This post is for Day 11 of Merpay Advent Calendar 2022, brought to you by @resotto from the Payment Platform Balance team.
The purpose of this post
Basically, knowledge sharing is to share knowledge acquired by someone with others. In business, acquiring knowledge faster is crucial for us to create something, gain profit, solve problems, obey the law/guidelines and work smart.
Generally speaking, knowledge sharing problems should mean the situation where someone who hasn’t known one specific knowledge suffers a loss. In the context of software engineering, the problems can be more granular than it.
In this post, I’d like to show what we did for knowledge sharing problems but they might also be applicable not only to software engineering but also to other areas.
The purpose of this post is to give readers an opportunity to think about knowledge sharing problems.
Notice: In this post, the term knowledge equals knowledge of a domain in the context of Domain-Driven Design.
Why I started thinking about knowledge sharing
Merpay Balance team has two major problems about knowledge sharing:
- Since team members have usually asked questions to someone who knows the knowledge well, knowledge has depended on the person.
- There is a psychological barrier to responding to inquiries or incidents for the system which is “black box” for someone.
The psychological barrier was found as a result of discussions in a team retrospective where all members agreed with the difficulty of fixing and/or maintaining the “black box” systems.
Additionally, some members have left our team and some members have joined our team recently.
So, the above problems have become more serious for our team.
That’s why I started thinking about a way to improve the team knowledge sharing mechanism.
Status Quo
Let me summarize the current situation of our team in terms of knowledge sharing here.
- Certain team members have less knowledge about APIs and/or functions which they haven’t engaged at all than others.
- Members have created and/or updated documents at any given time except for ones required for projects like Design Doc.
- Team members think the current situation isn’t too bad since the number of documents isn’t low and there aren’t many outdated documents.
