
This year Mercari attended Berlin Buzzwords 2023 where Ryan Ginstrom and Teo Narboneta Zosa of the Search team shared how we successfully established our search ML infrastructure in their talk, Building MLOps Infrastructure at Japan’s Largest C2C E-Commerce Site (Slides).
Berlin Buzzwords is the world’s preeminent search conference focused on modern data infrastructure, search, and machine learning powering other major tech companies across the globe. The Plain Schwarz conference organizers put on a fantastic 2023 edition (special thanks to Sven, Paul, and the rest of the team for one of the most pleasant conference experiences to date!) and we were honored for the opportunity to share with the rest of the industry the practical and battle-tested insights gleaned from our journey.
This blog post summarizes the talk while providing a comprehensive overview of the connections and intersections between Mercari’s ongoing journey integrating AI and the other exciting discussions at Berlin Buzzwords 2023. At the end of the article, we’ll review our key takeaways and briefly peek at where we’re heading next.
The talk itself consists of the following sections:
- Problem: Integrating Machine Learning (ML) Into a Traditional Term-based Search Architecture
- MLOps: Why & How
- ML Model Serving
- ML Model Monitoring
Integrating ML Into a Traditional Term-based Search Architecture
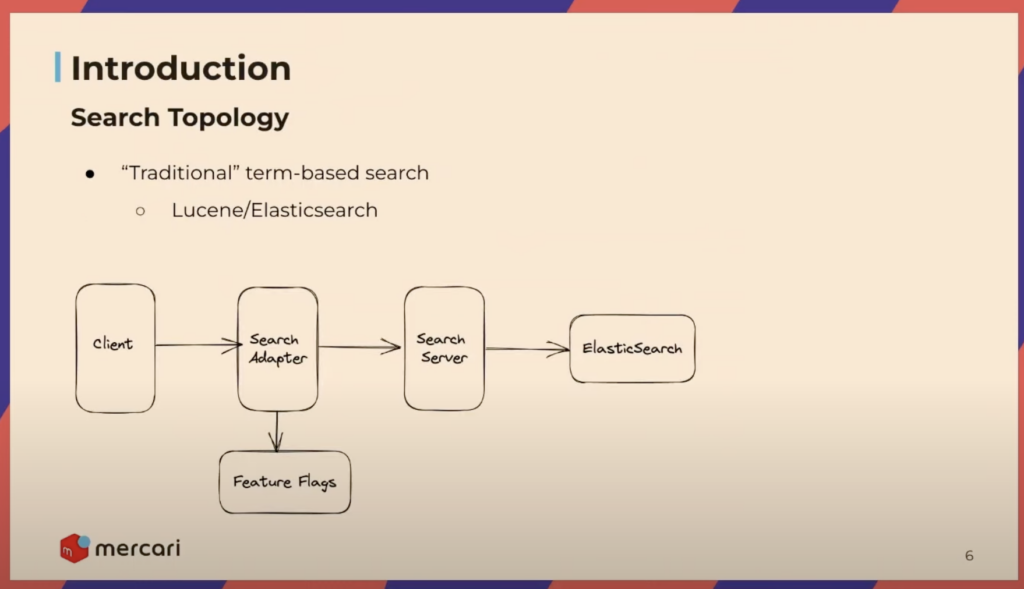
Mercari started in 2013 with a ‘traditional’ term-based search system, which was effective for nearly a decade. However, with recent advancements in AI, we knew we could deliver a significantly better search experience to our users by making AI a primary focus area. Before the introduction of AI in 2022, our search system, based on Elasticsearch, initially leveraged mostly basic tuning, synonym matching, and rules-based filtering of search results.
There were many fantastic talks at Buzzwords 2023 covering the major search engines, from the classic contenders Elasticsearch and Solr to more recent challengers to the space like Vespa.
For the Elasticsearch folks, Uwe Schindler and Charlie Hull gave a talk, "What’s coming next with Apache Lucene?" where they outlined exciting features, such as native support for vector search and various performance improvements.
On the Solr side of the search engine world, Jason Gerlowski’s talk, "A Fresh Start? The Path Toward Apache Solr’s v2 API" detailed Solr’s path forward modernizing its HTTP APIs and associated clients.
Buzzwords 2023 also hosted a panel discussion of search engine and vector search experts to discuss and contrast search technologies with speakers from ElasticSearch, Vespa, Apache Solr, Weaviate, and Qdrant in "Berlin Buzzwords 2023: The Debate Returns (with more vectors): Which Search Engine?"
