This article is a translation of the Japanese article published on December 15th, 2022.
Abstract
- This blog details our research into attacks and mitigations related to supply chain security, and more practical applications of supply chain security. In our research, we took an approach that leveraged a more concretely defined pipeline model than existing frameworks currently in use.
- We examined the effectiveness of each countermeasure related to supply chain security based on the premise that "the point of attack injection does not necessarily coincide with the point of execution". In particular, we clarified the limited effectiveness of recently trending countermeasures such as a software bill of materials (SBOM) which are often adopted without much thought given to their actual efficacy as a solution.
- Based on the results of our threat modeling, we proposed the need for a centralized CI pipeline that takes care of operations related to supply chain security through a single point of entry. A centralized CI pipeline can better enforce security requirements to developers, and replace pipelines where responsibility for security ends up delegated to the individual developers of each component in the pipeline.
I’m Hashimoto Wataru (@smallkirby), an intern working in Mercari’s Security Engineering Team.
In this blog post, I’ll be talking about the main topic of my internship at Mercari—supply chain security. Modern software services use many automated processes (CI/CD pipelines). These processes are continuously triggered throughout the development process all the way from developers writing code, to when the software itself is actually built, released, and deployed. These processes are built upon many dependencies both internal and external. Due to these dependencies, supply chain attacks can both directly and indirectly target each step of the pipeline. The number of supply chain attacks has been increasing every year, and the severity and impact of these types of attacks is becoming greater.
Mercari uses a large number of services and various CI/CD tools that have many dependencies, and is by no means immune to these kinds of attacks.
In April 2021, [Mercari was directly affected](https://about.mercari.com/en/press/news/ articles/20210521_incident_report/) by such an incident due to the compromise of an external code coverage tool included in our CI/CD pipeline. As a result of this incident, we decided to review the security risks related to our supply chain and improve security measures in this area.
Review and re-evaluation of supply chain
In response to these threats, various communities have proposed frameworks that summarize the requirements for securing the supply chain. Some well-known examples include SLSA which was launched by members from Google and the Linux Foundation, and the CIS Software Supply Chain Security Guide which was jointly published by Aqua Security and CIS. These requirements can be applied at each stage of the CI/CD model that many companies have adopted. SLSA in particular categorizes requirements in four security levels that can be applied step-by-step to products.
However, since these frameworks are relatively new, there has been little accumulating experience applying them to production environments. For example, SLSA is currently in alpha status and needs more discussion in regards to some requirements.
In order to apply these frameworks to improve Mercari’s supply chain security, we need to evaluate the following points:
- Whether the CI/CD pipeline model assumed in SLSA and others is applicable to Mercari’s pipeline
- Whether these frameworks enumerate all possible attack methods, and if the proposed requirements can prevent all possible attack methods or not.
- How can these requirements be applied to the pipeline.
In particular, it is important to evaluate which policies can act as a defense against which type of attacks.
If you simply rely on a framework such as SLSA or CIS, you may misunderstand which requirements are effective and to what extent against which attacks. You might assume that any given countermeasure can be a silver bullet, but with supply chain security that is far from the case and no single control can provide complete effectiveness for the entire supply-chain. We need to understand the countermeasures, since each countermeasure is just an individual component of what should be part of a multi-layered security approach. We believe that it is necessary to first identify all possible attacks, and then to identify what a given countermeasure can and can’t do against these attacks, as well as the scope and extent of its effectiveness.
In this blog, we will first reassess the attack methods in each component of CI/CD. Then, we will re-evaluate mitigations against these attacks. Finally, we will provide an example design of a centralized CI pipeline, which adopts these mitigations and separates their management from the developers.
