This post is for Day 12 of Merpay Advent Calendar 2022, brought to you by Rory from the Merpay Payment Platform team.
Introduction
You might have noticed that we recently released Mercard for all of our customers. This was a great team achievement, but we also launched a range of other features at the same time to help promote its usage. One of these is what we call “Actionable History”.
Actionable History is a customers’ payment history that provides (you guessed it) actionable information for the customer to take. For example, should you make a payment with your Mercard, the payment will show up in your history and provide you with the opportunity to make the repayment for each transaction, whenever is convenient for you.
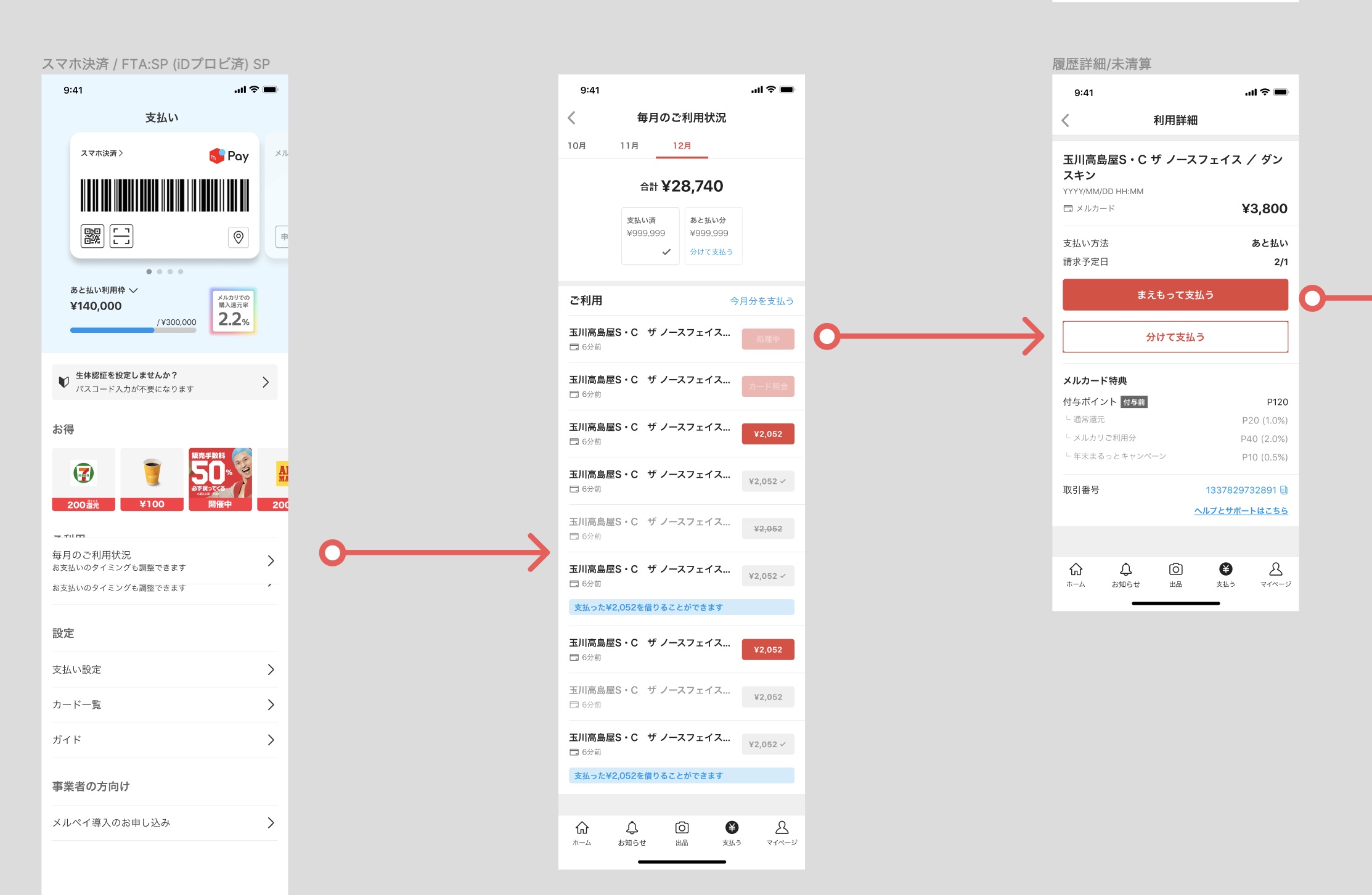
This provides more flexibility for our customers regarding their repayment schedule, and also helps provide more transparency for our customers regarding the payments they have made. Sounds like a win for everyone! This can’t be that hard to build, surely?