We haven’t had any specific urgent/critical problems for knowledge sharing. However, when we considered the risks of the situation where nobody in our team can handle any incidents at any time, team members also started thinking about the problem more seriously and voluntary members launched a small community for the problem.
The following contents are the result of discussions in the community.
Analysis of the problem
At first, the members of the community considered the following topics:
- What kinds of ways of acquiring knowledge exist and their characteristics?
- Where do knowledge sharing problems exist?
I’ll explain them respectively.
What kinds of ways of acquiring knowledge exist and their characteristics?
We can acquire knowledge by different means. Here are the ones we discussed.
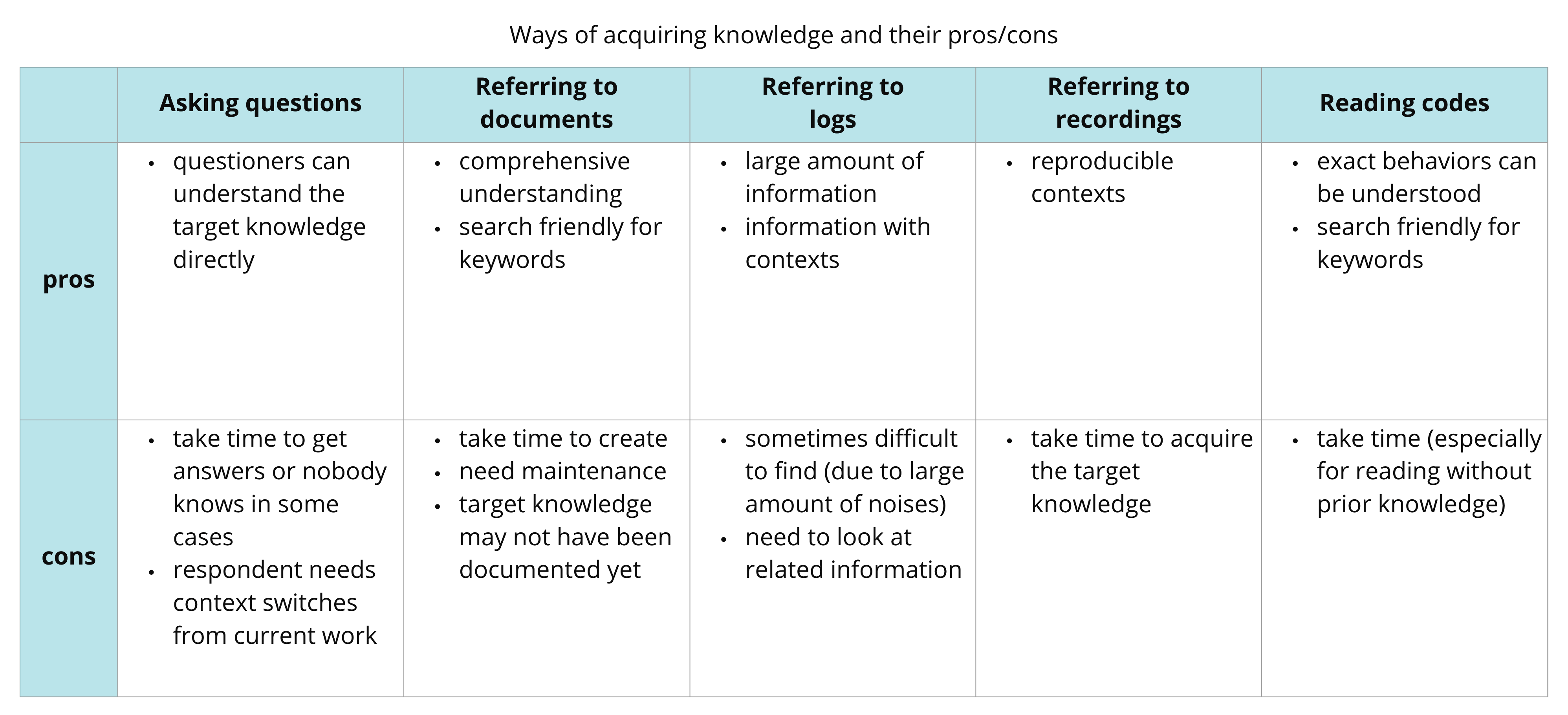
Before jumping into those details, let me clarify the difference between “documents” and “logs”.
- “documents” means organized knowledge
- “logs” means unorganized knowledge such as meeting minutes, Slack posts etc…
The most straightforward way is asking questions. Respondents of each question should execute a context switch from their current work.
Documents always help us. It’s also easy to search by keywords but it takes time to create/maintain them. Unless we create it, we can’t refer to it.
Slack messages are like treasures of information (meeting minutes as well). It complements documents a lot. Though it’s helpful, we need to identify the target knowledge from noises.
I check the recordings of meetings to review the exact contexts that happened in the meeting. If someone who didn’t attend the meeting tries to check something, it would require more time.
Lastly, reading application codes is a good (or the best) way to acquire knowledge. Code comments help us to understand the behavior quickly. If test codes are written as Test-Driven Development, reading each test case is also helpful. The more prior knowledge we have, the faster we can read codes.
Where do knowledge sharing problems exist?
Next, we discussed our actual inquiry / incident handling process. There have been two patterns for it in our team.