Model of modern typical CI/CD pipeline
Here is a recent example of a typical CI/CD pipeline where DevOps has been widely adopted:
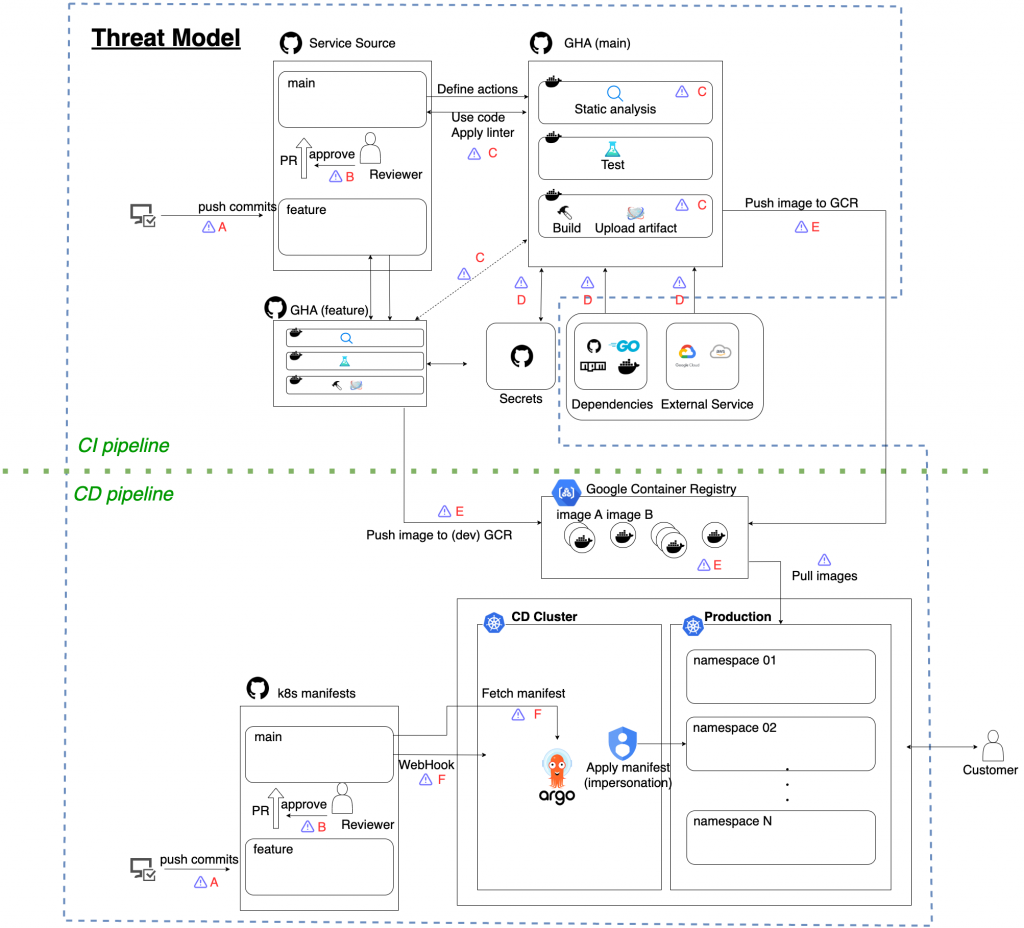
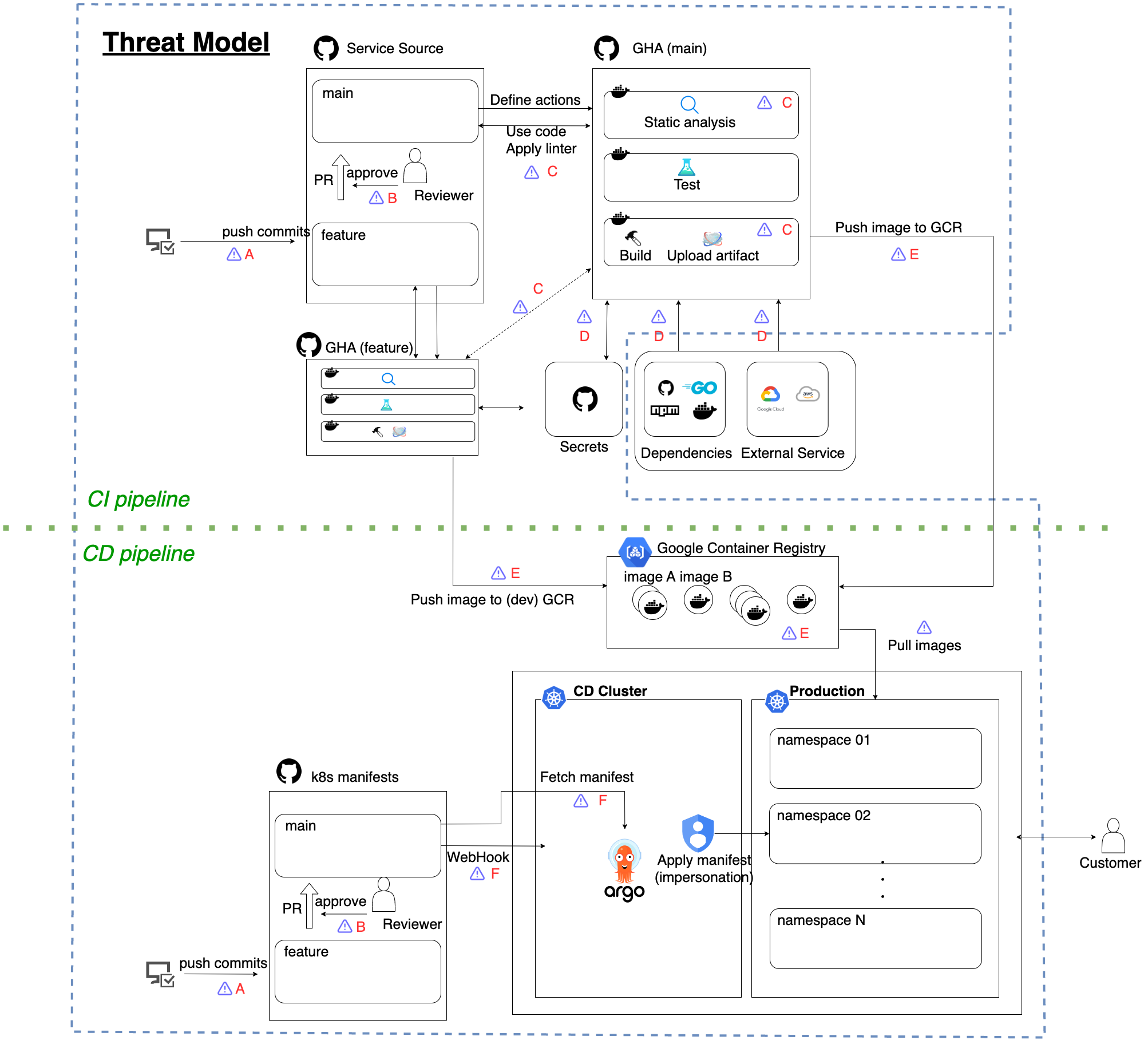
In this model, GitHub is used as a code repository, GitHub Actions is used as a CI phase, GCR(Google Container Registry) as container registry and ArgoCD running on Kubernetes (GKE etc.) as a CD environment. However, the software used in the figure is just an example. The following threat model and mitigation would apply to almost all components, even if you use different software (e.g. GitLab for the code repository, CircleCI for the CI phase, etc).
