Introduction
Hello, I’m @hiramekun, a Backend Engineer at Merpay’s Growth Platform.
This article is part of the Merpay & Mercoin Advent Calendar 2024.
While the Growth Platform is a part of Merpay, we are involved in various initiatives that extend beyond Merpay itself. One such project was the re-architecture of our item feed system. I will introduce the insights we gained from this initiative!
Background
An item feed is a data format and system for managing information from online stores and product catalogs, which is then distributed to various sales channels and advertising platforms. At Mercari, we connect our product data to various shopping feeds so our items can be displayed as ads, which is crucial in promoting products on external media.
For example, Google’s Shopping tab includes listings from numerous sites, including Mercari.

(Source: Shopping tab in Google)
Challenges
Historically, different item feed systems were independently created and managed by various teams, leading to several challenges:
- Each system had distinct teams responsible for implementation and maintenance, increasing communication costs.
- Although there are common processes, such as retrieving item information and filtering unwanted items, each team implemented them uniquely, resulting in varied issues across systems.
- Different systems used different data sources, leading to real-time delays in reflecting item status changes in the feed.
Goals
To address these challenges, we launched a new microservice dedicated to item feeds to provide a unified implementation for all collaborators within a single system. There was also the option of adding features to existing microservices owned by the Growth Platform. However, we decided to launch a new microservice for the following reasons:
- To prevent further complicating the roles of existing microservices, which are already extensive.
- To minimize the impact on other systems, the design must be adjusted to meet the distinct characteristics of each external service.
- Due to the high RPS of item renewal events, scaling according to system demands may be necessary.

Common tasks like filtering configurations, data retrieval, and metadata assignment should be integrated into a single system to ensure that updates are universally applied across services.
While core functionalities are consolidated, it’s crucial to maintain separate implementations for each external service’s unique needs. This separation allows new external services to be integrated with minimal adjustments. Requests made to external APIs must be adaptable to various endpoints and rate limits.
Error handling is also critical. Given the inevitability of encountering external API errors, a retry-capable design is essential to mitigate these potential issues.
Technical Approach
Architecture
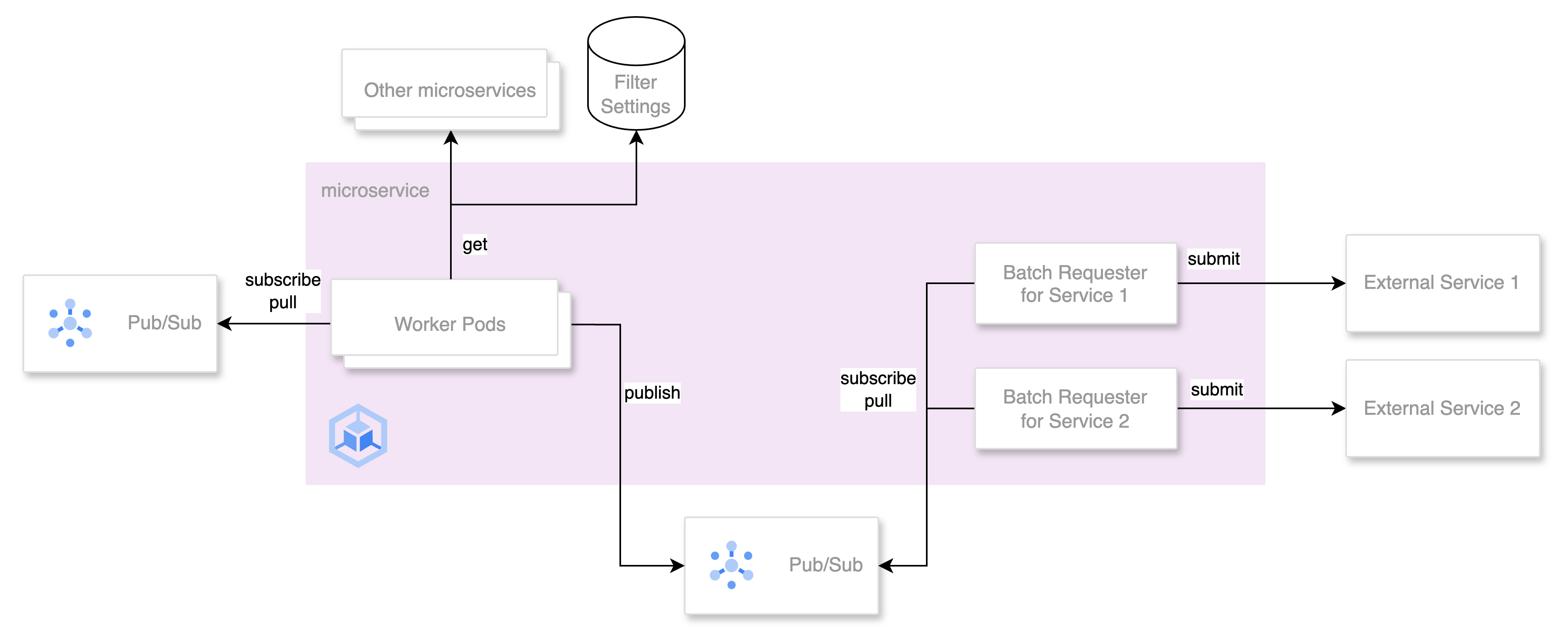
The following outlines the architecture. We split processing into workers for common tasks and those specific to linked services (Batch Requesters), connecting them via a Pub/Sub system. This architecture has several benefits:
- Allows scaling based on the specific requirements of each worker.
- Separates requests to internal microservices from external API requests to isolate unpredictable external API behaviors.
Adding a new batch requester as a subscriber to Pub/Sub can add new external services without altering existing common components. - In case of a surge in item status update events, the Pub/Sub Topic acts as a message queue to enhance system stability.

Let me share each worker in a little more detail.
Common Processing Worker
This worker subscribes to Pub/Sub Topics to receive real-time item status updates from other services. It performs common tasks like adding additional item data, filtering out unsuitable items based on the filter settings, and publishing the processed data to an internal Pub/Sub Topic.
Configured with Horizontal Pod Autoscaler (HPA), this worker dynamically adjusts the number of pods based on CPU usage.
Service-Specific Worker (Batch Requester)
Each batch requester is responsible for subscribing to the Pub/Sub Topic for feed-customized item information for its respective service. Because external API requests must be executed continuously on a second-by-second basis, we implemented these requesters in Go and deployed them as Deployments, not CronJobs. Deployments offer finer control over execution intervals and scalability.
Error handling is also essential. Since requests can fail due to temporary errors in external APIs or network errors, we have implemented a retry feature. This system utilizes the retry mechanism of Pub/Sub and features the following.
- The batch requester receives messages from Pub/Sub and stores them in memory as a batch.
- At regular intervals, the batch is sent to an external API.
- If the submission is successful, the system acknowledges Pub/Sub messages corresponding to all items in the batch.
- If the transmission fails, the system negatively acknowledges all corresponding messages and Pub/Sub will resend the message.
Since we want to reflect the status of items in the feed in real time as much as possible if a retry fails a certain number of times, it is forwarded to the Dead-letter topic, and subsequent requests are given priority.
As part of our service level objective (SLO), we monitor the percentage of products correctly reflected in the product feed. We are currently meeting this SLO, so there is no need for a job to retry processing the products accumulated in the Dead-letter topic. However, we might consider developing such a job in the future.
Conclusion
By building this item feed system, we can now distribute items to the feed in near real-time. Separating the common implementation from the specific implementation for each external service has also made it easier to add new services. We plan to add new services and customize feed data.
The next article is by @goro. Please continue to enjoy!



