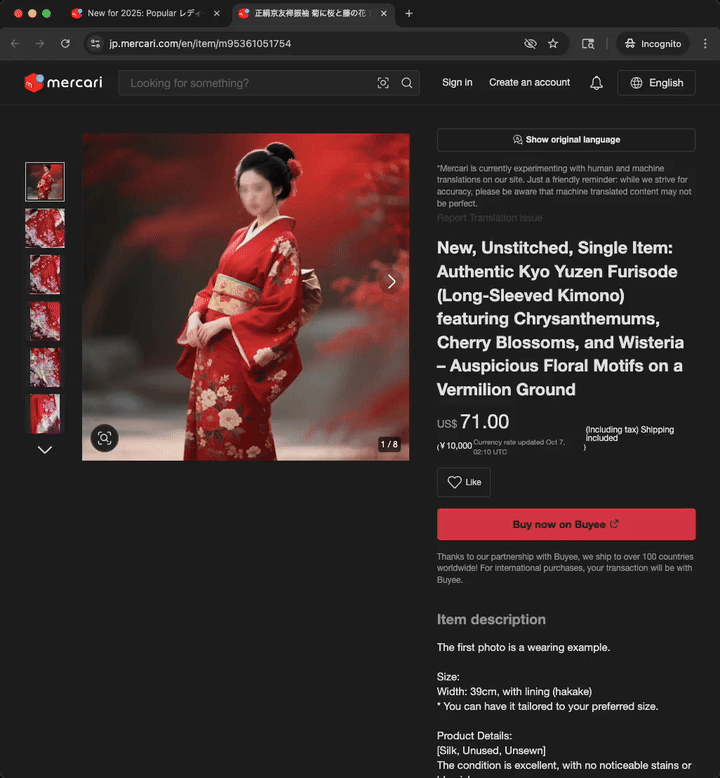
The image above is a Mercari product page. The title and description are “user-generated content”. The text was written by the user when they listed the item for sale.
Conversely, all other text elements on a product page—such as menus, section titles, button labels, and breadcrumb categories—constitute static content. These strings are created by Mercari and are stored directly within the codebase.
Other user-generated content includes the users’ profiles, comments on products, transaction messages, and user reviews after transactions end.
This article focuses specifically on the user-generated content.
The importance of understanding the product and users
In a Business-to-Consumer (B2C) model, a single product can be sold multiple times, allowing translation costs to be amortized across numerous transactions.
However, in a Consumer-to-Consumer (C2C) marketplace like Mercari, each product listing is unique. Consequently, the translation cost per transaction increases linearly with the volume of items listed.
Mercari covers both B2C and C2C models, yet the C2C inventory is a much larger volume than B2C.
As we started this initiative within Mercari Japan, all products are initially listed in Japanese then translated into multiple target languages. Currently, Mercari primarily focuses on English and Traditional Chinese translations, with plans to support additional languages in the future.
We considered and tested several strategies for translations:
- Translating all products when they are created
- Translating when users visit the product detail page
- Translating when users tap a button
- A mix of the above
This video presents the experience of a user visiting a product page that has never been translated before.