Attack injection point versus attack execution point
In the following chapter we will summarize the available attack methods in the threat model and their respective mitigations. As a note, indexes such as [A] in the figure are identifiers of components in the pipeline, and we will group attack methods and mitigations by these components.
A supply chain consists of many components, so the point where malicious code is injected and the point where it is executed are not always the same.
For example, suppose that an attacker steals credentials to write to Container Registry and pushes a malicious image from outside the pipeline. In this case the injection point would be Container Registry, and the execution point is the Kubernetes cluster, where the image is deployed to.
As defending against supply chain attacks should be multi-layered in nature, it is important to not only detect attacks at the injection point, but also to detect attacks while the process is still in-flight and to make sure attacks are not present in the final artifact created by the pipeline. In the description that follows, we will point out the points of injection and execution, as well as ways to both to avoid attack injection and to trace the attacks themselves.
Supply chain attacks and mitigations
We summarized a threat model in this PDF for each component in the pipeline model described above. In the following section we will discuss the details of notable attack methods and mitigations.
Summary of threat model
In the following sections, we will focus on notable attacks and mitigations. Each attack method is grouped by its related component in the pipeline model. Note that the following components are just an overview, and the details are described in this PDF.
CLICK to show the summary of the threat model:
The following threat model assumes a typical modern development flow. For example, it assumes that the source code is managed by a SCM, and CI is not run on the developer’s terminal but in an ephemeral environment such as GitHub Actions.
A. Source repository (Commits)
This is the phase between when developers write the source code and when they push it to the source code repository. Note that this is used in both the CI phase (the software code itself) and the CD phase (Kubernetes manifests):
1. An attacker pushes a malicious commit to a feature branch
An attacker compromises an SSH key, a GitHub account, or a developer’s machine and pushes one or more malicious commits to a feature branch.
2. An attacker pushes a malicious commit to the main branch
An attacker compromises an SSH key, a GitHub account, or a developer’s machine and pushes one or more malicious commits to the main branch. This can be done if there are no Branch Protection Rules for the main branch, or if the attacker compromises an account with Admin privileges.
3. Scan of an old repository or branch
An attacker uses stolen tokens with read access to scan old repositories or branches. This can be a threat if the security configurations for the branch or repository are misconfigured, if it contains sensitive information or if the repository has been abandoned but still affects the production environment.
B. Source repository (Review)
This is the phase between when PRs are created and when they are merged to the main branch. Note that compromise of the SCM platform itself is out of the scope of this blog post:
1. Self-Approval by an attacker
An attacker approves their own PRs to bypass the review requirement. Note that GitHub does not allow the PR author to approve their own PR.
2. Approval by compromised accounts
An attacker approves PRs using compromised accounts. Note that GitHub requires the approver to be someone other than the user who created the PR. However, if the attacker is an insider, they can achieve the attack by compromising only one account.
3. Additional commits to approved PRs
An attacker opens a PR with legitimate changes, and gets it approved by a legitimate reviewer. Then, the attacker pushes one or more malicious commits to the approved PR. If the repository doesn’t enable “Dismiss stale pull request approvals when new commits are pushed” in the branch protection rules settings, the attacker can bypass the review requirement.
4. Hidden Backdoor (hard-to-find bug)
An attacker pushes changes that appear to be legitimate but contain a bug that can be exploited when specific conditions are met. If reviewers cannot identify the bug, the changes are approved and merged to the main branch. This is similar to the Hypocrite Commit in the Linux Kernel. Also, this can be applied to automatically generated code (e.g. gRPC blob code, package.lock) that is hard to review.
5. Abusing the review bypass mechanism of the platform
If the SCM platform allows bypassing the review requirement under certain conditions, an attacker can merge malicious code to the main branch while bypassing review requirements.