If you are interested in reading more about the use of Kubernetes and Elasticsearch at Mercari, @mrkm4ntr wrote a detailed article about the Search Infrastructure team’s journey optimizing resource consumption of our Elasticsearch Kubernetes deployments:
Jul.13,2023
Implementing Elasticsearch CPU usage based auto scaling

While simple and reliable, the system was not designed in a way that could easily incorporate ML methods. Mercari also handles a massive amount of search traffic serving our over 20 million monthly active users, making extreme, sweeping change difficult. For instance, we didn’t have the option of completely replacing our underlying search engine with one that easily supports AI-enhanced search (e.g., Vespa). The most significant challenge to our ambition of upgrading our search system was doing so iteratively to ensure the user search experience was always strictly better at each stage.
For a great example of how Vespa shines inside & outside of search, take a look at the blog post, "Adopting the Vespa search engine for serving personalized second-hand fashion recommendations at Vinted" from our good friends at Vinted, Aleksas Keteiva and Dainius Jocas.
To address these technical and business constraints, we saw an opportunity to start with "learning to rank" (LTR) as the first entry point for integrating AI in our search system, leveraging AI to re-rank the search results retrieved by Elasticsearch. This approach could easily integrate with the existing system and was thus the first step toward our incremental path forward.
Alexander Zagniotov and Richard Calland of the Search team previously wrote in-depth on our journey developing Mercari’s pioneering LTR models, including the challenges faced by Mercari and the industry in general.
Jan.1,2023The Journey to Machine-Learned Re-ranking
MLOps: Why & How

MLOps is the application of DevOps principles to ML deployment, involving the tasks required to deploy ML models into production consistently. There is no one-size-fits-all solution, but common patterns and themes have emerged that can help guide ML application development.
Our guiding principle was focusing on the feature first and the software second. We chose the technologies and approaches that best served those features, not the other way around. We constantly collaborated with other teams, gathering feedback and ensuring we aligned with the broader organizational vision. Hardening a system for production is non-trivial and requires significant expertise and resources. By staying simple and small with our feature improvements at each stage, we were able to satisfy both the technical and business constraints at each juncture, quickly building and continuously extending a resilient, production-ready ML system at scale based on real-world needs to ensure we always delivered the most significant business impact aligned with Mercari’s strategic direction.
For more on the organizational & technical challenges major e-commerce companies face when building scalable search systems and the strategies they use to successfully overcome those challenges, see Khosrow Ebrahimpour of Shopify’s talk, "Highly Available Search at Shopify" as well as Matt Williams of Cookpad’s talk, "Cooking up a new search system: Recipe search at Cookpad."
ML Model Serving
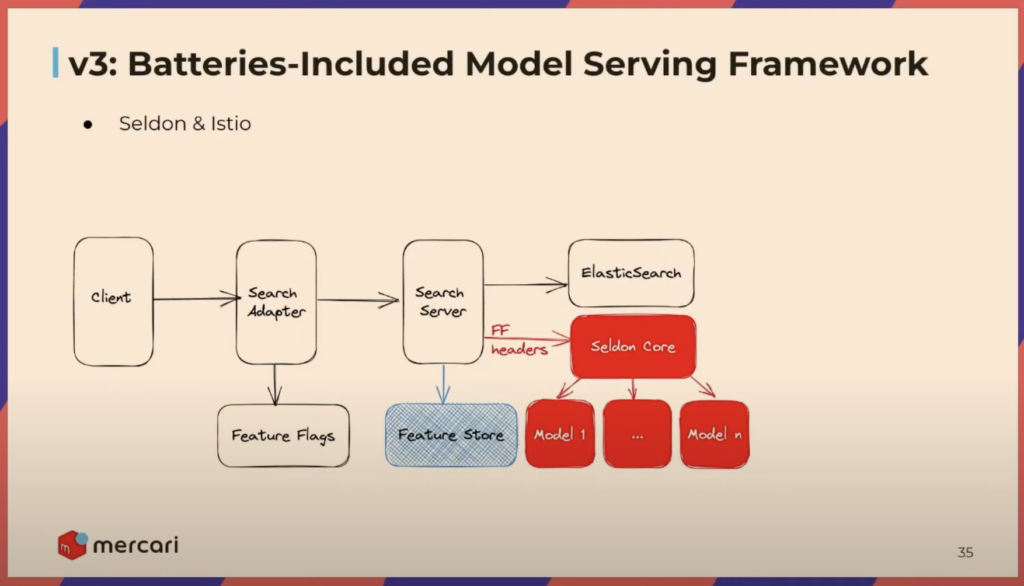
Serving a model is often the trickiest part of production ML systems. We undertook significant development efforts across our search system to create opportunities to incorporate machine learning models.