Translations are cached, eliminating the need for real-time translation during every user visit and improving page loading times for the next visits, as can be observed in the next video
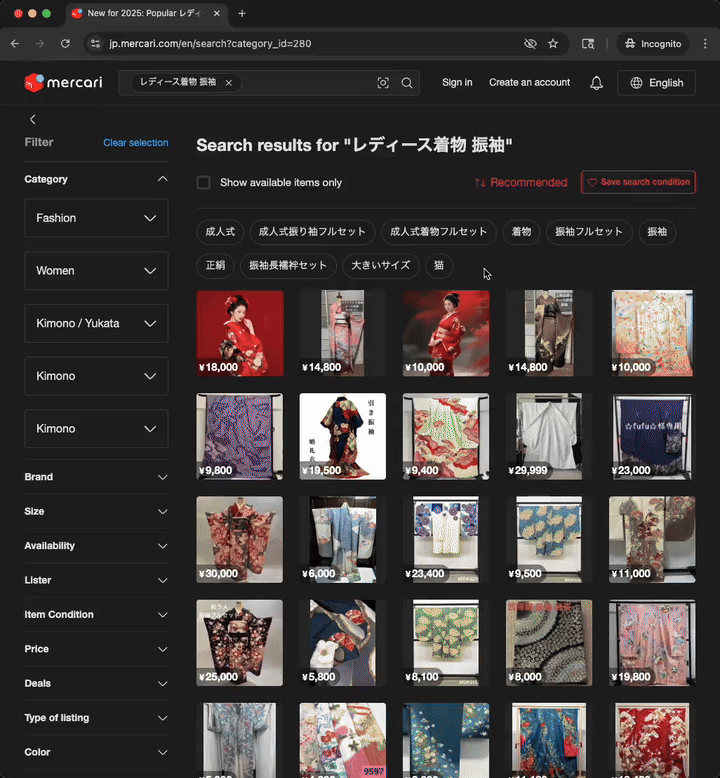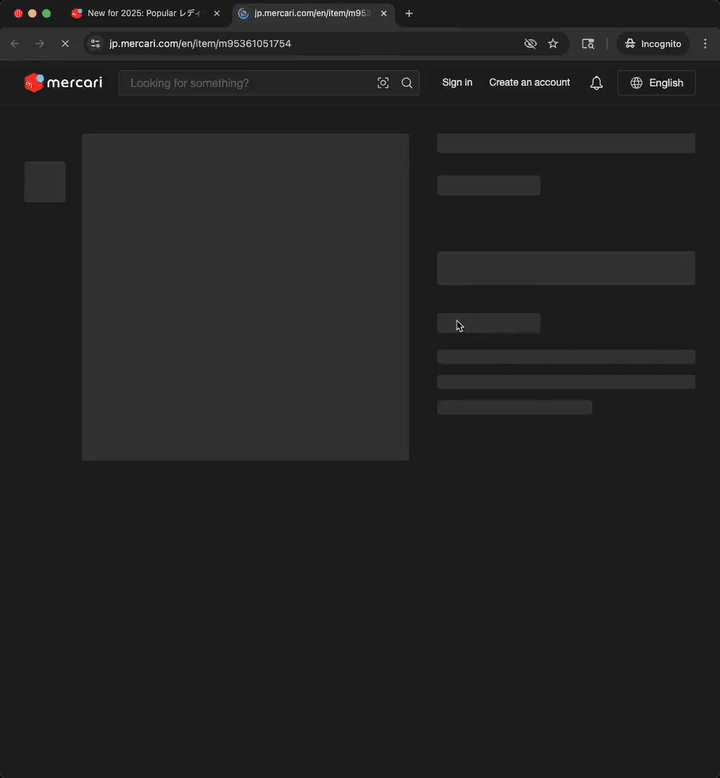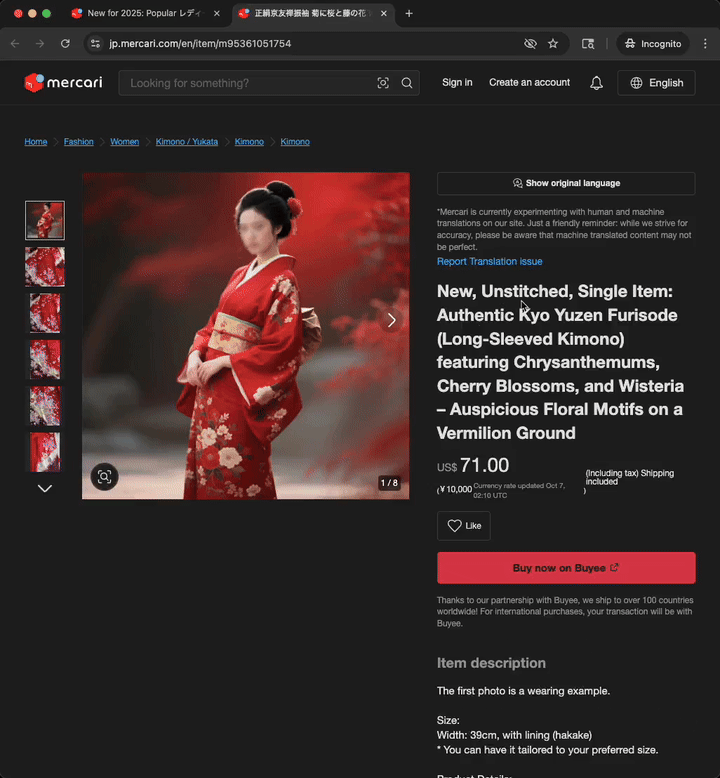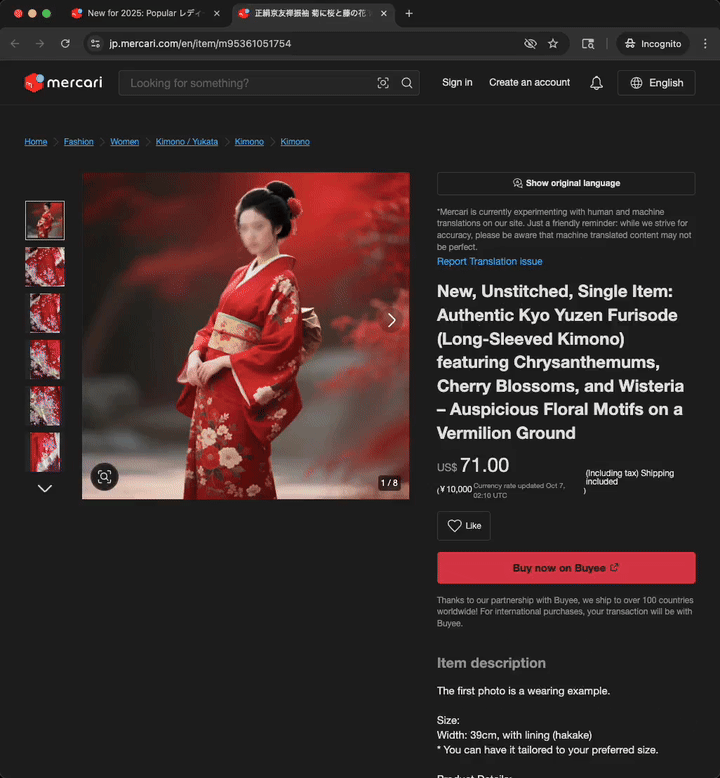
Initially, we considered translating all products at creation and storing these translations for quick retrieval. However, this approach faced challenges due to the need to support multiple languages and the fact that a significant number of products are never viewed by our smaller international user base.
Translating only when a user visits a product detail page introduces latency for the first visitor but is the most cost-effective solution. We experimented with a "translate" button on product pages, but low usage and declining metrics led us to abandon this option.
Product updates also presented a challenge. A small fraction of users frequently update their products, sometimes to manipulate search rankings. If all updates were translated, this behavior, by less than 1% of users, would increase translation costs by 25%. To mitigate this, we implemented workarounds: updates are time-boxed, with only the last update within a window being translated. Additionally, small updates, based on character count, are not translated.
This approach occasionally leads to customer issues, such as a customer receiving a garment of the wrong size because a one-character size update went untranslated. However, reimbursing customers for these rare occurrences is more cost-effective than investing weeks of engineering and API costs to eliminate them entirely.
We always provide the original text, allowing users to switch between translated and original content, a feature we emphasize to our users.
Marketing efforts, beneficial for product sales, introduce additional translation requirements. Traditional marketing platforms like Google Shopping, Google Ads, and Meta Ads have varying levels of built-in translation support. This necessitates translating products at creation for marketing purposes. Fortunately, marketing teams prioritize ROI, and are willing to cover the translation costs for relevant product categories within their budgets 😀.