6. Abusing a bot/app account
If bot/app accounts perform operations on a PR, an attacker may bypass review requirements by abusing the behavior of the bot/app. For example, an app that automatically approves PRs for small changes (e.g. adding documents or fixing typos) can be abused.
7. Changes to review requirements by compromising an Admin account
An attacker compromises an admin account and changes Branch Protection Rules settings to bypass review requirements and merge changes.
C. CI (test, build, CI toolings)
These are the components in the CI phase (like GitHub Actions) on feature/main branches. Note that attacks against the GitHub Actions Runner itself are out of this blog’s scope:
1. Malicious changes on code abusing CI tools
If CI tools such as linters have write access to a repository, and if the commit by the tools do not require review, an attacker can inject malicious code by abusing the CI tools.
2. Use of unintended references
If the CI phase uses external resources as dependencies, and if the reference is mutable (e.g. the reference can be changed by input values), an attacker can use malicious references in Github Actions. Also, the attacker can abuse the Repository Redirection feature of GitHub to make a process access deleted repositories, that have been hijacked by the attacker.
3. Execution of modified GitHub Actions
When a PR modifies the Github Actions workflow file (/.github/workflows/*.yml), the modified workflow file is used to run GitHub Actions on that branch. If the feature branch has been granted inappropriate Secrets or permissions, an attacker can run arbitrary processes by abusing those permissions.
4. Bypassing CI
When static tests are performed in the CI, an attacker can bypass the CI by abusing the special conditions of the SCM platform. For example, in GitHub, the attacker can include [skip ci] in the commit message or include a paths condition in the GitHub Actions workflow file.
5. Malicious inputs for GitHub Actions
GitHub Actions can take branch names, PR comments, etc. as input values. Also, it is possible to call the Git CLI in a Github Actions workflow and get more input values. An attacker could abuse the input values to use unintended references or run malicious processes.
6. Modification of test code
Suppose that the CI phase communicates with external services(e.g. E2E testing using a Cloud Database). In this case, an attacker can push malicious code to the test files to attack related external services or steal secrets.
7. Interaction between CI steps
GitHub Actions runs jobs in parallel, and steps in sequence. If one step passes the result to the next step, an attacker can modify the result and take control of the next step to compromise following steps. Also, if jobs running in parallel can interact with each other, the attacker can control other jobs by abusing the job that is compromised by the attacker.
D. Secrets and dependencies
A phase where dependencies and secrets are used in CI:
1. Theft of environment variables by CI tools
In GitHub Actions you can set a secret and use it as an environment variable within individual steps. If a CI tool (e.g. Linter, Code coverage tool) is compromised, the attacker can steal these secrets. This is similar to the Codecov incident. The risk would be higher if you use same secrets on all branches, and not an OIDC token nor useEnvironments.
2. Secrets with excessive permissions
Suppose that a CI process on a feature branch is granted permissions for the production environment. In this case, an attacker can modify the CI workflow file to use the production environment’s secrets to run malicious processes on production from that feature branch.
3. Use of compromised dependencies
An attacker compromises dependencies and injects malicious code into them, to run malicious processes during the CI phase. The following are some of the patterns that can be used to inject malicious code:
- The attacker compromises the server which distributes artifacts (e.g. base container image, build-time dependencies) and distributes malicious artifacts. If the artifacts are attached with hash values and the hash values can be tampered, the attacker can tamper the hash values to make hash value verification impossible.
- The attacker pushes malicious changes to the source repository of the dependency, and malicious code is built from the artifact. This cannot be prevented by hash verification.
- The attacker injects malicious code to a transitive dependency instead of a direct dependency, This cannot be prevented by hash verification.
- The legitimate dependency owner suddenly turns malicious and injects malicious code to the dependency and builds and publishes the artifact. This is similar to the colors.js and faker.js incident. This cannot be prevented by hash verification.
4. Use of unintended dependencies
An attacker modifies references to dependencies or CI tools to use unintended dependencies.
5. Confidential and sensitive information in the container layers
If secrets are stored in the container layers of artifacts, an attacker can exfiltrate them. In Google Cloud Build, all the files in the workspace are included in the artifact unless they are explicitly specified in .gitignore or .gcloudignore, so it is possible that sensitive information can be included in the build.
E. Container registry(OCI Registry)
This is the phase where the artifacts are pushed to and stored in the Container registry.
1. Pushes to a production registry from a feature branch
If the CI process on a feature branch is granted permissions for the production environment, an attacker can push malicious artifacts to the production registry by modifying the Actions workflow file. Suppose that the CI uses Identity Federation with OIDC to access the registry. If OpenID Connect (e.g. GCP’s Workload Identity) is not configured properly, then the attacker can push malicious images from a CI process on an unintended branch.
2. Pushes of unintended images
If an attacker modifies the Actions workflow file to tamper the build flow, the attacker can push malicious images built in unintended build flow to the registry.
3. Overwrite images in an Container registry using compromised accounts
An attacker can push a malicious image to the registry using a compromised account. The malicious image can be deployed to production during the CD phase.