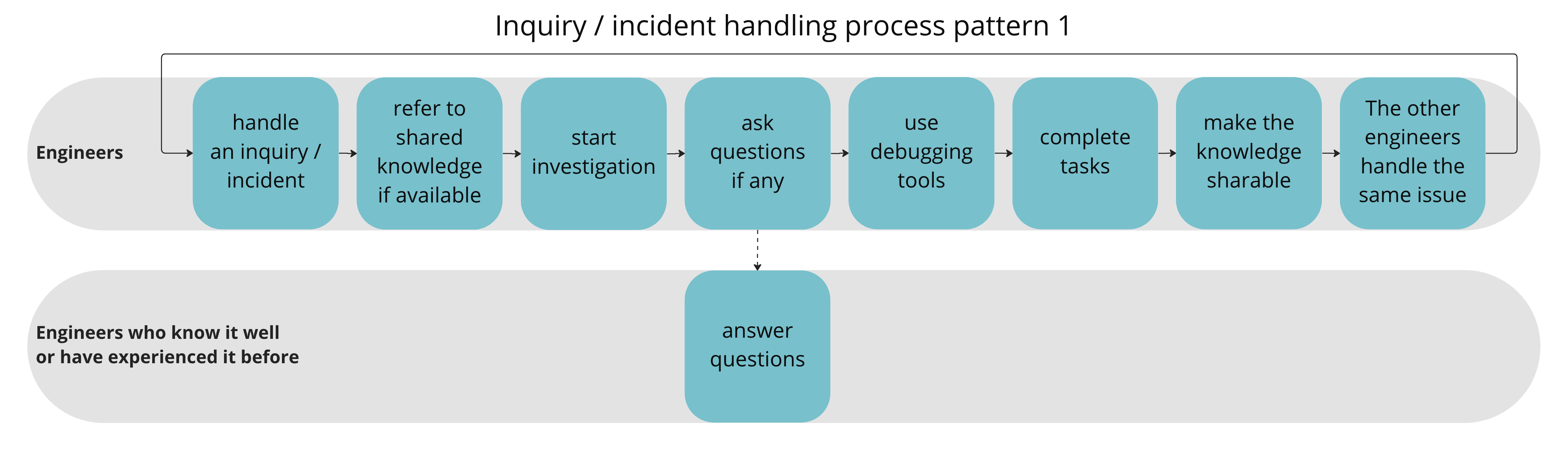
The above pattern is the one where the responder keeps investigations and completes the tasks.
This process is ideal since the knowledge required to complete the tasks should be shared afterwards. Unfortunately, we think intuitively this pattern has accounted for only 30% of the total. The rest is pattern 2 below.
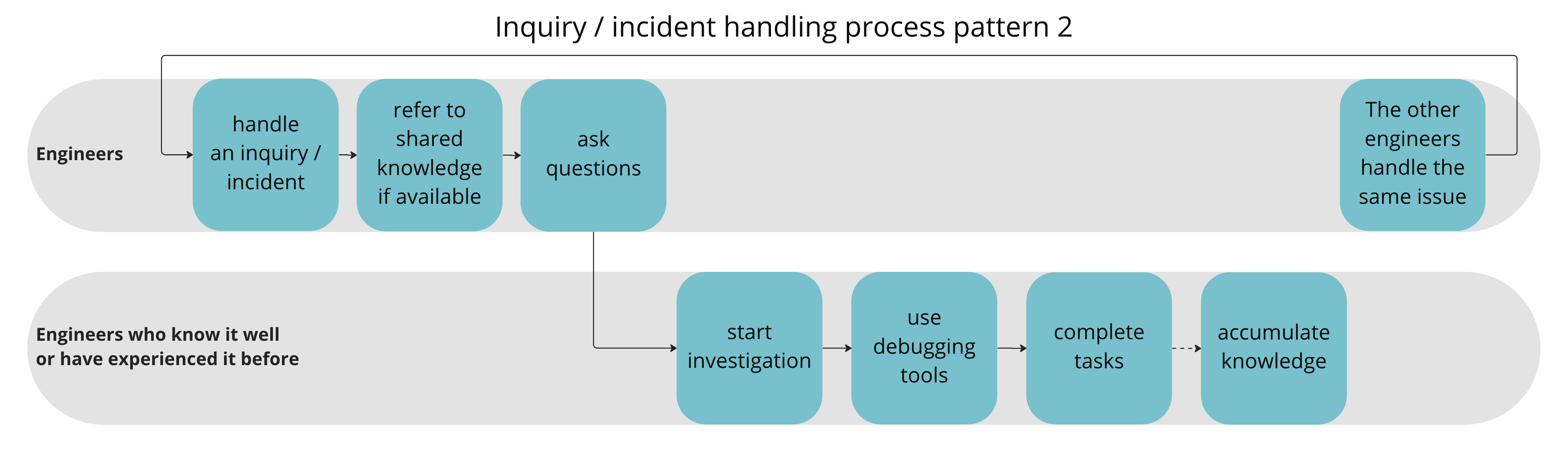
In this pattern, the responder delegates tasks to someone who knows it well or has experienced it before.