The initial implementation packaged the model directly within the backend search server. This approach was the simplest possible solution and enabled a quick initial release. However, this approach needed to be more scalable and afford the ability to iterate on new features and model variants frequently. To address this, we decoupled the model from the search server, moving it to a separate prediction service, which enabled faster iteration and the flexibility to choose the most effective tools and frameworks for the job. The final breakthrough solution was leaning on Seldon with Istio, respectively, for model serving and traffic routing, significantly improving development speed and simplifying deployment, ultimately enabling us to overcome our remaining challenges.
While model serving frameworks can make model serving more scalable and performant, a crucial but often overlooked aspect of both model serving and training is the supporting data pipelines and infrastructure that produce the data needed for the models; without data, the models are useless.
- We jump straight to model serving in this article for brevity, but if you’re interested in learning more about our data pipelines at a high-level, please see the data pipelines section of our talk (beginning at 14:51).
- A significant amount of our data infrastructure relies on Apache Airflow, a popular industry-grade data orchestration and management platform. If you’re interested in a practical deep dive, Bhavani Ravi’s talk, "Apache Airflow in Production – Bad vs Best Practices" contains a lot of great advice for leveraging Apache Airflow reliably at scale.
ML Model Monitoring
Finally, model performance monitoring is a critical but underemphasized component of production ML systems. These metrics bolster operational resilience while addressing the limitations of relying solely on "online" business metrics, which are trailing indicators and, in the worst case, aren’t sensitive enough to surface issues at all. We highlight the need for leading indicators to catch performance issues ahead of time to prevent a negative impact on the business’s bottom line. We use Alibi detect, a feature provided by Seldon that monitors model inputs and outputs over time, detecting aberrations such as significant changes in user behavior (implying the model should be retrained to maximize performance) or even more pernicious issues like breaking changes in upstream data sources.
For more on "online" search quality metrics and how they can be used to generate practical insights, Anna Ruggero and Ilaria Petreti gave a talk, "How to Implement Online Search Quality Evaluation with Kibana." They presented how they use Kibana to create visualizations and dashboards to compare different rankers during A/B testing to better gauge models’ projected impact on business KPIs.
Key Takeaway
Our journey highlights the importance of gradually integrating AI into search systems and addressing concrete use cases when operating at scale. While there were significant technical challenges along the way, the primary catalyst for success was choosing the right trade-offs at each stage and prioritizing collaboration across the company to ensure that the AI system aligns with the business goals. To do this, you must balance starting simple while avoiding technical debt and brittle architecture to help pave the way for each successive step forward. Start simple, seek constant feedback, and build the system piece by piece in response to real problems to demonstrate business impact, which ensures you ultimately deliver the right product.
What’s Next?

This has been our journey integrating AI into our search system so far, and we’re just getting started. Moving forward, we are on our way to bringing more advanced AI technologies to our search system, including LLMs, vector search, and hybrid search.
There were many great talks covering LLMs, vector search, and hybrid search at this year’s Buzzwords conference.
- For an example demonstrating the use of LLMs to great effect in search, see Jo Kristian Bergum’s talk, "Boosting Ranking Performance with Minimal Supervision" which outlined how LLMs could be leveraged for synthetic labeled data generation to train in-domain ranking models with minimal human feedback.
- Vector Search has been gaining significant attention and has quickly become one of the most promising technologies in information retrieval. For an excellent overview of how vector search can be integrated with a classic search engine, see Atita Arora’s talk, "Vectorize Your Open Source Search Engine" where Atita demonstrated the usage of bi-encoders to project queries and documents into a latent embedding vector space for nearest neighbor-based similarity search.
- Byron Voorbach from Weaviate shared their exciting journey on both keyword and vector search in their talk, "From keyword to vector" which was a gold mine of valuable, practical tips from hard-earned lessons.
- Roman Grebennikov & Vsevolod Goloviznin gave in our opinion, one of the most simultaneously entertaining and edifying presentations of the conference, "Learning to hybrid search" which was a fantastic overview of hybrid search and demonstrated why it is likely the best choice in practice, especially in an e-commerce context.
Integrating AI into search is a complex process that requires careful planning, collaboration, and consideration. By continuing to invest in these new search technologies at a consistent pace, we are excited to continue unleashing the potential of AI to provide the best search experience for our users!