So, how to approach this technically?
When we think about showing payment history, often this is purely a static set of data that doesn’t provide any significant CTA (call-to-action). From a technical standpoint, this would typically mean that the largest technical challenge is to optimize for database read performance.
However, providing the convenience of quick repayments places a new technical constraint on our system – we need to be able to process, update and reflect state changes in payment events, without the customer navigating away from the screen. There’s also another latency requirement in that we want all payments to show up quickly (read: within a few seconds) after the payment itself is made. If a customer makes a large purchase with Merpay, and it takes >30 seconds to process, that could be a really poor experience. “Was the payment successful?”, “Should I try again?”, “Did I do something wrong?” would all be valid thoughts here, and all would reduce the trustworthiness of our platform. When dealing with customer money, that’s a no-go.
First and foremost, we need to be able to access payment data for our customers in order to be able to present it. In Mercari / Merpay, we widely adopt a microservice architecture (this has been discussed in many other posts, so I won’t elaborate here). Our services communicate via gRPC for synchronous requests, and Google Cloud Pub/Sub for asynchronous message passing. The data we require comes from a variety of different sources, so it makes sense to collect this data via asynchronous messaging.
It would then be sensible to assume that we receive all of this data from our sources, throw it into a database, and then return it from a gRPC request, right?
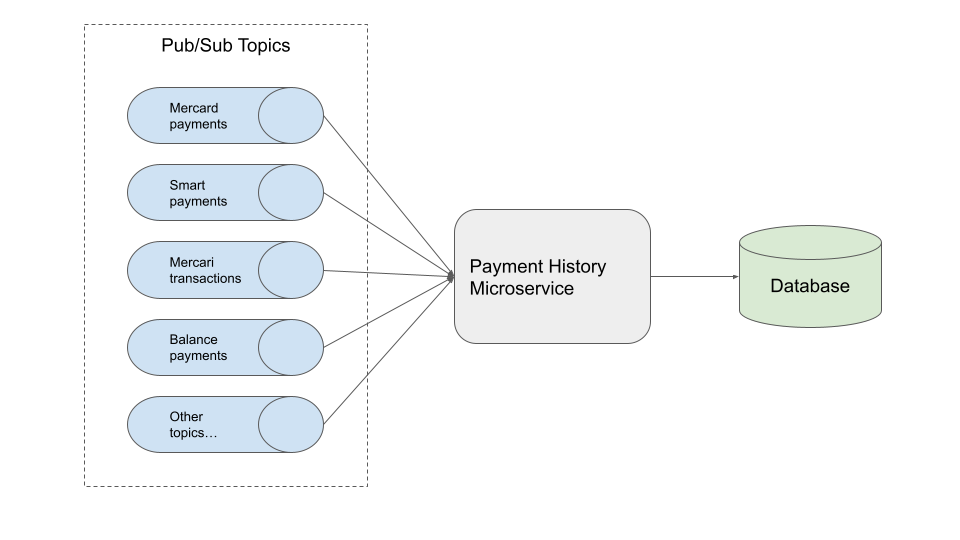
Ah, dear reader… I, too, yearn for a world where technical problems require only simple solutions. The eagle-eyed among you will notice that many of these transaction types are not mutually exclusive. The Mercard is a credit card, after all, and thus can be classified as a deferred payment. You may have even used Mercard to purchase something on Mercari, and so there are (at least three) different areas of this transaction. I regret to say this is still a rather large simplification.
So, there is a natural linking between related payment types, which presents another challenge: What if one event is received before another unexpectedly? What if we receive a Mercard payment which claims to be for a Mercari item, but we haven’t yet received any information on the Mercari purchase itself?
Yes – The natural order of received events matters. If this were a conference talk, I would leave a dramatic pause at this point, to allow time for gasps from the audience.
A hierarchy of events
This means that the events that we receive must fall into a certain hierarchy in order for us to be able to process them correctly. This naturally forms a tree structure. For this, we need a way to be able to control the flow of events, and be able to place events into a “temporary storage” in the situation that we are waiting on some follow up information.
One question you may have here is “why can’t you store partial data in the database, and just immediately accept all events”? Which is a great observation, and certainly a goal to strive towards. However, let’s consider each event received as a state transition for a payment; if we allow all events at any time to be received and processed, the number of state transitions for a payment explodes exponentially. It would most likely result in fried developers, fried servers and sad customers. So, we enforce a common path for each transaction type. That is, we should accept payments to be received in a certain order. Next, we need to find a way to achieve this technically.
Nack nack, who’s there?
The solution to this is to process all events that we receive into a common mold, and put these into another message queue which allows us to control the order of the events.