If we need to investigate something in detail, this pattern usually emerges consequently.
After visualizing each step of inquiry / incident handling processes, we discussed where knowledge sharing problems exist with the figures.
The following two figures extract each step of the upper layer in pattern 1 and each step of the lower layer in pattern 2 separately.
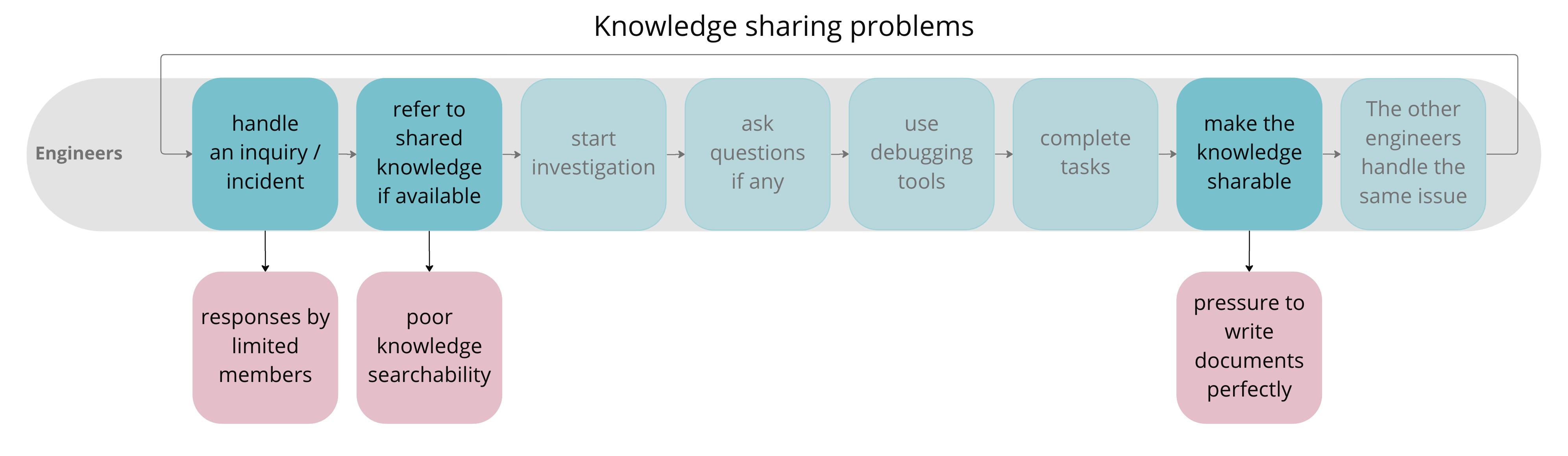
For some steps of the upper layer in pattern 1, we identified three knowledge sharing problems.
- Only limited members can respond to inquiries / incidents.
- Knowledge couldn’t be found properly.
- There is pressure to write documents perfectly.
We also identified that not being good at utilizing debugging tools contributes to the psychological barrier to responding to inquiries / incidents. This isn’t directly correlated to knowledge sharing problems but it’s worth keeping in mind.