The technical implementation details will be discussed in the next section.
Recounting the technical iterations
Integrating a classic translation model
We decided to use DeepL for our initial translation model. This involved:
- Automatically translating items when a user lands on the product detail page.
- Storing these translations for future use.
This approach led to a statistically significant 5.3% increase in buy tap rate.
We considered using ChatGPT and GPT-3, which had recently been released, but ultimately chose a reliable service known for its high-quality Japanese translations. LLMs API pricing at the time was pretty high, so there was no strong upside going with an LLM solution.
The DeepL public pricing of 25$ per million input characters has stayed constant over this period.
Our first LLM
The decreasing cost of LLM API pricing motivated our transition to an LLM-based translation solution. This move offered potential cost savings and valuable experience in deploying LLMs in a production environment. We went with GPT-3.5 Turbo-0125.
To manage costs effectively, and considering any prompt would be counted as input token, we developed a concise and straightforward prompt for the feature:
* Original text will be delimited by ###\
* Original text is in Japanese\
* Your task is to translate it to Traditional Chinese
###
<the product’s title or description>
This prompt proved effective for a considerable period and with various models, which we will discuss later.
At Mercari, product titles are limited to 40 characters and descriptions to 1000 characters, with averages of 25 and 300 respectively.
Initially, we aimed to provide a structured input containing both the title and description in the prompt and retrieve their translated versions from the output. However, this approach presented challenges. When users updated products, they often modified either the title or description, making it inefficient to always send both. This also necessitated a constant decision on whether to send the title, description, or both.
Upon testing, the results were inconsistent, and accurately and reliably extracting the translated title and description from mixed outputs proved difficult. Consequently, we ultimately decided to translate titles and descriptions separately.
The main issues noticed with this prompt and model were the translation of names, like anime character names like the pokemons, or celebrity names from famous Asian bands. It often translated the Japanese name to its phonetic form. カビゴン became Kabigon instead of Snorlax, which we could not be resolved without a glossary.
We had to drop the glossary we used with DeepL. Despite that, all metrics stayed flat in our A/B test, and cost decreased by ~20%.
While the prompt above can be easily bypassed, it has not presented an issue, as the original Japanese text is consistently displayed on listings by sellers in Japan.
 |
 |
How LLMs Scale
We leveraged Microsoft Azure to access OpenAI’s GPT models.
Due to initial low pay-as-you-go rate limits for LLMs, which were insufficient for our needs, we utilized Azure’s "Provisioned Throughput Units" (PTU). PTU offers pre-paid, reserved processing capacity on a monthly basis, with a minimum reservable unit of 50 PTU and scaling in multiples of 50.
Mercari’s user traffic fluctuates throughout the day in a predictable pattern: low activity at night, increasing in the morning, remaining relatively steady during the day, peaking in the evening, and then declining as the day ends.

When utilizing PTU (Provisioned Throughput Units), it’s essential to strike an optimal balance between the traffic covered by PTU and the traffic handled by pay-as-you-go capacity.
Over-provisioning PTU to manage traffic spikes can lead to significant wasted expenditure on unused capacity during periods of lower demand. Conversely, under-provisioning PTU will result in frequent encounters with pay-as-you-go rate limits, potentially disrupting service.
The diagram below illustrates this mechanism.

This blog post from Microsoft explains this in details very well.
The downside is that it makes the implementation more complex as the PTU deployment and pay-as-you-go deployment use different endpoints, and it requires the application to detect rate limitation errors on the PTU to decide to make requests to the pay-as-you-go endpoint.
New models, better pricing: Transitioning to GPT-4o mini
Over the past two years, the cost of LLM APIs sharply decreased. Regularly reviewing and switching models was key to cost savings.
The migration to GPT-4o mini was purely motivated by the cost improvements, decreasing the cost by 7x.
We didn’t modify the prompt and ran a quick A/B test that showed flat business metrics, guaranteeing this model could be used safely in production.