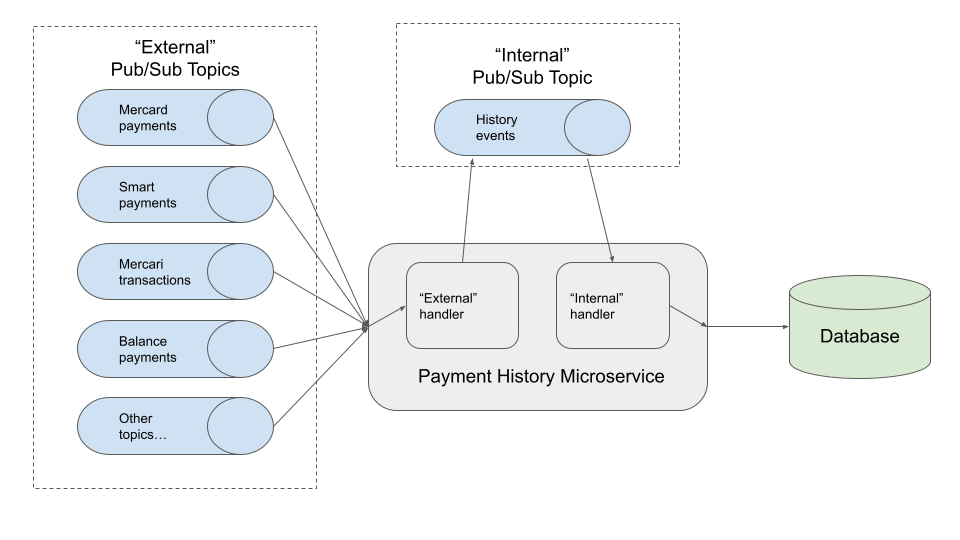
By using an internal message queue, this provides us with an opportunity to be able to acknowledge an event negatively (otherwise known as “nack”), to put a message back into the queue if we are not ready to process the event.
This provides us with the ability to delay processing of certain messages while we wait for others to be received. Often, this takes place over the course of milliseconds, and so does not provide a significant amount of latency for our customers.
This is all well and good, and seemingly provides us more control over processing historical payment data, but after some time (and much confusion) we learned of the following rules:
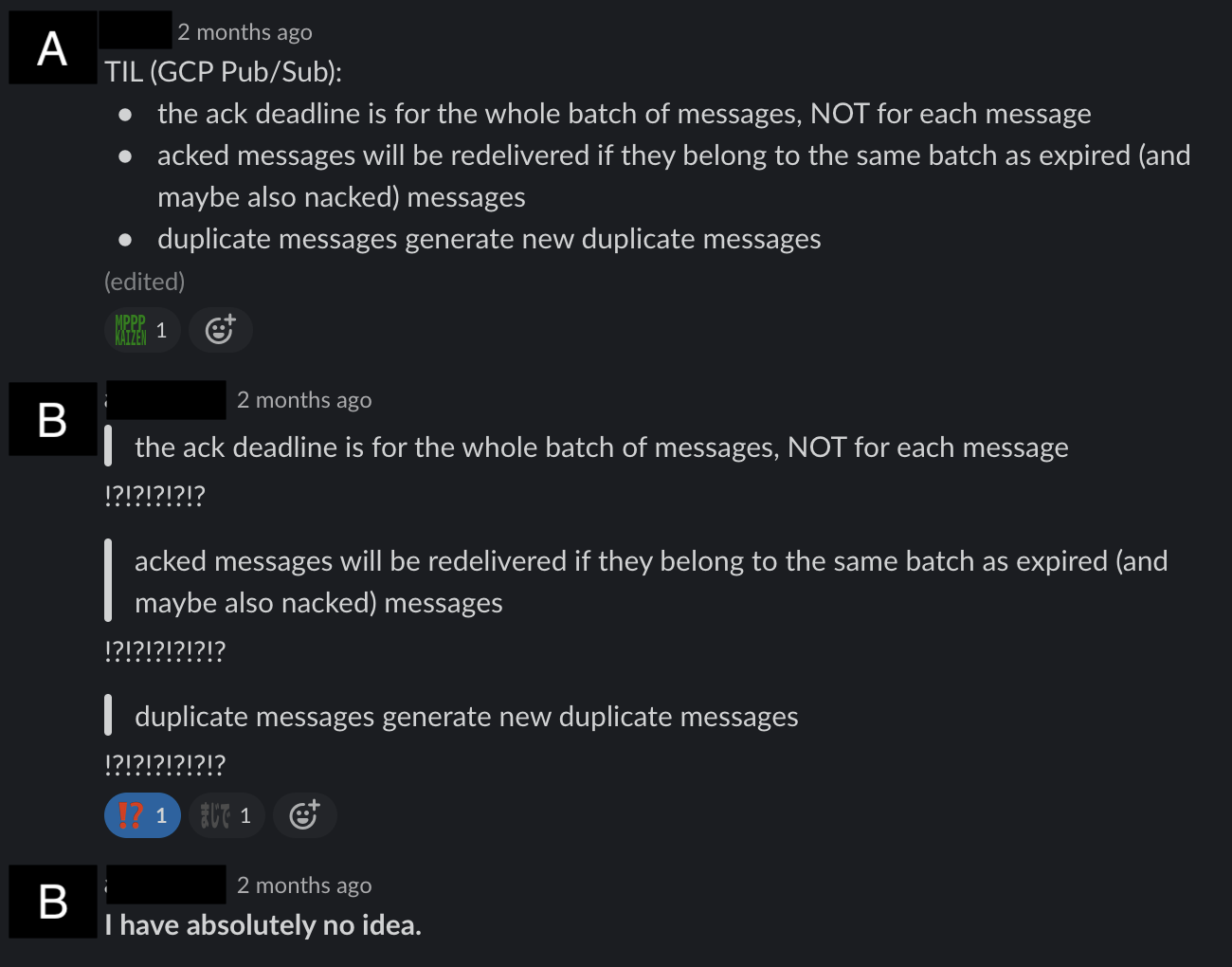
The text from the image reads:
- The ack deadline is for the whole batch of messages, NOT for each message.
- Acked messages will be redelivered if they belong to the same batch as expired (and maybe also nacked) messages
- Duplicate messages generate new duplicate messages.
To me, at least, this reads a little bit like a religious commandment, or an old English legal text:
“Thou shalt respect the delivery decrees of Pub/Sub”
Fundamentally, for a service which depends on the ability to nack messages in order to be able to deterministically process events in a given order, this has the potential to cause a lot of trouble with our message processing latency due to the generated duplicates from Pub/Sub.
For example, let’s assume that we consume messages in a batch of 10, with a 10% likelihood of nacking a single message in a batch. This would mean that on average, 10% of events are redelivered, with 9% being duplicates (as being part of a nacked batch). Then, if we need to process 1 million messages in 1 hour, then actually 100,000 of these will be retried and will fill the queue even further!
Thankfully, across Merpay we heavily utilize idempotency across our services, so duplicate messages will be acknowledged and discarded without issue, but the largest negative side effect of this is that our Pub/Sub queue can easily become “backfilled” with duplicate messages.
At this point in the article, it would be fantastic to say that we found a silver bullet solution, and everything was resolved without issue. But, in the real world I can only say that our solution to this involved taking a really deep dive into our use case, tweaking Pub/Sub configurations, tweaking Kubernetes configurations, and staring at monitoring dashboards for long periods of time. We have, however, reached a state with the service where we are currently happy with the performance, and our customers can rely on us to show us their payment history data in a timely manner.