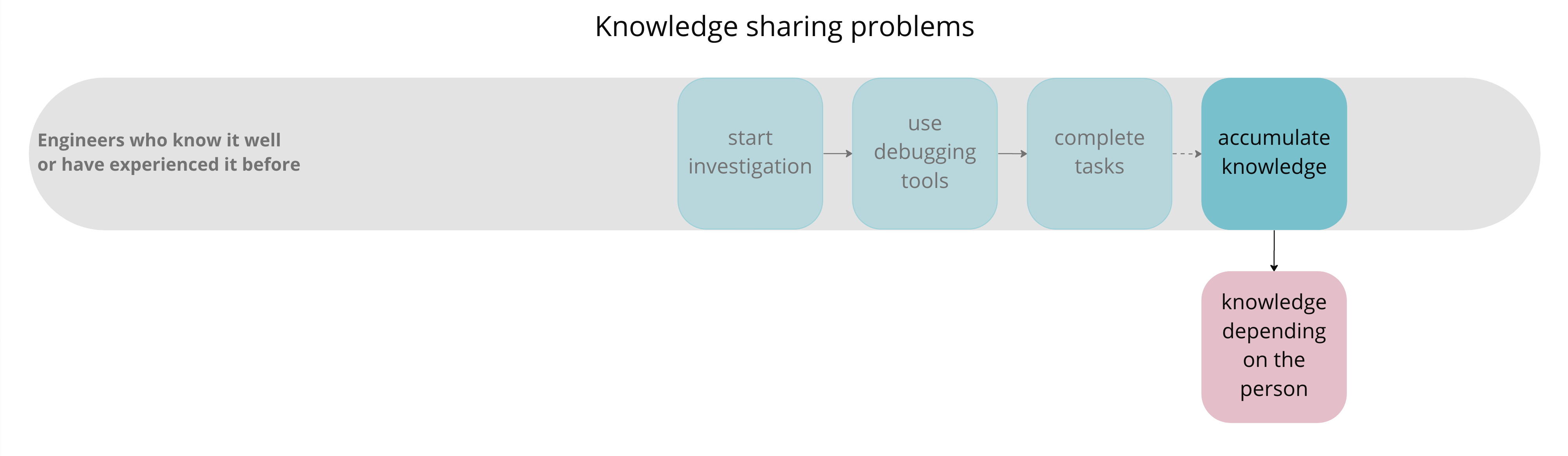
For the lower layer in pattern 2, we identified that the knowledge becomes depending on the person.
Practices
We figured out where knowledge sharing problems exist now. In this section, I’ll explain what we did for those problems.
GitHub issue
First, we introduced the random member assignment mechanism with GitHub issues. With GitHub Actions, we can assign 2 team members randomly when a GitHub issue is created.
We’ve proactively asked someone who will request/report something to our team to create GitHub issues. In addition, we sometimes create GitHub issues by ourselves intentionally when we want to assign members randomly.
We’ve also proceeded with documentations for regular operations and shared their workloads by assigning members randomly (via GitHub issues).
Slack reacji-channeler
I tried one different approach. I created one Slack channel dedicated to knowledge sharing and set a mechanism with Slack reacji-channeler where the specific Slack stamp left on a Slack post will send the post to the channel. Then, I left the stamps to many beneficial Slack posts regardless of where the post exists.
In this way, I collected lots of knowledge into that Slack channel and shared the channel to team members.
When I post some explanations for something or how to resolve a problem, I also leave the Slack stamp on it currently. Team members can check the channel whenever they want to explore beneficial information.
This channel still doesn’t have any solid use cases for knowledge sharing but the culture of leaving the Slack stamp still remains.
Google Doc
I thought we shouldn’t miss the value of existing documents and in fact, there were many documents which I haven’t read yet. So, I tried to list up the main documents, read them one by one and created one large Google Doc including those contents.
As a result, I read 29 documents and the contents of the Google Doc grows up to 32 pages where almost all knowledge shared by documents is covered (in detail!).
I took care of the only one point when creating such a document:
- DON’T STICK TO THE FORMAT
I knew I would read many documents and there should be duplicate and/or crossover knowledge in the middle of reading so I didn’t take care of the format at all. When adding duplicate or crossover knowledge, I searched it first (if possible) and grouped it together loosely.
