Abstract
If a company wants to protect its attack surface, it first needs to know it, yet in many companies, there is no clear picture of what services are exposed to the internet. We have been working on a system to create a map of the company’s attack surface. There are many explanations of this process from the perspective of the attacker, but it turned out to be a very different process from the inside.
At Mercari, we currently allow a lot of flexibility to developers on what they deploy and how they deploy it, which means there is a large variety of places we have to check if we want to create a complete inventory. We attempted to create a system that requires minimal maintenance and contribution from individual developers while still granting good oversight of our infrastructure, weak points, and services we can deprecate. In the process, we gained a better understanding of our infrastructure and learned about the pitfalls of relying on IaC. We have also learned to embrace flexibility in designing a system that is mapping the unknown. When you plan to handle things you are just now discovering exist, your first plan will likely not be correct.
Security Philosophy
Before making a plan, I think explaining the security philosophy informing our design decisions is useful. We tend to prefer solutions that put the least burden on developers since the more efficient their work is, the more they can deliver on the product side. At the same time, we have to make solutions that scale to the size of a fairly large company.

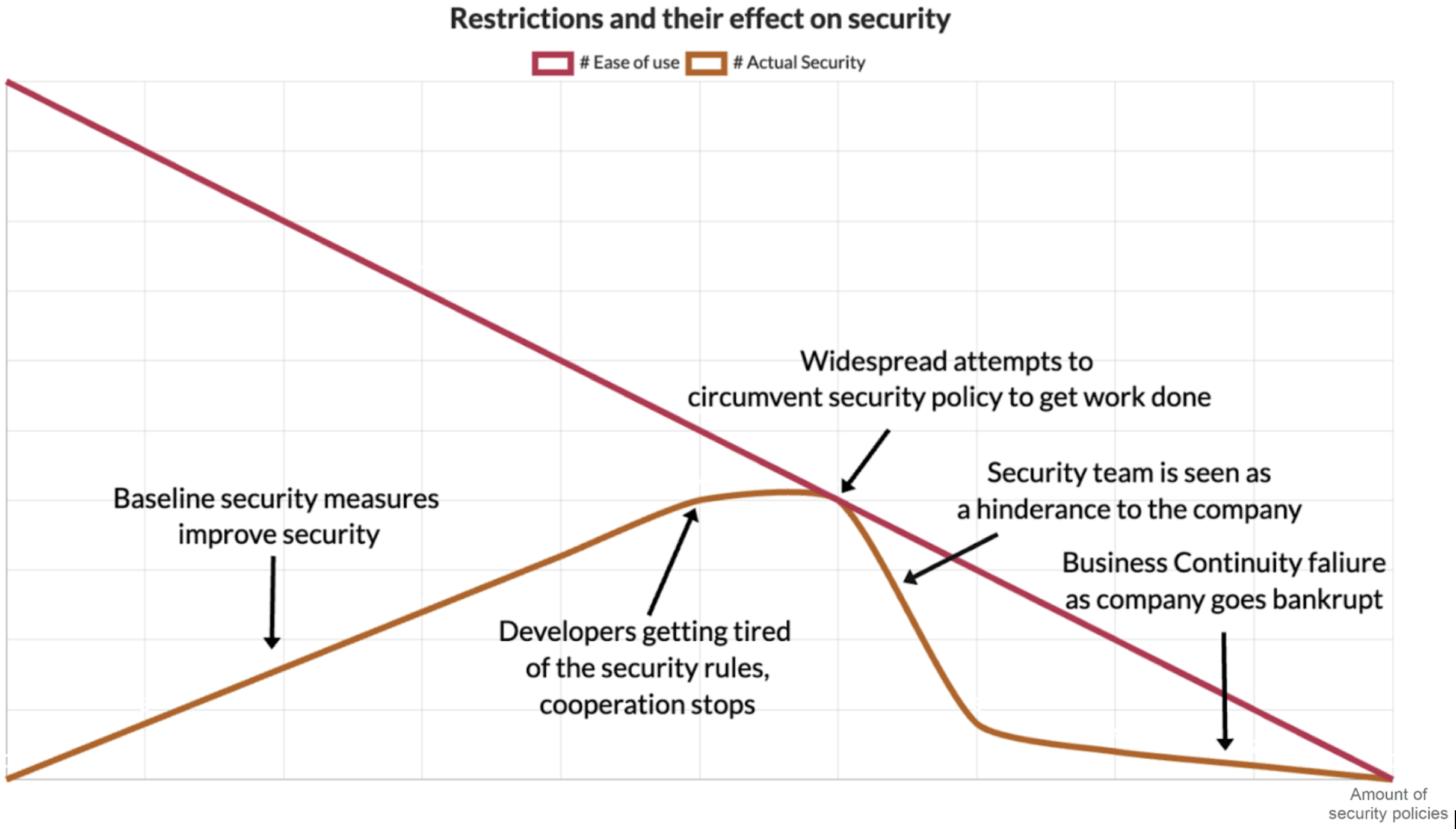
Kelly Shortridge wrote a blog post back in 2020 about the problems of over-doing and under-doing security that was very impactful for me. The problem with creating an overly strict security environment is that it suffocates the organization. Developers are bogged down by waiting on security reviews and prevented from using the latest and greatest technology.