From GPT to Gemini
Mercari’s engineering teams primarily use Google Cloud Platform (GCP). Our initial work with Microsoft Azure for translation services, utilizing GPT-4o mini, introduced complexities due to the unfamiliar environment and the need to re-establish infrastructure as code, authentication, and other platform-related aspects.
As Gemini became available, we made the technical decision to transition to Gemini on GCP. At the time, GPT-4o mini and Gemini 1.5 Flash had comparable pricing.
Another great advantage of Gemini was its much higher rate limits on the pay-as-you-go API. This meant we did not need PTU anymore, or GSU as Google calls it, for Generative AI Scale Unit.
This would simplify the implementation.
By the time we prioritized this transition, Gemini 2.0 was announced. We still opted to A/B test using Gemini 1.5 Flash as the price was cheaper than the new Gemini 2.0 models.
The A/B test showed no significant difference in business metrics. Consequently, we deprecated the GPT-4o mini implementation, permanently discontinuing our use of Microsoft Azure for this service, and launched with Gemini 1.5 Flash.
The significant cost reduction was a pleasant surprise, potentially due to an initial underestimation of Gemini 1.5 Flash’s cost or a pricing update from Google with the release of Gemini 2.0.
This brought our total cost reduction to 100x compared to our initial implementation with DeepL.
Interestingly, Gemini 1.5 Flash is the only model we’ve encountered that prices by character rather than by tokens, unlike other large language models.
First model forced retirement
As already mentioned, new LLMs get released regularly. And model providers also deprecate models just as regularly.
Google documents the retired models in this page. So far, all models get deprecated a year after their release.
Gemini 1.5 was released in two stages, four months apart. We initially adopted the first release (001), and when it was slated for deprecation, we had the option to migrate to either Gemini 1.5 Flash 002 or Gemini 2.0 Flash Lite. Due to its lower cost, we opted for Gemini 1.5 Flash 002.
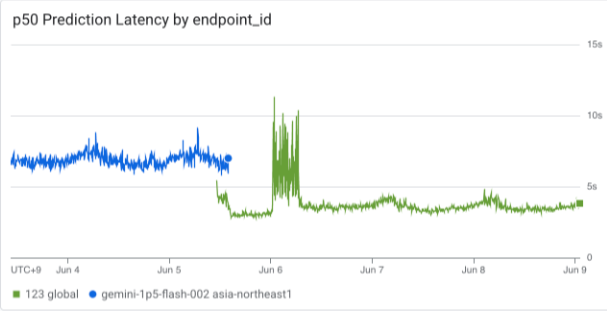
Given the tight deadline and the perceived similarity of the models, we decided against an A/B test to save time. This proved to be a misstep.
The diagram below illustrates the latency we observed within days, which negatively impacted the initial user experience for product pages undergoing their first translation.

After investigating with Google, and as many of their clients moved from 001 to 002, they also observed increased latency. As the model would soon get deprecated, all internal capacity was used for Gemini 2.0 models, and so we decided to move to Gemini 2.0 Flash Lite.
And another Gemini model
Gemini 2.0 Flash Lite was released without A/B testing. While this brought latency down, it never reached the levels achieved by Gemini 1.5 Lite 001.
We observed an immediate side effect: the majority of translations began with a statement from the model, such as "Here is the translation:".

This issue was quickly identified and resolved by modifying the initial prompt.
With the cost per token having dropped significantly, we could design a longer prompt and landed on the following:
You are a Japanese-to-English translation API.
1. **Task:** Translate the content of the user's tag.
2. **Output:** Your entire response MUST be the result, wrapped in tags. Add no other text.
<content of title or description>
On the plus side, it performed much better on character and celebrity names, though they still occasionally get mistranslated.
This model is currently used at Mercari for product translation. It is scheduled to be retired on February 25, 2026.
Translation experience is not just delegating to a LLM: Non-AI features
Automatically translate or let the user trigger it to save money?