What I did in terms of its format is just adding Heading 1 section. Those headings separated the contents beautifully. That was enough for the purpose.
Formatting the document would be better only after the content is almost fixed.
One of the useful features of Google Doc is bookmark. I put bookmarks on some topics which can be referred to by multiple places/contexts. Bookmark contributes to connecting related knowledge together in the Google Doc.
Application code
After reading those documents, I understood which knowledge is important. Then, I listed the source files where important knowledge is located and suggested to team members that we should read them together. I also suggested making the memo of their understanding public in the Google Doc.
This pretty worked for us since we could focus on reading self-assigned source files and also understand other knowledge by reading memos created by other members.
Knowledge Index
There is one ongoing practice. That is creating a knowledge index.
Knowledge index has been mentioned in the context of knowledge search. Unless we know the keyword of the knowledge, we can’t search for it. In order to know what kinds of knowledge keywords exist, we keep creating a knowledge index.
We utilize FigJam for creating a knowledge index since knowledge will be added/updated many times and doing them frequently on a document or a spreadsheet can be exhausting.
Knowledge sharing meetup
One of the community members set up the opportunity to ask many questions to the tech lead of our team as a “knowledge sharing meetup”. That direct approach worked much as well.
We’ll keep conducting knowledge sharing meetups. After creating a knowledge index, we can prioritize knowledge and someone who knows it the best can share the knowledge in the meetup.
Next presenter of the meetup is me but I won’t prepare at all. If preparation for the meetup is mandatory, it will be difficult for us to keep them.
I’ll try not to forget recording the meeting and also share the knowledge on the dedicated Google Doc for sure.
We did a lot of countermeasures for knowledge sharing problems. In the next section, let us recap the results of these actions.
Results
The result was more than expected.
- With documents for regular operations, we could share the operation and its knowledge, which has depended on someone before.
- I succeeded at summarizing many beneficial Slack posts into one Slack channel (though its use is under experiment).
- Creating one large Google Doc makes us understand the knowledge comprehensively, search the knowledge easily, and ask questions easily.
Consequently, we found that the Google Doc can be one of knowledge sharing platforms where knowledge converges organically and is shared by someone seamlessly, and anyone can deepen their understanding by leaving/answering questions. That is much more than documentation.
Fabulous!
At the same time, I tried considering the prerequisites of the above results.
Discussion
Disclaimer: These discussions are just my thoughts. I want to discuss this topic in the community later.
I thought there was at least one factor that contributed to the above results. Yes, Psychological safety.
What if one of the team members feels fear, anxiety or rejection when asking questions to other members? These situations would obviously block the acceleration of knowledge sharing.
What if some of the team members don’t share their knowledge which depends on them? Even if we were in this situation, we could proceed with knowledge sharing by creating one Google Doc and summarizing knowledge into it.
Conclusions
Here are conclusions of our knowledge sharing activities.
Documentation is high cost / high scalable
Although creating documents takes time, once we have done it, everybody can catch the knowledge.
Making someone’s memo of understanding public scales
Even if you understand the knowledge partially, making the memo of understanding public and leaving questions on it leads to better understanding of anyone else (and luckily someone may answer it!).
Other members can save time to understand the knowledge by reading the memo so that much time will be saved in total.
The way of sharing knowledge without documentation
Now, we know the scalable way of sharing knowledge with documentation described so far.
We have also explored the way of sharing knowledge without documentation (like collecting beneficial Slack posts into one Slack channel mentioned earlier) and we’ll keep exploring it.
Since there are many beneficial posts in Slack, communication tools and knowledge sharing platforms would be united ideally. Machine learning would contribute to collecting related information and organizing them in a natural way on the tool.
When it comes to reality, most knowledge sharing problems will be solved.
Thanks for reading this post!
Next article will be brought by @rory who is also from the Payment Platform team.
Please check it out!