The Managerial Security Mindset
Creating a rigid system is a really easy mistake for a security professional. If the job is to make everything secure, one can hardly be blamed for wanting control over everything. It is a managerial mindset in which the security team tries to guide secure development through restrictions, reviews, and fixed rules of what can and cannot be done in the company. The problem with this attitude is not only that no company has enough security engineers to manage absolutely everything but also its complete antagonism towards innovation.
Companies need to create things to make a profit, and if they want to stay ahead of the competition, they need to use the latest technology to create those things. In the managerial security mindset, everything outside of the mold is scary, full of unknown risks that will definitely destroy the company. In reality, developers experimenting with new solutions and project managers experimenting with new features are the things that propel the company forward. While most new technologies and ideas might not be great, if experimenting itself is made to be a burden, the company will stagnate, calcify, and will eventually go bankrupt by more innovative corporations delivering a better product faster, even if not quite as securely.
The Importance of Developer Attitude
It is also worth keeping in mind that if security processes become annoying and tiresome, their efficiency falls off a cliff. Most developers are interested in security and will willingly contribute to improving it, provided they aren’t hampered by excessive procedural hurdles. On the other hand, once the amount of security procedures becomes a hindrance, it will create an adversarial relationship between the security team and developers.
With these considerations in mind, our approach focuses on empowering developers by providing them with intuitive tools and clear security information. Instead of constraining their technological choices, we expand our visibility to understand and secure these technologies collaboratively.
Finding the Sweet Spot
Naturally, the reality is somewhere in the middle. Sometimes, restrictions are necessary, and some security burden has to be placed on the developers. I think an ideal security posture is not just halfway between complete rigidity and complete chaos. The sweet spot is constantly moving depending on market trends, technical innovations, and ultimately, what the business is trying to achieve.
Initial Plan
The original PoC for this project aimed at detecting new domains added to one of our sub-companies so they could be added to Burp Enterprise for periodic scanning. To achieve this, we simply have to parse the IaC repositories that contain the domains, and present the new ones to the team every week. Once a team member makes a decision, we can use the Burp Enterprise API to schedule scanning for the domain.
Implementing the Burp Enterprise API
At the time of creation, there was not much documentation on how to use PortSwigger’s Burp Enterprise API. There is a REST and a GraphQL API with different capabilities. The REST API is lacking a lot of features we need, since it is just a slightly changed version of the Burp Professional API. The GraphQL api provides most of the functionality we need, but there is no way to pin the API version and it is still under development, so we are risking features breaking on every update. Still, it is either the GraphQL API, or Selenium, so GraphQL it is. With a GraphQL API, we are expected to hand-craft the specific requests we want to use. Given the vague documentation, this seemed fairly time consuming.
Looking for an easier option, we’ve stumbled upon genqlient from Khan Academy. For the correctly formatted GraphQL schema, genqlient can create a go library accessing all the queries and mutations of that schema. It is not perfect, but after a bit of tweaking, it works fairly well. PortSwigger does not publish its schema, but the default installation allows GraphQL Introspection. During penetration testing, an attacker might use this to better understand the capabilities of the API. In this case we used it for the same reason, but we intend to legitimately use the API.
To create a complete introspection query, we used gqlfetch because it immediately formats the results into a standard format that can easily be converted to SDL. After you have the resulting SDL file, you can generate individual query and mutation files with gqlg
gqlg --schemaFilePath schema.graphql --destDirPath ./gqlg --ext graphql
The resulting ./gqlg folder will have a list of queries and mutations, from which you can select the ones you want to use. We simply copied the useful ones into the ./used_query_schemas/ folder and capitalized their name to make the corresponding Golang functions exported. Some of the files might be partially incorrect, for those cases you’ll have to rename some things or address errors as they arise.
go run github.com/Khan/genqlient
This will generate the Go library. If you tweaked the gqlg files correctly, this library should compile and export functions to interact with the API. You’ll also have to implement an authentication RoundTrip to add the “Authorization” header with the Burp API key.
After getting over that hurdle we tried using this solution for the first time.
We used a Slack bot to create a simple, interactive Slack message where knowledgeable team members could decide whether a domain should be scanned.