What did we learn?
I’m certainly proud of what we’ve been able to achieve with the history service, but there’s a few things that I would tell myself, if I could go back in time and provide some advice to past-me. These would be:
- If you are using an API in a slightly non-standard way (for example, leaning on the nack functionality of Pub/Sub), do thorough research to ensure that this won’t cause trouble further down the road.
- It’s not necessarily a bad thing to bend the rules of what you can achieve with the tools you are given, but this does mean that more background research is required!
- Furthermore, it can be valuable to plan alternate technical architectures in case larger blockers emerge (thankfully not required from us this time!).
- When designing a new service, try to walk through the most common customer journeys / request patterns first. How will the service interact with dependencies? What will be the hottest database tables and columns? What kind of back-of-envelope estimate can we provide for latency at this point in time?
- The payment history service is a platform service after all, and therefore is quite deep into our service map. Even so, understanding the customer journeys and use-cases can provide really useful insights in terms of designing a performant and stable service.
- Utilize your cloud service provider support technicians! We had some really productive conversations with GCP support which greatly helped us improve our service performance, but we definitely could have had these conversations even sooner.
What’s next?
As an immediate (and concrete) next action, we were thrilled to find out that GCP have recently made “exactly-once delivery” generally available for Pub/Sub. We’ll definitely be investigating this as a possible future performance improvement!
On a more long-term scale, as is the case with any kind of service development, the goalposts are always a moving target. Therefore, we always have new features, improvements and bug-fixes that we are working on. We’re proud of working on this small piece of Merpay functionality and we hope that you enjoy using it.
Tomorrow’s article will be by 1000ch. We hope that you are looking forward to it!