F. CD process
This is the phase between when the Kubernetes manifests are updated and when they are applied by CD tools such as ArgoCD. This phase heavily depends on the type of software used in the CD pipeline, so we will only introduce a general Threat Model. Note that the changes to the manifests are the same as “A. Source Repository (commit)” and “B. Source Repository (review)”:
1. Malicious sync request using a compromised Webhook
If ArgoCD is configured to not poll for the manifest repository and to use aexplicit Webhook to sync manifests, an attacker can send malicious sync requests using the stolen Webhook secret. If there is no restriction on the branch or tag to sync, the attacker can sync arbitrary versions.
2. Apply manifests to other services in the cluster
If the manifest repository is a monorepo that manages multiple services, an attacker can modify the configuration of other services by modifying the manifests of one service. This can happen when ArgoCD has strong permissions for all services and does not properly impersonate service accounts when deploying. Also, if the repository is not well configured, the attacker can modify the manifests of other services on the source repository.
3. Pull of unintended images
An attacker can modify the image in Kubernetes manifests to make the Kubernetes pull unintended images.
4. Direct operation on Kubernetes using compromised accounts/secrets
An attacker can compromise an admin account to deploy arbitrary services regardless of manifests in the repository.
(The End of Attack Methods)
Summary of Mitigations
For the details of mitigations for each attack method, please refer to this PDF. We list possible mitigations for each attack from the following viewpoints:
- Prevention
- Injection Prevention: which prevents malicious code being injected into the pipeline
- Execution Prevention: which prevents the malicious code being executed
- Impact Reduction: which prevents additional impact after the malicious code has been executed
- Detection: which detects incidents
- Traceability: which tracks the information of components and dependencies in the pipeline
This classification of a mitigation is based on the premise that each individual mitigation does not guarantee "complete" security of the "entire" supply chain. Each mitigation only has a limited effective scope, as described in the "Attack injection point versus attack execution point" section. Only by explicitly identifying which mitigations are effective and in what scope can we determine security requirements that can be applied in practice.
Notable mitigations
In this chapter, we will summarize mitigations against the attack methods by category and introduce their characteristics, what they can do, and the status of related tools.
Attack methods can be roughly classified into two categories:
- Those that compromise and abuse accounts and tokens.
- Those that infiltrate the supply chain by compromising and abusing dependencies.
Many of the mitigations listed below attempt to prevent possible attack execution at the end by ensuring that "the final artifact is the result of following the intended pipeline flow". On the other hand, it is difficult to completely prevent dependency injection, which makes the aspect of “traceability” more important for mitigating against this type of attacks.
Although "attack injection points and execution points can be different" is not emphasized in existing frameworks, it is considered essential to accurately understand the position and effectiveness of each mitigation in order to prepare appropriate mitigations. We hope that you will read the following section while keeping in mind how each of the mitigations are effective against either the injection of the attack or preventing the attacks execution.
Source Repository
The biggest challenge in source code repositories is preventing malicious code from being injected into the repository. This is not limited to public repositories such as OSS, but also applies to private repositories within the company, and it is also necessary to consider attacks from insiders.
In principle, in order for an attacker to push malicious code to a repository, it is necessary to first hijack a developer’s machine, their account, or some kind of key/token. Here are some mitigations to prevent an unauthorized push to a repository:
- Enforcement of Two Factor Authentication (2FA)
- Appropriate configuration of Branch Protection Rules, and enforcing the rules for all accounts, including admins
- Limit the number of admin users
- Enforce commit signing
- Monitor and delete inactive users
If you want to be more restrictive you can also consider network restrictions such as an IP address restriction on the repository. As for 2FA, Branch Protection Rules, and commit signing, you can enforce them by configuring the relevant GitHub settings. For commit signing, you can use Gitsign, which uses a GitHub OIDC token for keyless signing.
Additional mitigations include code reviews in the repository. An Attacker will try to bypass the review itself to inject malicious code. Mitigations for these include the following:
- Enforcement of Two Person Review (branch protection rule / CODEOWNERS)
- Enforcement of Two Factor Authentication (2FA)
One common emphasis in frameworks such as SLSA and CIS is the Two Person Review. You can also configure the repository so that any approval is invalidated if you push additional changes after getting approval. However, this also has an impact on development speed.
Secrets
The CI phase may have secrets such as GITHUB_TOKEN for CI tools to operate on the repository, or secrets for pushing images to container registries or for interacting with other external services. When using static keys, the following points should be noted:
- The principle of least privilege
- Limit the number/access scope of steps which can use secrets
- General mitigations such as the rotation of keys or using short-lived keys(Keyless)
- Network restrictions
In the case of GitHub Actions, the scope of the secret can be configured on a step-by-step basis. However, if a feature branch is attacked and the Github Actions are tampered, those secrets can be exfiltrated by an attacker. In this case, you can use an Environment Secret to limit the secrets that can be used for each branch. You can also configure secrets to require a review by specific reviewers when a Github Actions is changed to use a certain secret.