Initial Learnings
When we started to use this slack bot, a few things became clear. There are a lot of websites and a lot of new subdomains registered every week, making a decision on them still requires manual labor. It is often not obvious what a domain is used for, their names range from legible words to 12 character random strings. The sites hosted range from test sites to pages that simply respond with 404. Most of the websites are hosted by us, but some of them are handled by third parties that we should not scan. Most importantly, there are a lot more websites owned by the company than what we parsed so far. They can be found in a variety of different IaC repositories responsible for different departments, or CDN configurations. Some domains are simply defined directly in the cloud without any IaC and some services do not have a domain at all.
The tragedy of IaC
I mentioned that the approach of parsing IaC did not quite work out. This was not because we were unable to parse the fairly large number and variety of IaC repositories that all define different services. It was ultimately because IaC is simply inaccurate.

https://en.wikipedia.org/wiki/Allegory_of_the_cave#/media/File:An_Illustration_of_The_Allegory_of_the_Cave,_from_Plato%E2%80%99s_Republic.jpg
We spend a lot of time writing IaC code to define all kinds of resources, but half the time it does not work and sometimes it cannot work. For example, there are some features in GCP that the terraform provider simply does not support, or if it does, it is documented so badly that people will sooner give up and set it from the gcloud cli or on the web console. Every time that happens, a discrepancy between IaC and reality is created.
That is all to say, IaC is more of an approximation of the infrastructure, and less of a concrete definition. Of course, we do our best to ensure accurate IaC for critical infrastructure, but the things we are most interested in are anything but. We want to see accidentally published services in test environments, long forgotten infrastructure created before the widespread adaptation of IaC and the like.
Going to the Source
To solve the issues of IaC, we decided to switch to directly querying the asset inventory of the various cloud providers. Luckily, GCP, AWS and hopefully Azure (although we haven’t gotten that far yet) have their own inventory of what assets they are housing. This includes not only hosted zones and Route53 configurations, but also things like IP addresses, or ephemeral services such as GCP’s Cloud Run.
These are especially interesting, since they form part of the attack surface without requiring a domain or a dedicated IP address. In GCP there is both an “Asset Inventory” and a “Security Asset Inventory”, in which the security one seems to be easier to query. In AWS, you can use an AWS Config fed by an Aggregator to create a similar inventory. With this approach, we have a more complete picture that is also more accurate. Even if a developer bypasses IaC to create a domain or resource, we will be able to see it. In some cases we also get the user who created the resource, giving us a good idea on who to contact if we find an issue.
Visualization
After we set this collection system up, it quickly became clear that some visualization would make the data more useful. Questions like “which sites are reachable from the internet”, “Are these sites all protected by Identity-Aware Proxy (IAP)?” arose during development, which we could answer at a glance once we made screenshots of every site. We were also able to spot anomalies, like unexpected services being hosted, and domains that pointed to IP addresses that were now in use by other tenants in the cloud.
To do this, we have set up a Google Cloud Run (GCR) service that accepts a list of domains, and spins up chromium to take screenshots of them. Utilizing the automatic scanning of GCR, we batched the domains in a daily GCR job and spun up a few dozen instances to take all the screenshots in about 10 minutes.
We were also able to create connections between domains and IP addresses. This meant that we no longer had to manually review every domain before scanning. If we know that a domain points at an IP owned by our cloud tenant, we can simply add it to Burp Suite and wait for the results to roll in.
Conclusion
When starting the project it was only meant to be a way to automate the mundane process of adding domains to Burp Enterprise. The initial PoC got us closer to that goal, although it still proved to be too burdensome to use. To fix that, we had to add some functionality and change some existing features. We then had to move away from relying on IaC and pivot to using cloud inventories. Then we decided to be more ambitious and change the system into a complete attack surface inventory.
During this project we have learned a lot about our infrastructure. Knowledge about the attack surface is held in as many parts as the people who have created it. Consolidating that information into one place gives us a great ability to detect weak points and anomalies. Perhaps the weakest points of our attack surface were the ones that we knew the least about. Sites created years ago now lay abandoned, as their creators moved on to new projects. The older a system is, the less likely it is to be using recent solutions, like IaC or even the Cloud, and the more likely it is to not be maintained. Long forgotten, and with little detectable evidence of their existence, these systems still churn away, waiting to serve users and attackers alike. The things we need to see the most are the best hidden.
With every iteration we not only added new features, but also changed and undone some things we already spent time working on. This may seem like a waste of time, but in practice, almost every process works this way. When the process is started, the way to get to the final goal is often not known. We start on a path, and periodically reassess to see if we are getting closer. As we get closer to our goal, we might realize we were slightly off-course and need to correct, or we might even realize that our goal was not as useful as a different goal we are also approaching. We should be ready to adapt during the project to deliver the best thing we can, even if it is different from our initial goal. When I feel stuck on a project, I find it helpful to simply start doing anything, and oftentimes that work will produce information that helps me find a good direction for the next step.