From the start, we had decided users should always be able to see the original content. So, a button to switch between the original content and the translated content was provided.
In the initial release of the translation feature, content translation was automatically triggered when a user landed on the product detail page.
Curious about the opportunity to reduce the cost, we ran an A/B test where content was not translated, so the user had to tap the “show translation” button to trigger the translation.
The business metrics went down very slightly and we decided to keep the automatic translation trigger.
How we measure the user experience
Later, to better measure the user experience, beyond the business metrics, we decided to add a button to let users report issues in the translation.


The translation feature is designed for simplicity, requiring no additional user context. A client-side event is sent to and stored in the backend when the feature is used.
Initially, we were unsure about the usefulness of the feature due to the lack of context and whether users would engage with it meaningfully. To assess this, we conducted an A/B test. We sampled and reviewed reports, with the condition that the feature would be retained if over half of the reports were justified.
The results showed that users did not misuse the button, and most reports were deemed valid. This not only confirmed known issues like character and celebrity names but also brought to light some less frequent problems.
Based on these internal translation issue reports and the A/B test results, we compiled a list of known issues. This list then formed the basis for a simple offline evaluation method, allowing us to quickly and more effectively assess new translation models.
Resolving translation issues: Implementing the glossary
One of our latest developments involves implementing a glossary to address persistent issues with character and celebrity mistranslations.
Given thousands of glossary entries, passing the entire glossary as input to the Large Language Model (LLM) for every translation is impractical due to prohibitive costs and latency. Effectively using a glossary goes beyond simple substring replacement. For instance, サイ refers to a character in Naruto, while サイズ means "sizes". Longer sequences, like スポイルじいさん (Old Man Spoil from One Piece), also require consideration.
To accurately match words and sequences, we introduced tokenization, which can be resource-intensive. Fortunately, we leveraged our existing search system’s Japanese tokenizer. By combining the glossary with tokenization, we could precisely identify parts of the input text requiring proper translation.
Our initial strategy involved replacing matched glossary entries in the input text with their translated values and then sending this modified text to the LLM. For example:
- Original text:
サイはナルトの登場人物です - Intermediate text (after tokenization and replacement):
Saiはナルトの登場人物です - After LLM translation:
Sai is a character in Naruto
This approach proved effective for English. However, results for Traditional Chinese were significantly poorer. The primary challenge was the close similarity between Japanese and Traditional Chinese characters, which made it difficult for the LLM to distinguish between content that needed translation and content that should remain unchanged.
Consequently, for Traditional Chinese, we adopted a different strategy. Instead of text replacement, we provided the LLM with additional context in the prompt, specifically a list of key/value pairs to be used in the translation. This alternative method yielded significantly improved results.
Key takeaways and future work
Mercari’s journey in user-generated content translation highlights a commitment to Mercari’s values, driven by a deeply iterative approach, emphasis on user experience, and strategic model transitions.
Key to this success was balancing cost with user experience, understanding the unique challenges of a C2C marketplace, and integrating crucial non-AI features.
One important observation is that newer models have no impact on business metrics. Considering high-end models are over 10x the price of the cheaper models, it’s hard justifying using more high-end models.
While significant progress has been made, there remains room for improvement, particularly in achieving more accurate translations and reducing latency. Furthermore, the continuous evolution and eventual deprecation of LLM models necessitate ongoing adaptation to maintain optimal performance.
Additionally, more user-generated content will soon be translated, such as user profiles, user comments on products, and more.
Finally
Thank you for making it to the end.
Credits for the work go to Amit Raj Baral and Christophe Labonne.
On November 13, 2025, the Mercari Group tech conference "mercari GEARS 2025" will be held where I will be one of the speakers.
Please join us! Registration is here 👉 https://gears.mercari.com/
Tomorrow’s article is by @hatappi.
Please continue to enjoy Series: Behind the Scenes of Developing ‘Mercari Global App,’ Mercari’s First Universal App.