Using OIDC instead of static secrets can reduce the risk of key leakage. In GitHub, you can access external services such as GCP and AWS with OIDC tokens, and you can make requests to issue a token which is valid only for the duration of the Job.
If you want a stricter policy, you can also consider using egress network restrictions:

In the above figure, all necessary dependencies are installed before the build, and then no network access is allowed during the build. After the build, network access is again allowed when pushing the image to the container registry. This way, we can prevent malicious code (e.g., modified build.rs) from injecting dependencies or leaking build information to the outside, even if it runs during the build process. This can be extended to subsequent steps for testing and running other CI tools. Network restrictions (or allowlisting) in the following steps can reduce the risk of leaking secrets during execution. However, this would be difficult to apply in practice. In fact, it is not possible to restrict the network for each step/job in normal GitHub Actions. If you use self-hosted GitHub Actions on Kubernetes, you can consider using Istio to accomplish this.
Signing
Signature verification is one of the most fundamental and important elements in preventing the execution of attacks in supply chain security. By signing an artifact during the CI phase and verifying the signature when pulling the image from a container registry, it is guaranteed that the entity that signed (i.e., built the artifact) is a trusted entity. If an attacker directly pushes a malicious image to the container registry, the signature of that image will not exist, and the signature verification will fail at deployment, preventing the deployment of malicious images.
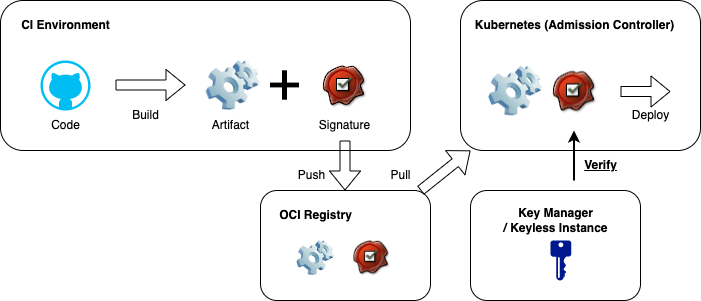
The challenge here is key management. Key management is a very cumbersome process and if possible we would prefer not to do. Sigstore’s cosign can be used for this purpose. Cosign allows you to authenticate using OIDC tokens from Google, GitHub, etc, and sign using a keyless approach. Public and private keys are generated, but the keypair is ephemeral, and the public key can be stored in an Container registry or a Transparency Log managed by Rekor, so there is no need to manage them.
However, due to the public nature of Transparency Logs, which can be viewed by anyone and cannot be deleted or tampered with, it is necessary to set up a private Rekor instance within the organization if you do not want to make your internal activities public. When using a private key management service such as GCP KMS, you can grant permission to use the key for each service or branch by properly configuring Workload Identity. In both cases, you must ensure that only authorized build environments should have access to signing keys.
Verification of Signing
Signing is useless until it is verified at the time of deployment. The cluster must check if the image to be deployed is signed by a trusted entity. If not, the cluster should stop the deployment. One way to implement this is to include an image verification phase in the middle of the CD pipeline, or to use an Admission Controller from Kubernetes to include the verification process.
In the latter case, you can use Sigstore’s Policy Controller. The Policy Controller can define a "policy" which requires that a particular (or all) image(s) must be signed. It can stop the deployment or emit warnings when images violate these policies. By using this kind of tool at the time of deployment, you can verify that the image was pushed from a trusted build environment, and even if a malicious image is pushed to the container registry at some point in the pipeline, it can be prevented from being deployed.
It should be noted that the signature only guarantees that "the image being pulled by Kubernetes is the same one that was built and pushed by a legitimate build environment that has access to the signing key", and does not guarantee at all that the build process itself was executed as intended or that there are no vulnerabilities in the dependencies.
Dependency Tracking
All software depends on third-party packages. It is very difficult to guarantee the security of all the dependencies, and it is therefore very difficult to completely prevent the injection of malicious code when using many dependencies. Therefore, the important point here is to appropriately track dependencies (Traceability).
SBOM (Software Bill of Materials), a trending topic in recent years, is also expected to have some effect in terms of traceability in supply chain security. In the case of JavaScript or Go applications, the files package.lock or go.sum in the source code repository can be used to list the dependencies of the application itself without an SBOM. However, the SBOM differs from these in several ways.
First, it is possible to manage packages in a unified manner even when different package managers are used for different services. This is because an SBOM is not a package-manager-specific format, but a standardized format. In addition, since a given container image is often based on another base image, the base image’s SBOM information can be integrated and included in the final dependency list, if it’s available. If the dependencies including the base image can be explicitly managed in this way, identifying and taking measures against an image with vulnerabilities will be easier.
Generating an SBOM
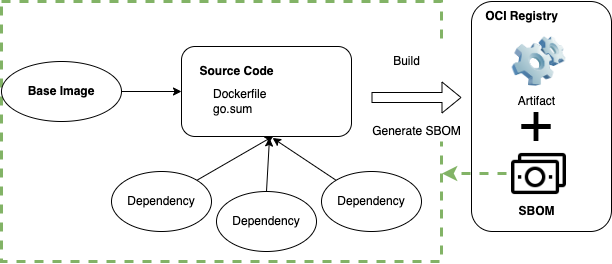
Tools to generate an SBOM seem to be still in development. Currently available tools include ko developed by Google as CNCF sandbox project, and apko developed by Chainguard. ko automatically generates an SBOM for Go applications, while apko can create distroless(-like) container images with an SBOM for any language binaries that have already been built. Trivy, a well known container scanner, also has an option to generate an SBOM.
The SBOM is generated during the CI phase, and then can be pushed to Container registries along with the container images. You can also use cosign to push and sign an SBOM.
The Limitations of an SBOM
First of all, an SBOM is classified as a traceability element in the above-mentioned categories of mitigations. Hence, it cannot be expected to have a significant preventive effect against the injection of vulnerabilities. In combination with attestation (described below), it would be possible to define some policies for the packages listed in an SBOM and to prohibit the usage of dependencies from certain origins. However, it would be basically used to search the list of images that use the dependencies in a unified manner when vulnerabilities are newly found in them.
It should also be noted that, in the first place, there are files that cannot be tracked by an SBOM. When creating an SBOM for container images or when scanning them, the database of the standard package manager used in the operating system is consulted. In the case of single app containers such as Go apps, those DBs can be combined with files such as go.mod to generate a container-wide SBOM. However, if dependencies are installed using commands such as curl or wget in the Dockerfile, it is difficult to track them using an SBOM. In order to get transparency of dependencies all the way back to the base image, we need a way to track such "hidden" packages, but we aren’t aware of any practical tools that can currently do this.
Additionally, even if you can track dependencies with an SBOM, it is another story whether you can evaluate if the dependencies are legitimate or not. Of course, you can verify the signature or attestations of the dependencies using tools such as Cosign and Rekor to ensure that the legitimate builder built the artifact. However, it is not realistic to require all dependencies to follow such a secure flow. When following the root of a dependent package, there will almost always be packages that do not meet the security requirements. It is currently still very difficult to guarantee the validity of such dependencies, but we conclude this section with a list of possible candidates:
- Assured OSS, Google: List of OSS which are continuously built and fuzzed in Google’s secure pipeline. As of August 2022, it provides 250 packages.
- Wolfi, Chainguard: which provides distro-less base images providing an SBOM.
- Security Scorecards, OpenSSF: which scores open source repositories based on security requirements.
Attestation
As mentioned in the "Signing" section, signing itself only guarantees that "the image pulled by Kubernetes has been pushed by a build environment with legitimate access to the signing key". Attestation can be used to tell the consumer/verifier how the image was built, what arguments were passed, and what information it contains.
Attestation is generated separately from the image at build time and (in general) is pushed to a Container registry along with container images. The standard format of attestation/provenance is still under development, but the in-toto format is widely known for now. Attestation identifies the image to be attested by its subject. By attaching an attestation to an image, it is possible to describe how the artifact was created. These attestations can also be signed to ensure that the build environment with legitimate access to the signing key has claimed to have built the image in the flow described in the attestation.
Contents in Attestation
The content that can be included in an attestation is vast and can contain practically anything. For example, an attestation can have an SBOM using Cosign:
$ cosign attach sbom –k8s-keychain –sbom $SBOM $IMAGEIt is also possible to attach the result of a container vulnerability scan. Cosign defines a Generic Predicate Specification as a predicate type other than in-toto format. One of them is the vuln predicate type, which describes the scan result. It is easy to attach the scan result generated by Trivy as an attestation to the image:
$ cosign attest --key gcpkms:// --type vuln --predicate trivy.vuln.json $IMAGEAdditionally, you can attach any information you want to the image by using a custom predicate type.
When you attach multiple attestations to an image, each attestation is represented as a layer, and each layer can have a different type and format.
Verification of Attestations
Once an attestation has been created, you can validate the contents of the attestation in the same way as the "Signing" section. Cosign itself has a mechanism that can validate an attestation (This refers to semantic validation of what the attestation says, not validation of the attestation’s signature). Rules can be written in CUE or Rego.
It is also possible to validate the policy with Kubernetes’s Admission Controller during deployment using Policy Controller as described above. As an example, a rule that ensures that an image is signed with a key managed by a specified KMS and that a container scanned by Trivy shows no third-party dependencies vulnerable to CVSS 8.0 or higher, can be written as follows:
apiVersion: policy.sigstore.dev/v1beta1
kind: ClusterImagePolicy
metadata:
name: trivy-scan
spec:
images:
- glob: gcr.io//simple-server*
authorities:
- name: gcp
key:
kms: >-
gcpkms://<KEY>
attestations:
- name: cvss-less-than-8
predicateType: vuln
policy:
type: cue
data: |
predicateType: "cosign.sigstore.dev/attestation/vuln/v1"
predicate: {
scanner: {
uri: =~ "pkg:github/aquasecurity/trivy@.*"
}
}
#Vuln: {
CVSS: {
nvd: {
V3Score: number & <8.0
...
}
}
}
result: {
ArtifactType: "container_image";
Results: [...{
Vulnerabilities: [...#Vuln]
}]
}By combining an attestation and policy validation in this way, it is possible to enforce restrictions on the image build flow and dependencies when deploying. In addition to the above example, if an attestation can contain the information about the Two Person Review and commit signing in GitHub, it may be possible to describe them as policies as well.
Example of a Centralized CI Pipeline
Even if you can build a CI pipeline that meets the above requirements, there are still challenges when operating it internally. That is, if multiple services/applications use their own build systems, it is difficult to enforce the recommended security requirements.
If each service builds its own application/container in GitHub Actions and pushes it to the registry, it is difficult to enforce the attestation format on each service. In the worst case scenario, developers of each service may be able to forge the attestation as if they met the policy by arbitrarily manipulating the attestation (the signature of the attestation is only a guarantee that the attestation was created by a legitimate build system, hence each service can legitimately create an arbitrary attestation).
Therefore, we can consider the following centralized and standardized build system for Go applications:

This pipeline uses Tekton Pipelines as a build system running on Kubernetes. It is probably possible to achieve this with (Self-hosted) GitHub Actions as well, but I chose Tekton as an example due to its compatibility with related toolings.
First, developers of each service perform static tests on the source code in GitHub Actions. However, we provide little to no secrets in each service repository. This reduces the attack surface and minimizes the risk of secret leakage in the case of security holes in areas where developers of each service can operate freely in GitHub Actions. After the test, a build request is sent to Tekton from GitHub. Tekton uses Interceptor to verify the issuer of the request.
After the verification of the request issuer, Tekton executes the tasks in units called Task. Each task has multiple steps, and each step runs in a separate isolated container.
In the first step of the task, all dependencies are downloaded. Then, if necessary, the network is completely (or partially) disconnected and the artifact is built and signed. Next, the container scanner is run against the built image, and the attestation for the result is generated and signed. If necessary, you can also create a custom attestation here. Finally, the generated artifact, attestation, SBOM, and signature are all pushed to the container registry.
It should be noted that Tekton Chains can automatically create an attestation in the in-toto format that meets the requirements of SLSA. Chains automatically detects the push of an image to the registry, and generates an attestation for the Task/Pipeline workflow, and signs it.
In the figure above, it uses a key managed by KMS to sign the image and the attestation, but it is also possible to use Fulcio+Rekor to perform keyless signing.
The above is just an example of a centralized CI pipeline. Of course, when actually implementing this, it is necessary to reconsider a variety of things: whether it covers all of the aforementioned threat models, whether it does not significantly damage developer experience, and whether there are any technical issues during operation. If the developer specifies the Dockerfile as the entry point for building, there is a problem that the operation (installation of dependencies, etc.) in the Dockerfile cannot be traced. Also, on the CD side, it is necessary to add a flow to properly verify the attestation and signatures generated by the CI pipeline described above.
However, the most important thing to emphasize here is the need to prepare an abstraction layer for the CI pipeline that is "Secure By Default" unless developers use it in unintended ways. The steps in the abstraction layer (e.g., generation of attestations and their contents) are secondary, and the abstracted environment itself is important. If necessary, we can add security requirements to the abstraction layer as needed to enforce all services to follow it.
Summary
In this blog, we enumerated various attack methods and mitigations against a concrete pipeline model in order to demonstrate that there is no single perfect measure to ensure supply chain security.
An SBOM is not a silver bullet, and an attestation does not provide an absolute guarantee. Each of these mitigations should be considered to be a single component in a multi-layered defense. That is why it is important to define the necessary requirements clearly and layer your defenses as much as possible. However, this area of research is in its early stages, there are still active discussions, requirements are being reviewed, and related tools are still under development. Therefore, it would be dangerous to blindly trust the proposed frameworks.
It is a necessary and meaningful process to take a fresh look at the pipeline we are using and rethink from the ground up what each of the proposed requirements can and cannot prevent, and how they can be applied and operated in the real world.
Various communities are conducting reviews of supply chain security from their own perspectives. It is our hope that they will complement each other and mutually improve upon each other’s missing perspectives and practicality.
Thank you for reading, if you have any comments or corrections regarding this blog, let us know.
Acknowledgments
This blog was written with the assistance of the Security Engineering team as a product of my security internship at Mercari. In particular, I’m grateful for the support of Hiroki Suezawa (@rung) who provided me with a lot of knowledge in many of the areas covered in this blog.
Also a special thanks to Takashi Yoneuchi (@lmt_swallow) of Flatt Security Inc. who provided us with a great opportunity to discuss overall supply chain security together. Last but not least, thank you to the Mercari CI/CD team who gave me a lot of insight from the perspective of actual operations.




